 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeVStereo: A NeRF-Driven NVS-Stereo Architecture for High-Fidelity 3D Tasks
Feb 05, 2026In modern dense 3D reconstruction, feed-forward systems (e.g., VGGT, pi3) focus on end-to-end matching and geometry prediction but do not explicitly output the novel view synthesis (NVS). Neural rendering-based approaches offer high-fidelity NVS and detailed geometry from posed images, yet they typically assume fixed camera poses and can be sensitive to pose errors. As a result, it remains non-trivial to obtain a single framework that can offer accurate poses, reliable depth, high-quality rendering, and accurate 3D surfaces from casually captured views. We present NeVStereo, a NeRF-driven NVS-stereo architecture that aims to jointly deliver camera poses, multi-view depth, novel view synthesis, and surface reconstruction from multi-view RGB-only inputs. NeVStereo combines NeRF-based NVS for stereo-friendly renderings, confidence-guided multi-view depth estimation, NeRF-coupled bundle adjustment for pose refinement, and an iterative refinement stage that updates both depth and the radiance field to improve geometric consistency. This design mitigated the common NeRF-based issues such as surface stacking, artifacts, and pose-depth coupling. Across indoor, outdoor, tabletop, and aerial benchmarks, our experiments indicate that NeVStereo achieves consistently strong zero-shot performance, with up to 36% lower depth error, 10.4% improved pose accuracy, 4.5% higher NVS fidelity, and state-of-the-art mesh quality (F1 91.93%, Chamfer 4.35 mm) compared to existing prestigious methods.
Efficient Coordination with the System-Level Shared State: An Embodied-AI Native Modular Framework
Jan 20, 2026As Embodied AI systems move from research prototypes to real world deployments, they tend to evolve rapidly while remaining reliable under workload changes and partial failures. In practice, many deployments are only partially decoupled: middleware moves messages, but shared context and feedback semantics are implicit, causing interface drift, cross-module interference, and brittle recovery at scale. We present ANCHOR, a modular framework that makes decoupling and robustness explicit system-level primitives. ANCHOR separates (i) Canonical Records, an evolvable contract for the standardized shared state, from (ii) a communication bus for many-to-many dissemination and feedback-oriented coordination, forming an inspectable end-to-end loop. We validate closed-loop feasibility on a de-identified workflow instantiation, characterize latency distributions under varying payload sizes and publish rates, and demonstrate automatic stream resumption after hard crashes and restarts even with shared-memory loss. Overall, ANCHOR turns ad-hoc integration glue into explicit contracts, enabling controlled degradation under load and self-healing recovery for scalable deployment of closed-loop AI systems.
GenTe: Generative Real-world Terrains for General Legged Robot Locomotion Control
Apr 14, 2025



Developing bipedal robots capable of traversing diverse real-world terrains presents a fundamental robotics challenge, as existing methods using predefined height maps and static environments fail to address the complexity of unstructured landscapes. To bridge this gap, we propose GenTe, a framework for generating physically realistic and adaptable terrains to train generalizable locomotion policies. GenTe constructs an atomic terrain library that includes both geometric and physical terrains, enabling curriculum training for reinforcement learning-based locomotion policies. By leveraging function-calling techniques and reasoning capabilities of Vision-Language Models (VLMs), GenTe generates complex, contextually relevant terrains from textual and graphical inputs. The framework introduces realistic force modeling for terrain interactions, capturing effects such as soil sinkage and hydrodynamic resistance. To the best of our knowledge, GenTe is the first framework that systemically generates simulation environments for legged robot locomotion control. Additionally, we introduce a benchmark of 100 generated terrains. Experiments demonstrate improved generalization and robustness in bipedal robot locomotion.
