 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStabilizing Policy Optimization via Logits Convexity
Mar 01, 2026While reinforcement learning (RL) has been central to the recent success of large language models (LLMs), RL optimization is notoriously unstable, especially when compared to supervised fine-tuning (SFT). In this work, we investigate the stability gap between SFT and RL from a gradient-based perspective, and show that the convexity of the SFT loss with respect to model logits plays a key role in enabling stable training. Our theoretical analysis demonstrates that this property induces favorable gradient directionality during optimization. In contrast, Proximal Policy Optimization (PPO), a widely adopted policy gradient algorithm utilizing a clipped surrogate objective, lacks this stabilizing property. Motivated by this observation, we propose Logits Convex Optimization (LCO), a simple yet effective policy optimization framework that aligns the learned policy with an optimal target derived from the original RL objective, thereby emulating the stabilizing effects of logits-level convexity. Extensive experiments across multiple model families show that our LCO framework consistently improves training stability and outperforms conventional RL methods on a broad range of benchmarks.
DreamVAR: Taming Reinforced Visual Autoregressive Model for High-Fidelity Subject-Driven Image Generation
Jan 30, 2026Recent advances in subject-driven image generation using diffusion models have attracted considerable attention for their remarkable capabilities in producing high-quality images. Nevertheless, the potential of Visual Autoregressive (VAR) models, despite their unified architecture and efficient inference, remains underexplored. In this work, we present DreamVAR, a novel framework for subject-driven image synthesis built upon a VAR model that employs next-scale prediction. Technically, multi-scale features of the reference subject are first extracted by a visual tokenizer. Instead of interleaving these conditional features with target image tokens across scales, our DreamVAR pre-fills the full subject feature sequence prior to predicting target image tokens. This design simplifies autoregressive dependencies and mitigates the train-test discrepancy in multi-scale conditioning scenario within the VAR paradigm. DreamVAR further incorporates reinforcement learning to jointly enhance semantic alignment and subject consistency. Extensive experiments demonstrate that DreamVAR achieves superior appearance preservation compared to leading diffusion-based methods.
FreeInpaint: Tuning-free Prompt Alignment and Visual Rationality Enhancement in Image Inpainting
Dec 24, 2025Text-guided image inpainting endeavors to generate new content within specified regions of images using textual prompts from users. The primary challenge is to accurately align the inpainted areas with the user-provided prompts while maintaining a high degree of visual fidelity. While existing inpainting methods have produced visually convincing results by leveraging the pre-trained text-to-image diffusion models, they still struggle to uphold both prompt alignment and visual rationality simultaneously. In this work, we introduce FreeInpaint, a plug-and-play tuning-free approach that directly optimizes the diffusion latents on the fly during inference to improve the faithfulness of the generated images. Technically, we introduce a prior-guided noise optimization method that steers model attention towards valid inpainting regions by optimizing the initial noise. Furthermore, we meticulously design a composite guidance objective tailored specifically for the inpainting task. This objective efficiently directs the denoising process, enhancing prompt alignment and visual rationality by optimizing intermediate latents at each step. Through extensive experiments involving various inpainting diffusion models and evaluation metrics, we demonstrate the effectiveness and robustness of our proposed FreeInpaint.
Region-Constraint In-Context Generation for Instructional Video Editing
Dec 19, 2025



The In-context generation paradigm recently has demonstrated strong power in instructional image editing with both data efficiency and synthesis quality. Nevertheless, shaping such in-context learning for instruction-based video editing is not trivial. Without specifying editing regions, the results can suffer from the problem of inaccurate editing regions and the token interference between editing and non-editing areas during denoising. To address these, we present ReCo, a new instructional video editing paradigm that novelly delves into constraint modeling between editing and non-editing regions during in-context generation. Technically, ReCo width-wise concatenates source and target video for joint denoising. To calibrate video diffusion learning, ReCo capitalizes on two regularization terms, i.e., latent and attention regularization, conducting on one-step backward denoised latents and attention maps, respectively. The former increases the latent discrepancy of the editing region between source and target videos while reducing that of non-editing areas, emphasizing the modification on editing area and alleviating outside unexpected content generation. The latter suppresses the attention of tokens in the editing region to the tokens in counterpart of the source video, thereby mitigating their interference during novel object generation in target video. Furthermore, we propose a large-scale, high-quality video editing dataset, i.e., ReCo-Data, comprising 500K instruction-video pairs to benefit model training. Extensive experiments conducted on four major instruction-based video editing tasks demonstrate the superiority of our proposal.
