 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpikingMamba: Towards Energy-Efficient Large Language Models via Knowledge Distillation from Mamba
Oct 06, 2025



Large Language Models (LLMs) have achieved remarkable performance across tasks but remain energy-intensive due to dense matrix operations. Spiking neural networks (SNNs) improve energy efficiency by replacing dense matrix multiplications with sparse accumulations. Their sparse spike activity enables efficient LLMs deployment on edge devices. However, prior SNN-based LLMs often sacrifice performance for efficiency, and recovering accuracy typically requires full pretraining, which is costly and impractical. To address this, we propose SpikingMamba, an energy-efficient SNN-based LLMs distilled from Mamba that improves energy efficiency with minimal accuracy sacrifice. SpikingMamba integrates two key components: (a) TI-LIF, a ternary-integer spiking neuron that preserves semantic polarity through signed multi-level spike representations. (b) A training-exclusive Smoothed Gradient Compensation (SGC) path mitigating quantization loss while preserving spike-driven efficiency. We employ a single-stage distillation strategy to transfer the zero-shot ability of pretrained Mamba and further enhance it via reinforcement learning (RL). Experiments show that SpikingMamba-1.3B achieves a 4.76$\times$ energy benefit, with only a 4.78\% zero-shot accuracy gap compared to the original Mamba, and achieves a further 2.55\% accuracy improvement after RL.
CoT Vectors: Transferring and Probing the Reasoning Mechanisms of LLMs
Oct 01, 2025Chain-of-Thought (CoT) prompting has emerged as a powerful approach to enhancing the reasoning capabilities of Large Language Models (LLMs). However, existing implementations, such as in-context learning and fine-tuning, remain costly and inefficient. To improve CoT reasoning at a lower cost, and inspired by the task vector paradigm, we introduce CoT Vectors, compact representations that encode task-general, multi-step reasoning knowledge. Through experiments with Extracted CoT Vectors, we observe pronounced layer-wise instability, manifesting as a U-shaped performance curve that reflects a systematic three-stage