 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComPose: When to Trust Hands for Object Pose Tracking
May 22, 2026Reconstructing the motion of objects from videos is a key component for embodied AI and robot manipulation. While diverse approaches to object pose tracking have been studied, they rely heavily on strong external priors, such as depth data or 3D templates, and remain highly vulnerable to severe occlusions by hand grasps despite the use of explicit masks. In this work, we present ComPose, a 6DoF object tracking framework designed for hand-aware object pose estimation from RGB video. Rather than treating the hand purely as an occluder, our method harmonizes hand motions as a \textit{complementary cue} for object tracking. In detail, we recover a variety of object motions over time by combining object and hand cues from foundation models within a unified tracking pipeline. Here, ComPose adaptively selects informative hand joints, combines object- and hand-derived cues for motion estimation, and refines the resulting object motion using visible geometric evidence and a learned correction. We further enforce the temporal consistency over both rotation and translation, yielding stable 3D object trajectories over time without any external smoothing. Extensive experiments show that our method is accurate, efficient, and robust under severe hand occlusion and geometric ambiguity. In addition, the resulting trajectories can also effectively transfer to downstream robot manipulation by enabling robots to reconstruct human actions from online videos.
Rebalancing Reference Frame Dominance to Improve Motion in Image-to-Video Models
May 20, 2026Image-to-video models often generate videos that remain overly static, compared to text-to-video models. While prior approaches mitigate this issue by weakening or modifying the image-conditioning signal, they often require additional training or sacrifice fidelity to the reference image. In this work, we identify reference-frame dominance as a key mechanism behind motion suppression. We observe that non-reference frames in I2V models allocate excessive self-attention to reference-frame key tokens, causing reference information to be over-propagated across time and suppressing inter-frame dynamics. Based on this finding, we propose DyMoS (Dynamic Motion Slider), a training-free and model-agnostic method that rebalances the attention pathway from generated frames to the reference frame during initial denoising steps. DyMoS leaves both the input image and model weights unchanged and introduces a single scalar parameter for continuous control over motion strength. Experiments across multiple state-of-the-art I2V backbones demonstrate that DyMoS consistently improves motion dynamics while maintaining visual quality and fidelity to the reference image.
RehearsalNeRF: Decoupling Intrinsic Neural Fields of Dynamic Illuminations for Scene Editing
Apr 02, 2026Although there has been significant progress in neural radiance fields, an issue on dynamic illumination changes still remains unsolved. Different from relevant works that parameterize time-variant/-invariant components in scenes, subjects' radiance is highly entangled with their own emitted radiance and lighting colors in spatio-temporal domain. In this paper, we present a new effective method to learn disentangled neural fields under the severe illumination changes, named RehearsalNeRF. Our key idea is to leverage scenes captured under stable lighting like rehearsal stages, easily taken before dynamic illumination occurs, to enforce geometric consistency between the different lighting conditions. In particular, RehearsalNeRF employs a learnable vector for lighting effects which represents illumination colors in a temporal dimension and is used to disentangle projected light colors from scene radiance. Furthermore, our RehearsalNeRF is also able to reconstruct the neural fields of dynamic objects by simply adopting off-the-shelf interactive masks. To decouple the dynamic objects, we propose a new regularization leveraging optical flow, which provides coarse supervision for the color disentanglement. We demonstrate the effectiveness of RehearsalNeRF by showing robust performances on novel view synthesis and scene editing under dynamic illumination conditions. Our source code and video datasets will be publicly available.
Relaxed Rigidity with Ray-based Grouping for Dynamic Gaussian Splatting
Mar 27, 2026The reconstruction of dynamic 3D scenes using 3D Gaussian Splatting has shown significant promise. A key challenge, however, remains in modeling realistic motion, as most methods fail to align the motion of Gaussians with real-world physical dynamics. This misalignment is particularly problematic for monocular video datasets, where failing to maintain coherent motion undermines local geometric structure, ultimately leading to degraded reconstruction quality. Consequently, many state-of-the-art approaches rely heavily on external priors, such as optical flow or 2D tracks, to enforce temporal coherence. In this work, we propose a novel method to explicitly preserve the local geometric structure of Gaussians across time in 4D scenes. Our core idea is to introduce a view-space ray grouping strategy that clusters Gaussians intersected by the same ray, considering only those whose $α$-blending weights exceed a threshold. We then apply constraints to these groups to maintain a consistent spatial distribution, effectively preserving their local geometry. This approach enforces a more physically plausible motion model by ensuring that local geometry remains stable over time, eliminating the reliance on external guidance. We demonstrate the efficacy of our method by integrating it into two distinct baseline models. Extensive experiments on challenging monocular datasets show that our approach significantly outperforms existing methods, achieving superior temporal consistency and reconstruction quality.