Learning More with Less: A Dynamic Dual-Level Down-Sampling Framework for Efficient Policy Optimization
Sep 26, 2025Critic-free methods like GRPO reduce memory demands by estimating advantages from multiple rollouts but tend to converge slowly, as critical learning signals are diluted by an abundance of uninformative samples and tokens. To tackle this challenge, we propose the \textbf{Dynamic Dual-Level Down-Sampling (D$^3$S)} framework that prioritizes the most informative samples and tokens across groups to improve the efficient of policy optimization. D$^3$S operates along two levels: (1) the sample-level, which selects a subset of rollouts to maximize advantage variance ($\text{Var}(A)$). We theoretically proven that this selection is positively correlated with the upper bound of the policy gradient norms, yielding higher policy gradients. (2) the token-level, which prioritizes tokens with a high product of advantage magnitude and policy entropy ($|A_{i,t}|\times H_{i,t}$), focusing updates on tokens where the policy is both uncertain and impactful. Moreover, to prevent overfitting to high-signal data, D$^3$S employs a dynamic down-sampling schedule inspired by curriculum learning. This schedule starts with aggressive down-sampling to accelerate early learning and gradually relaxes to promote robust generalization. Extensive experiments on Qwen2.5 and Llama3.1 demonstrate that integrating D$^3$S into advanced RL algorithms achieves state-of-the-art performance and generalization while requiring \textit{fewer} samples and tokens across diverse reasoning benchmarks. Our code is added in the supplementary materials and will be made publicly available.
WeChat-YATT: A Simple, Scalable and Balanced RLHF Trainer
Aug 11, 2025Reinforcement Learning from Human Feedback (RLHF) has emerged as a prominent paradigm for training large language models and multimodal systems. Despite notable advances enabled by existing RLHF training frameworks, significant challenges remain in scaling to complex multimodal workflows and adapting to dynamic workloads. In particular, current systems often encounter limitations related to controller scalability when managing large models, as well as inefficiencies in orchestrating intricate RLHF pipelines, especially in scenarios that require dynamic sampling and resource allocation. In this paper, we introduce WeChat-YATT (Yet Another Transformer Trainer in WeChat), a simple, scalable, and balanced RLHF training framework specifically designed to address these challenges. WeChat-YATT features a parallel controller programming model that enables flexible and efficient orchestration of complex RLHF workflows, effectively mitigating the bottlenecks associated with centralized controller architectures and facilitating scalability in large-scale data scenarios. In addition, we propose a dynamic placement schema that adaptively partitions computational resources and schedules workloads, thereby significantly reducing hardware idle time and improving GPU utilization under variable training conditions. We evaluate WeChat-YATT across a range of experimental scenarios, demonstrating that it achieves substantial improvements in throughput compared to state-of-the-art RLHF training frameworks. Furthermore, WeChat-YATT has been successfully deployed to train models supporting WeChat product features for a large-scale user base, underscoring its effectiveness and robustness in real-world applications.
G-Core: A Simple, Scalable and Balanced RLHF Trainer
Jul 30, 2025Reinforcement Learning from Human Feedback (RLHF) has become an increasingly popular paradigm for training large language models (LLMs) and diffusion models. While existing RLHF training systems have enabled significant progress, they often face challenges in scaling to multi-modal and diffusion workflows and adapting to dynamic workloads. In particular, current approaches may encounter limitations in controller scalability, flexible resource placement, and efficient orchestration when handling complex RLHF pipelines, especially in scenarios involving dynamic sampling or generative reward modeling. In this paper, we present \textbf{G-Core}, a simple, scalable, and balanced RLHF training framework designed to address these challenges. G-Core introduces a parallel controller programming model, enabling flexible and efficient orchestration of complex RLHF workflows without the bottlenecks of a single centralized controller. Furthermore, we propose a dynamic placement schema that adaptively partitions resources and schedules workloads, significantly reducing hardware idle time and improving utilization, even under highly variable training conditions. G-Core has successfully trained models that support WeChat product features serving a large-scale user base, demonstrating its effectiveness and robustness in real-world scenarios. Our results show that G-Core advances the state of the art in RLHF training, providing a solid foundation for future research and deployment of large-scale, human-aligned models.