reasoning process in LLMs. To address this limitation, we propose Learnable CoT Vectors, optimized under a teacher-student framework to provide more stable and robust guidance. Extensive evaluations across diverse benchmarks and models demonstrate that CoT Vectors not only outperform existing baselines but also achieve performance comparable to parameter-efficient fine-tuning methods, while requiring fewer trainable parameters. Moreover, by treating CoT Vectors as a probe, we uncover how their effectiveness varies due to latent space structure, information density, acquisition mechanisms, and pre-training differences, offering new insights into the functional organization of multi-step reasoning in LLMs. The source code will be released.
UST-SSM: Unified Spatio-Temporal State Space Models for Point Cloud Video Modeling
Aug 20, 2025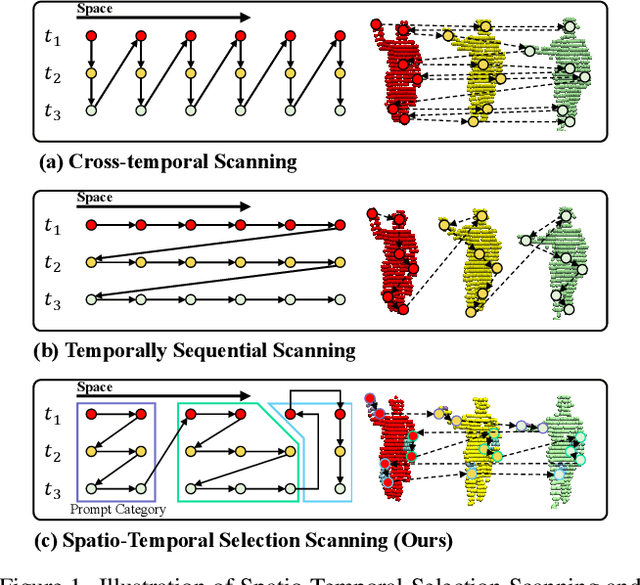
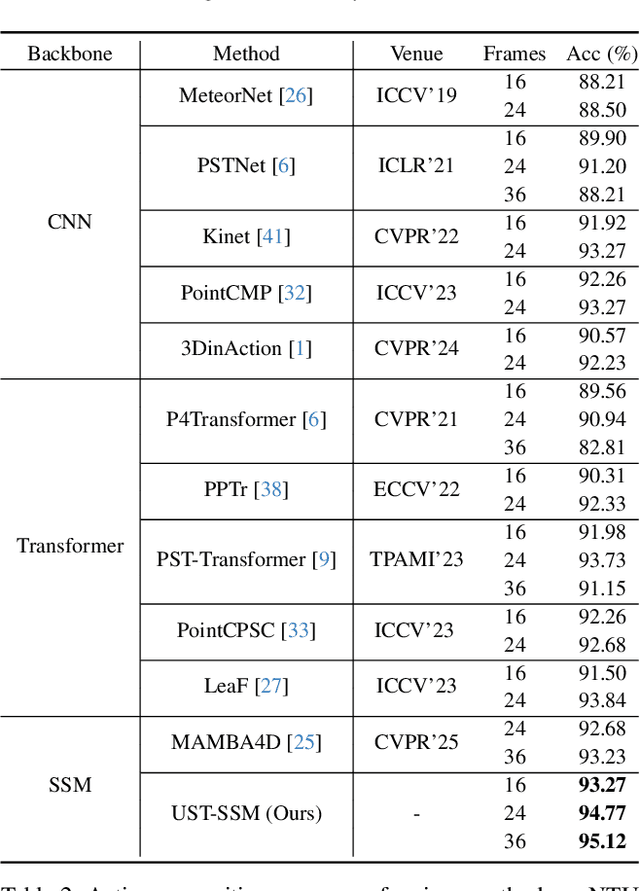
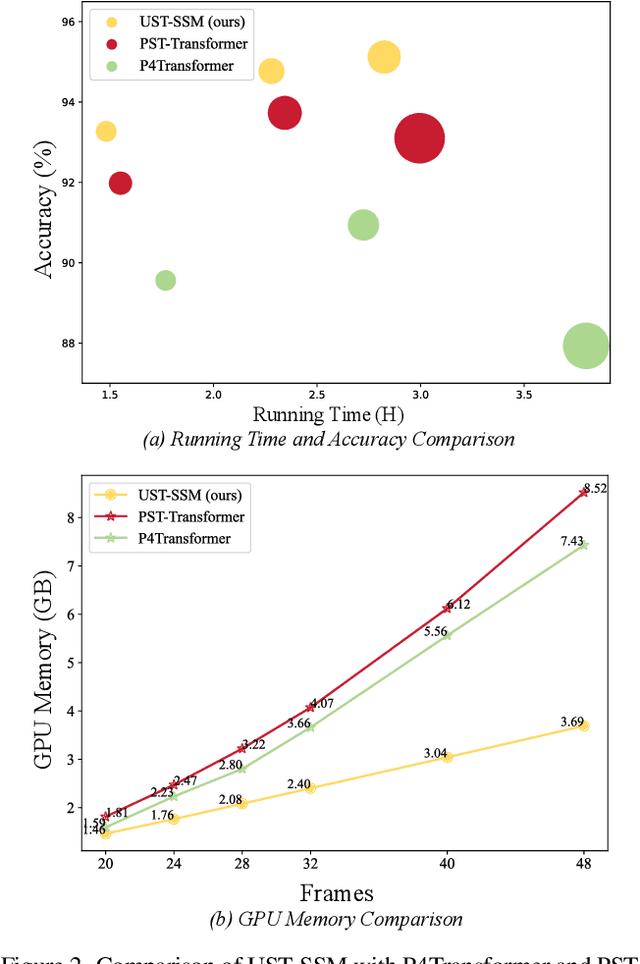
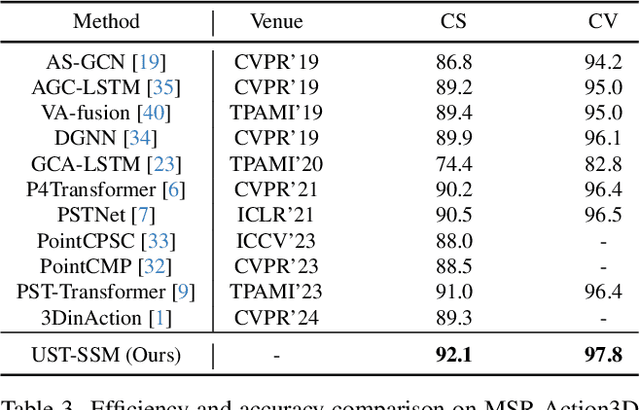
Point cloud videos capture dynamic 3D motion while reducing the effects of lighting and viewpoint variations, making them highly effective for recognizing subtle and continuous human actions. Although Selective State Space Models (SSMs) have shown good performance in sequence modeling with linear complexity, the spatio-temporal disorder of point cloud videos hinders their unidirectional modeling when directly unfolding the point cloud video into a 1D sequence through temporally sequential scanning. To address this challenge, we propose the Unified Spatio-Temporal State Space Model (UST-SSM), which extends the latest advancements in SSMs to point cloud videos. Specifically, we introduce Spatial-Temporal Selection Scanning (STSS), which reorganizes unordered points into semantic-aware sequences through prompt-guided clustering, thereby enabling the effective utilization of points that are spatially and temporally distant yet similar within the sequence. For missing 4D geometric and motion details, Spatio-Temporal Structure Aggregation (STSA) aggregates spatio-temporal features and compensates. To improve temporal interaction within the sampled sequence, Temporal Interaction Sampling (TIS) enhances fine-grained temporal dependencies through non-anchor frame utilization and expanded receptive fields. Experimental results on the MSR-Action3D, NTU RGB+D, and Synthia 4D datasets validate the effectiveness of our method. Our code is available at https://github.com/wangzy01/UST-SSM.