Motion Prior Distillation in Time Reversal Sampling for Generative Inbetweening
Feb 13, 2026Recent progress in image-to-video (I2V) diffusion models has significantly advanced the field of generative inbetweening, which aims to generate semantically plausible frames between two keyframes. In particular, inference-time sampling strategies, which leverage the generative priors of large-scale pre-trained I2V models without additional training, have become increasingly popular. However, existing inference-time sampling, either fusing forward and backward paths in parallel or alternating them sequentially, often suffers from temporal discontinuities and undesirable visual artifacts due to the misalignment between the two generated paths. This is because each path follows the motion prior induced by its own conditioning frame. In this work, we propose Motion Prior Distillation (MPD), a simple yet effective inference-time distillation technique that suppresses bidirectional mismatch by distilling the motion residual of the forward path into the backward path. Our method can deliberately avoid denoising the end-conditioned path which causes the ambiguity of the path, and yield more temporally coherent inbetweening results with the forward motion prior. We not only perform quantitative evaluations on standard benchmarks, but also conduct extensive user studies to demonstrate the effectiveness of our approach in practical scenarios.
Continuous Locomotive Crowd Behavior Generation
Apr 07, 2025



Modeling and reproducing crowd behaviors are important in various domains including psychology, robotics, transport engineering and virtual environments. Conventional methods have focused on synthesizing momentary scenes, which have difficulty in replicating the continuous nature of real-world crowds. In this paper, we introduce a novel method for automatically generating continuous, realistic crowd trajectories with heterogeneous behaviors and interactions among individuals. We first design a crowd emitter model. To do this, we obtain spatial layouts from single input images, including a segmentation map, appearance map, population density map and population probability, prior to crowd generation. The emitter then continually places individuals on the timeline by assigning independent behavior characteristics such as agents' type, pace, and start/end positions using diffusion models. Next, our crowd simulator produces their long-term locomotions. To simulate diverse actions, it can augment their behaviors based on a Markov chain. As a result, our overall framework populates the scenes with heterogeneous crowd behaviors by alternating between the proposed emitter and simulator. Note that all the components in the proposed framework are user-controllable. Lastly, we propose a benchmark protocol to evaluate the realism and quality of the generated crowds in terms of the scene-level population dynamics and the individual-level trajectory accuracy. We demonstrate that our approach effectively models diverse crowd behavior patterns and generalizes well across different geographical environments. Code is publicly available at https://github.com/InhwanBae/CrowdES .
Data-driven Precipitation Nowcasting Using Satellite Imagery
Dec 16, 2024Accurate precipitation forecasting is crucial for early warnings of disasters, such as floods and landslides. Traditional forecasts rely on ground-based radar systems, which are space-constrained and have high maintenance costs. Consequently, most developing countries depend on a global numerical model with low resolution, instead of operating their own radar systems. To mitigate this gap, we propose the Neural Precipitation Model (NPM), which uses global-scale geostationary satellite imagery. NPM predicts precipitation for up to six hours, with an update every hour. We take three key channels to discriminate rain clouds as input: infrared radiation (at a wavelength of 10.5 $\mu m$), upper- (6.3 $\mu m$), and lower- (7.3 $\mu m$) level water vapor channels. Additionally, NPM introduces positional encoders to capture seasonal and temporal patterns, accounting for variations in precipitation. Our experimental results demonstrate that NPM can predict rainfall in real-time with a resolution of 2 km. The code and dataset are available at https://github.com/seominseok0429/Data-driven-Precipitation-Nowcasting-Using-Satellite-Imagery.
Fully Explicit Dynamic Gaussian Splatting
Oct 21, 2024



3D Gaussian Splatting has shown fast and high-quality rendering results in static scenes by leveraging dense 3D prior and explicit representations. Unfortunately, the benefits of the prior and representation do not involve novel view synthesis for dynamic motions. Ironically, this is because the main barrier is the reliance on them, which requires increasing training and rendering times to account for dynamic motions. In this paper, we design a Explicit 4D Gaussian Splatting(Ex4DGS). Our key idea is to firstly separate static and dynamic Gaussians during training, and to explicitly sample positions and rotations of the dynamic Gaussians at sparse timestamps. The sampled positions and rotations are then interpolated to represent both spatially and temporally continuous motions of objects in dynamic scenes as well as reducing computational cost. Additionally, we introduce a progressive training scheme and a point-backtracking technique that improves Ex4DGS's convergence. We initially train Ex4DGS using short timestamps and progressively extend timestamps, which makes it work well with a few point clouds. The point-backtracking is used to quantify the cumulative error of each Gaussian over time, enabling the detection and removal of erroneous Gaussians in dynamic scenes. Comprehensive experiments on various scenes demonstrate the state-of-the-art rendering quality from our method, achieving fast rendering of 62 fps on a single 2080Ti GPU.