Discriminative Policy Optimization for Token-Level Reward Models
May 29, 2025Process reward models (PRMs) provide more nuanced supervision compared to outcome reward models (ORMs) for optimizing policy models, positioning them as a promising approach to enhancing the capabilities of LLMs in complex reasoning tasks. Recent efforts have advanced PRMs from step-level to token-level granularity by integrating reward modeling into the training of generative models, with reward scores derived from token generation probabilities. However, the conflict between generative language modeling and reward modeling may introduce instability and lead to inaccurate credit assignments. To address this challenge, we revisit token-level reward assignment by decoupling reward modeling from language generation and derive a token-level reward model through the optimization of a discriminative policy, termed the Q-function Reward Model (Q-RM). We theoretically demonstrate that Q-RM explicitly learns token-level Q-functions from preference data without relying on fine-grained annotations. In our experiments, Q-RM consistently outperforms all baseline methods across various benchmarks. For example, when integrated into PPO/REINFORCE algorithms, Q-RM enhances the average Pass@1 score by 5.85/4.70 points on mathematical reasoning tasks compared to the ORM baseline, and by 4.56/5.73 points compared to the token-level PRM counterpart. Moreover, reinforcement learning with Q-RM significantly enhances training efficiency, achieving convergence 12 times faster than ORM on GSM8K and 11 times faster than step-level PRM on MATH. Code and data are available at https://github.com/homzer/Q-RM.
HiDream-I1: A High-Efficient Image Generative Foundation Model with Sparse Diffusion Transformer
May 28, 2025Recent advancements in image generative foundation models have prioritized quality improvements but often at the cost of increased computational complexity and inference latency. To address this critical trade-off, we introduce HiDream-I1, a new open-source image generative foundation model with 17B parameters that achieves state-of-the-art image generation quality within seconds. HiDream-I1 is constructed with a new sparse Diffusion Transformer (DiT) structure. Specifically, it starts with a dual-stream decoupled design of sparse DiT with dynamic Mixture-of-Experts (MoE) architecture, in which two separate encoders are first involved to independently process image and text tokens. Then, a single-stream sparse DiT structure with dynamic MoE architecture is adopted to trigger multi-model interaction for image generation in a cost-efficient manner. To support flexiable accessibility with varied model capabilities, we provide HiDream-I1 in three variants: HiDream-I1-Full, HiDream-I1-Dev, and HiDream-I1-Fast. Furthermore, we go beyond the typical text-to-image generation and remould HiDream-I1 with additional image conditions to perform precise, instruction-based editing on given images, yielding a new instruction-based image editing model namely HiDream-E1. Ultimately, by integrating text-to-image generation and instruction-based image editing, HiDream-I1 evolves to form a comprehensive image agent (HiDream-A1) capable of fully interactive image creation and refinement. To accelerate multi-modal AIGC research, we have open-sourced all the codes and model weights of HiDream-I1-Full, HiDream-I1-Dev, HiDream-I1-Fast, HiDream-E1 through our project websites: https://github.com/HiDream-ai/HiDream-I1 and https://github.com/HiDream-ai/HiDream-E1. All features can be directly experienced via https://vivago.ai/studio.
MotionPro: A Precise Motion Controller for Image-to-Video Generation
May 26, 2025

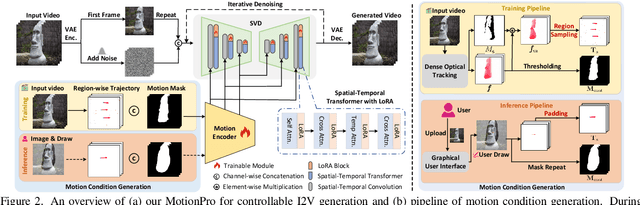

Animating images with interactive motion control has garnered popularity for image-to-video (I2V) generation. Modern approaches typically rely on large Gaussian kernels to extend motion trajectories as condition without explicitly defining movement region, leading to coarse motion control and failing to disentangle object and camera moving. To alleviate these, we present MotionPro, a precise motion controller that novelly leverages region-wise trajectory and motion mask to regulate fine-grained motion synthesis and identify target motion category (i.e., object or camera moving), respectively. Technically, MotionPro first estimates the flow maps on each training video via a tracking model, and then samples the region-wise trajectories to simulate inference scenario. Instead of extending flow through large Gaussian kernels, our region-wise trajectory approach enables more precise control by directly utilizing trajectories within local regions, thereby effectively characterizing fine-grained movements. A motion mask is simultaneously derived from the predicted flow maps to capture the holistic motion dynamics of the movement regions. To pursue natural motion control, MotionPro further strengthens video denoising by incorporating both region-wise trajectories and motion mask through feature modulation. More remarkably, we meticulously construct a benchmark, i.e., MC-Bench, with 1.1K user-annotated image-trajectory pairs, for the evaluation of both fine-grained and object-level I2V motion control. Extensive experiments conducted on WebVid-10M and MC-Bench demonstrate the effectiveness of MotionPro. Please refer to our project page for more results: https://zhw-zhang.github.io/MotionPro-page/.