Hybrid NeRF-Stereo Vision: Pioneering Depth Estimation and 3D Reconstruction in Endoscopy
Oct 10, 2024



The 3D reconstruction of the surgical field in minimally invasive endoscopic surgery has posed a formidable challenge when using conventional monocular endoscopes. Existing 3D reconstruction methodologies are frequently encumbered by suboptimal accuracy and limited generalization capabilities. In this study, we introduce an innovative pipeline using Neural Radiance Fields (NeRF) for 3D reconstruction. Our approach utilizes a preliminary NeRF reconstruction that yields a coarse model, then creates a binocular scene within the reconstructed environment, which derives an initial depth map via stereo vision. This initial depth map serves as depth supervision for subsequent NeRF iterations, progressively refining the 3D reconstruction with enhanced accuracy. The binocular depth is iteratively recalculated, with the refinement process continuing until the depth map converges, and exhibits negligible variations. Through this recursive process, high-fidelity depth maps are generated from monocular endoscopic video of a realistic cranial phantom. By repeated measures of the final 3D reconstruction compared to X-ray computed tomography, all differences of relevant clinical distances result in sub-millimeter accuracy.
DataCook: Crafting Anti-Adversarial Examples for Healthcare Data Copyright Protection
Mar 26, 2024



In the realm of healthcare, the challenges of copyright protection and unauthorized third-party misuse are increasingly significant. Traditional methods for data copyright protection are applied prior to data distribution, implying that models trained on these data become uncontrollable. This paper introduces a novel approach, named DataCook, designed to safeguard the copyright of healthcare data during the deployment phase. DataCook operates by "cooking" the raw data before distribution, enabling the development of models that perform normally on this processed data. However, during the deployment phase, the original test data must be also "cooked" through DataCook to ensure normal model performance. This process grants copyright holders control over authorization during the deployment phase. The mechanism behind DataCook is by crafting anti-adversarial examples (AntiAdv), which are designed to enhance model confidence, as opposed to standard adversarial examples (Adv) that aim to confuse models. Similar to Adv, AntiAdv introduces imperceptible perturbations, ensuring that the data processed by DataCook remains easily understandable. We conducted extensive experiments on MedMNIST datasets, encompassing both 2D/3D data and the high-resolution variants. The outcomes indicate that DataCook effectively meets its objectives, preventing models trained on AntiAdv from analyzing unauthorized data effectively, without compromising the validity and accuracy of the data in legitimate scenarios. Code and data are available at https://github.com/MedMNIST/DataCook.
SD-DiT: Unleashing the Power of Self-supervised Discrimination in Diffusion Transformer
Mar 25, 2024Diffusion Transformer (DiT) has emerged as the new trend of generative diffusion models on image generation. In view of extremely slow convergence in typical DiT, recent breakthroughs have been driven by mask strategy that significantly improves the training efficiency of DiT with additional intra-image contextual learning. Despite this progress, mask strategy still suffers from two inherent limitations: (a) training-inference discrepancy and (b) fuzzy relations between mask reconstruction & generative diffusion process, resulting in sub-optimal training of DiT. In this work, we address these limitations by novelly unleashing the self-supervised discrimination knowledge to boost DiT training. Technically, we frame our DiT in a teacher-student manner. The teacher-student discriminative pairs are built on the diffusion noises along the same Probability Flow Ordinary Differential Equation (PF-ODE). Instead of applying mask reconstruction loss over both DiT encoder and decoder, we decouple DiT encoder and decoder to separately tackle discriminative and generative objectives. In particular, by encoding discriminative pairs with student and teacher DiT encoders, a new discriminative loss is designed to encourage the inter-image alignment in the self-supervised embedding space. After that, student samples are fed into student DiT decoder to perform the typical generative diffusion task. Extensive experiments are conducted on ImageNet dataset, and our method achieves a competitive balance between training cost and generative capacity.