Recognizing Actions from Robotic View for Natural Human-Robot Interaction
Jul 30, 2025



Natural Human-Robot Interaction (N-HRI) requires robots to recognize human actions at varying distances and states, regardless of whether the robot itself is in motion or stationary. This setup is more flexible and practical than conventional human action recognition tasks. However, existing benchmarks designed for traditional action recognition fail to address the unique complexities in N-HRI due to limited data, modalities, task categories, and diversity of subjects and environments. To address these challenges, we introduce ACTIVE (Action from Robotic View), a large-scale dataset tailored specifically for perception-centric robotic views prevalent in mobile service robots. ACTIVE comprises 30 composite action categories, 80 participants, and 46,868 annotated video instances, covering both RGB and point cloud modalities. Participants performed various human actions in diverse environments at distances ranging from 3m to 50m, while the camera platform was also mobile, simulating real-world scenarios of robot perception with varying camera heights due to uneven ground. This comprehensive and challenging benchmark aims to advance action and attribute recognition research in N-HRI. Furthermore, we propose ACTIVE-PC, a method that accurately perceives human actions at long distances using Multilevel Neighborhood Sampling, Layered Recognizers, Elastic Ellipse Query, and precise decoupling of kinematic interference from human actions. Experimental results demonstrate the effectiveness of ACTIVE-PC. Our code is available at: https://github.com/wangzy01/ACTIVE-Action-from-Robotic-View.
Shop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025
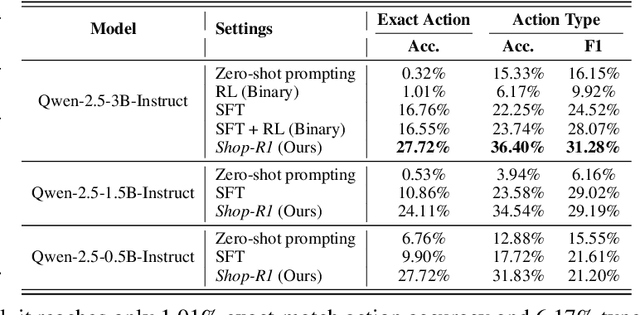
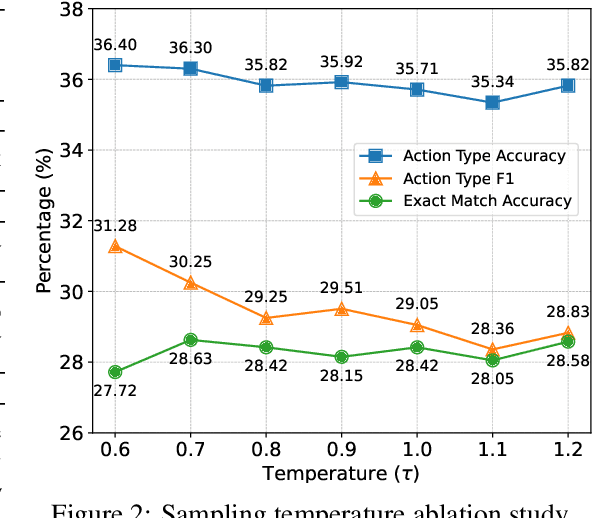
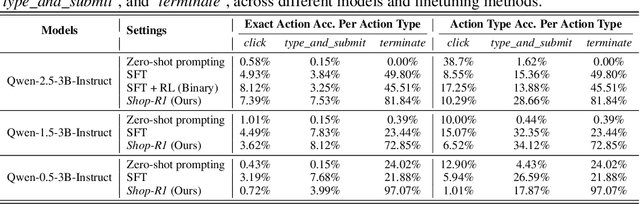
Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.