Kinetic Typography Diffusion Model
Jul 15, 2024



This paper introduces a method for realistic kinetic typography that generates user-preferred animatable 'text content'. We draw on recent advances in guided video diffusion models to achieve visually-pleasing text appearances. To do this, we first construct a kinetic typography dataset, comprising about 600K videos. Our dataset is made from a variety of combinations in 584 templates designed by professional motion graphics designers and involves changing each letter's position, glyph, and size (i.e., flying, glitches, chromatic aberration, reflecting effects, etc.). Next, we propose a video diffusion model for kinetic typography. For this, there are three requirements: aesthetic appearances, motion effects, and readable letters. This paper identifies the requirements. For this, we present static and dynamic captions used as spatial and temporal guidance of a video diffusion model, respectively. The static caption describes the overall appearance of the video, such as colors, texture and glyph which represent a shape of each letter. The dynamic caption accounts for the movements of letters and backgrounds. We add one more guidance with zero convolution to determine which text content should be visible in the video. We apply the zero convolution to the text content, and impose it on the diffusion model. Lastly, our glyph loss, only minimizing a difference between the predicted word and its ground-truth, is proposed to make the prediction letters readable. Experiments show that our model generates kinetic typography videos with legible and artistic letter motions based on text prompts.
CanonicalFusion: Generating Drivable 3D Human Avatars from Multiple Images
Jul 05, 2024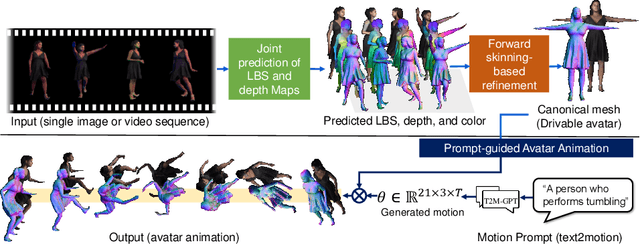
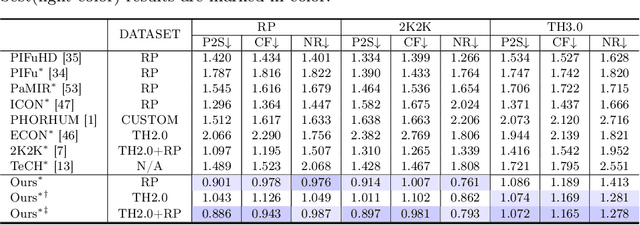
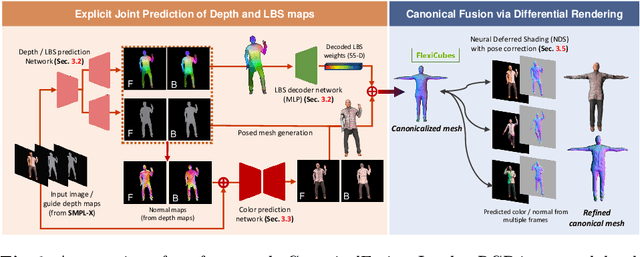
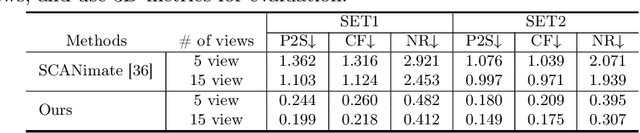
We present a novel framework for reconstructing animatable human avatars from multiple images, termed CanonicalFusion. Our central concept involves integrating individual reconstruction results into the canonical space. To be specific, we first predict Linear Blend Skinning (LBS) weight maps and depth maps using a shared-encoder-dual-decoder network, enabling direct canonicalization of the 3D mesh from the predicted depth maps. Here, instead of predicting high-dimensional skinning weights, we infer compressed skinning weights, i.e., 3-dimensional vector, with the aid of pre-trained MLP networks. We also introduce a forward skinning-based differentiable rendering scheme to merge the reconstructed results from multiple images. This scheme refines the initial mesh by reposing the canonical mesh via the forward skinning and by minimizing photometric and geometric errors between the rendered and the predicted results. Our optimization scheme considers the position and color of vertices as well as the joint angles for each image, thereby mitigating the negative effects of pose errors. We conduct extensive experiments to demonstrate the effectiveness of our method and compare our CanonicalFusion with state-of-the-art methods. Our source codes are available at https://github.com/jsshin98/CanonicalFusion.