Prompt-based Learning for Unpaired Image Captioning
May 26, 2022
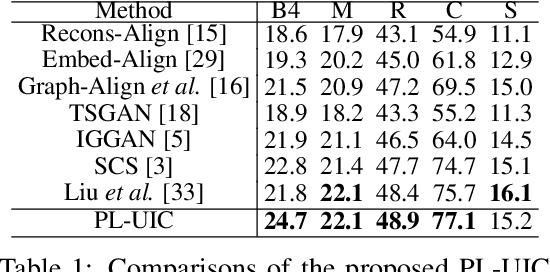
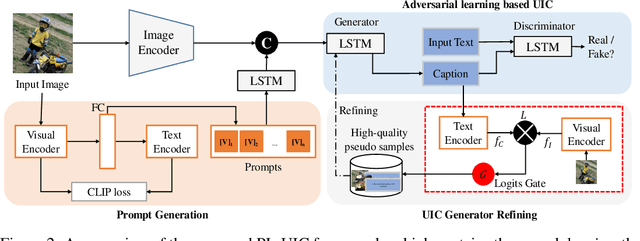
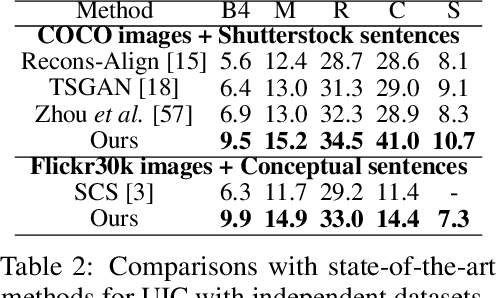
Unpaired Image Captioning (UIC) has been developed to learn image descriptions from unaligned vision-language sample pairs. Existing schemes usually adopt the visual concept reward of reinforcement learning to obtain the alignment between visual concepts and images. However, the cross-domain alignment is usually weak that severely constrains the overall performance of these existing schemes. Recent successes of Vision-Language Pre-Trained Models (VL-PTMs) have triggered the development of prompt-based learning from VL-PTMs. We present in this paper a novel scheme based on prompt to train the UIC model, making best use of the powerful generalization ability and abundant vision-language prior knowledge learned under VL-PTMs. We adopt the CLIP model for this research in unpaired image captioning. Specifically, the visual images are taken as input to the prompt generation module, which contains the pre-trained model as well as one feed-forward layer for prompt extraction. Then, the input images and generated prompts are aggregated for unpaired adversarial captioning learning. To further enhance the potential performance of the captioning, we designed a high-quality pseudo caption filter guided by the CLIP logits to measure correlations between predicted captions and the corresponding images. This allows us to improve the captioning model in a supervised learning manner. Extensive experiments on the COCO and Flickr30K datasets have been carried out to validate the superiority of the proposed model. We have achieved the state-of-the-art performance on the COCO dataset, which outperforms the best UIC model by 1.9% on the BLEU-4 metric. We expect that the proposed prompt-based UIC model will inspire a new line of research for the VL-PTMs based captioning.
Unpaired Image Captioning by Image-level Weakly-Supervised Visual Concept Recognition
Mar 07, 2022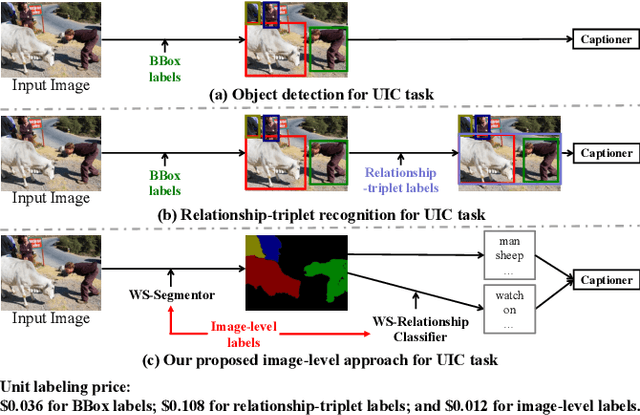


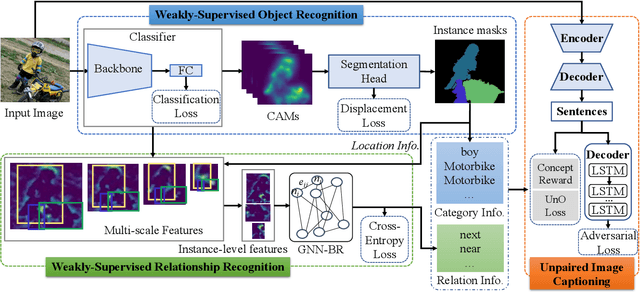
The goal of unpaired image captioning (UIC) is to describe images without using image-caption pairs in the training phase. Although challenging, we except the task can be accomplished by leveraging a training set of images aligned with visual concepts. Most existing studies use off-the-shelf algorithms to obtain the visual concepts because the Bounding Box (BBox) labels or relationship-triplet labels used for the training are expensive to acquire. In order to resolve the problem in expensive annotations, we propose a novel approach to achieve cost-effective UIC. Specifically, we adopt image-level labels for the optimization of the UIC model in a weakly-supervised manner. For each image, we assume that only the image-level labels are available without specific locations and numbers. The image-level labels are utilized to train a weakly-supervised object recognition model to extract object information (e.g., instance) in an image, and the extracted instances are adopted to infer the relationships among different objects based on an enhanced graph neural network (GNN). The proposed approach achieves comparable or even better performance compared with previous methods without the expensive cost of annotations. Furthermore, we design an unrecognized object (UnO) loss combined with a visual concept reward to improve the alignment of the inferred object and relationship information with the images. It can effectively alleviate the issue encountered by existing UIC models about generating sentences with nonexistent objects. To the best of our knowledge, this is the first attempt to solve the problem of Weakly-Supervised visual concept recognition for UIC (WS-UIC) based only on image-level labels. Extensive experiments have been carried out to demonstrate that the proposed WS-UIC model achieves inspiring results on the COCO dataset while significantly reducing the cost of labeling.
Unsupervised Monocular Depth Perception: Focusing on Moving Objects
Aug 30, 2021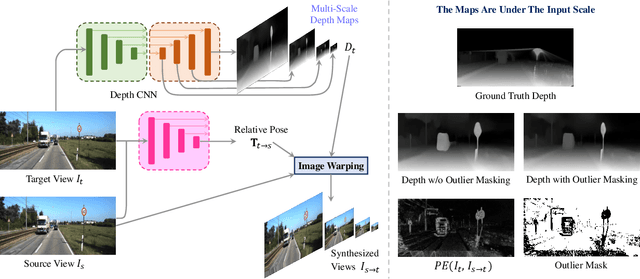
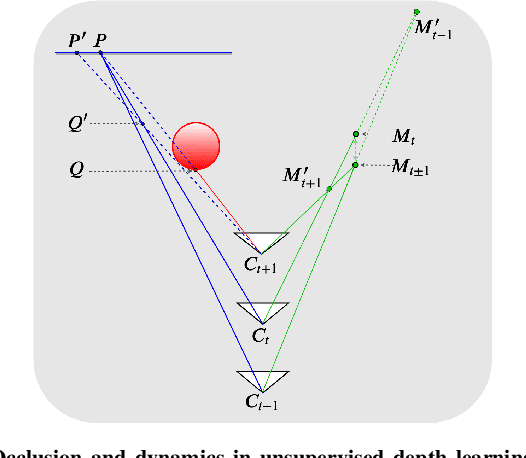
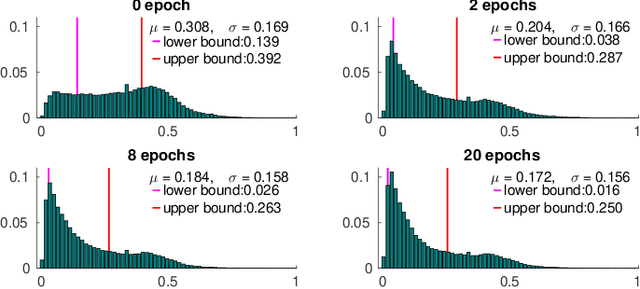
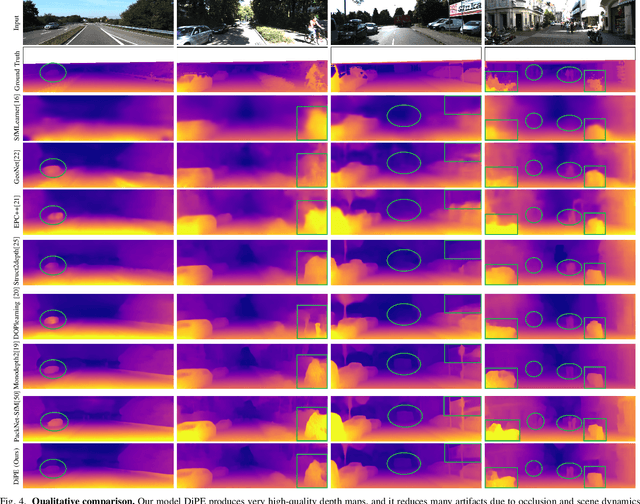
As a flexible passive 3D sensing means, unsupervised learning of depth from monocular videos is becoming an important research topic. It utilizes the photometric errors between the target view and the synthesized views from its adjacent source views as the loss instead of the difference from the ground truth. Occlusion and scene dynamics in real-world scenes still adversely affect the learning, despite significant progress made recently. In this paper, we show that deliberately manipulating photometric errors can efficiently deal with these difficulties better. We first propose an outlier masking technique that considers the occluded or dynamic pixels as statistical outliers in the photometric error map. With the outlier masking, the network learns the depth of objects that move in the opposite direction to the camera more accurately. To the best of our knowledge, such cases have not been seriously considered in the previous works, even though they pose a high risk in applications like autonomous driving. We also propose an efficient weighted multi-scale scheme to reduce the artifacts in the predicted depth maps. Extensive experiments on the KITTI dataset and additional experiments on the Cityscapes dataset have verified the proposed approach's effectiveness on depth or ego-motion estimation. Furthermore, for the first time, we evaluate the predicted depth on the regions of dynamic objects and static background separately for both supervised and unsupervised methods. The evaluation further verifies the effectiveness of our proposed technical approach and provides some interesting observations that might inspire future research in this direction.
Improving Contrastive Learning by Visualizing Feature Transformation
Aug 06, 2021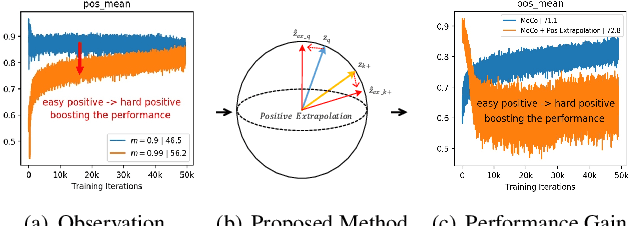

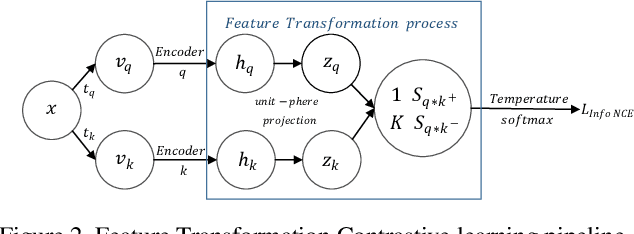

Contrastive learning, which aims at minimizing the distance between positive pairs while maximizing that of negative ones, has been widely and successfully applied in unsupervised feature learning, where the design of positive and negative (pos/neg) pairs is one of its keys. In this paper, we attempt to devise a feature-level data manipulation, differing from data augmentation, to enhance the generic contrastive self-supervised learning. To this end, we first design a visualization scheme for pos/neg score (Pos/neg score indicates cosine similarity of pos/neg pair.) distribution, which enables us to analyze, interpret and understand the learning process. To our knowledge, this is the first attempt of its kind. More importantly, leveraging this tool, we gain some significant observations, which inspire our novel Feature Transformation proposals including the extrapolation of positives. This operation creates harder positives to boost the learning because hard positives enable the model to be more view-invariant. Besides, we propose the interpolation among negatives, which provides diversified negatives and makes the model more discriminative. It is the first attempt to deal with both challenges simultaneously. Experiment results show that our proposed Feature Transformation can improve at least 6.0% accuracy on ImageNet-100 over MoCo baseline, and about 2.0% accuracy on ImageNet-1K over the MoCoV2 baseline. Transferring to the downstream tasks successfully demonstrate our model is less task-bias. Visualization tools and codes https://github.com/DTennant/CL-Visualizing-Feature-Transformation .