PPAAS: PVT and Pareto Aware Analog Sizing via Goal-conditioned Reinforcement Learning
Jul 22, 2025



Device sizing is a critical yet challenging step in analog and mixed-signal circuit design, requiring careful optimization to meet diverse performance specifications. This challenge is further amplified under process, voltage, and temperature (PVT) variations, which cause circuit behavior to shift across different corners. While reinforcement learning (RL) has shown promise in automating sizing for fixed targets, training a generalized policy that can adapt to a wide range of design specifications under PVT variations requires much more training samples and resources. To address these challenges, we propose a \textbf{Goal-conditioned RL framework} that enables efficient policy training for analog device sizing across PVT corners, with strong generalization capability. To improve sample efficiency, we introduce Pareto-front Dominance Goal Sampling, which constructs an automatic curriculum by sampling goals from the Pareto frontier of previously achieved goals. This strategy is further enhanced by integrating Conservative Hindsight Experience Replay, which assigns relabeled goals with conservative virtual rewards to stabilize training and accelerate convergence. To reduce simulation overhead, our framework incorporates a Skip-on-Fail simulation strategy, which skips full-corner simulations when nominal-corner simulation fails to meet target specifications. Experiments on benchmark circuits demonstrate $\sim$1.6$\times$ improvement in sample efficiency and $\sim$4.1$\times$ improvement in simulation efficiency compared to existing sizing methods. Code and benchmarks are publicly available at https://github.com/SeunggeunKimkr/PPAAS
Vision Generalist Model: A Survey
Jun 11, 2025Recently, we have witnessed the great success of the generalist model in natural language processing. The generalist model is a general framework trained with massive data and is able to process various downstream tasks simultaneously. Encouraged by their impressive performance, an increasing number of researchers are venturing into the realm of applying these models to computer vision tasks. However, the inputs and outputs of vision tasks are more diverse, and it is difficult to summarize them as a unified representation. In this paper, we provide a comprehensive overview of the vision generalist models, delving into their characteristics and capabilities within the field. First, we review the background, including the datasets, tasks, and benchmarks. Then, we dig into the design of frameworks that have been proposed in existing research, while also introducing the techniques employed to enhance their performance. To better help the researchers comprehend the area, we take a brief excursion into related domains, shedding light on their interconnections and potential synergies. To conclude, we provide some real-world application scenarios, undertake a thorough examination of the persistent challenges, and offer insights into possible directions for future research endeavors.
UniPre3D: Unified Pre-training of 3D Point Cloud Models with Cross-Modal Gaussian Splatting
Jun 11, 2025The scale diversity of point cloud data presents significant challenges in developing unified representation learning techniques for 3D vision. Currently, there are few unified 3D models, and no existing pre-training method is equally effective for both object- and scene-level point clouds. In this paper, we introduce UniPre3D, the first unified pre-training method that can be seamlessly applied to point clouds of any scale and 3D models of any architecture. Our approach predicts Gaussian primitives as the pre-training task and employs differentiable Gaussian splatting to render images, enabling precise pixel-level supervision and end-to-end optimization. To further regulate the complexity of the pre-training task and direct the model's focus toward geometric structures, we integrate 2D features from pre-trained image models to incorporate well-established texture knowledge. We validate the universal effectiveness of our proposed method through extensive experiments across a variety of object- and scene-level tasks, using diverse point cloud models as backbones. Code is available at https://github.com/wangzy22/UniPre3D.
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025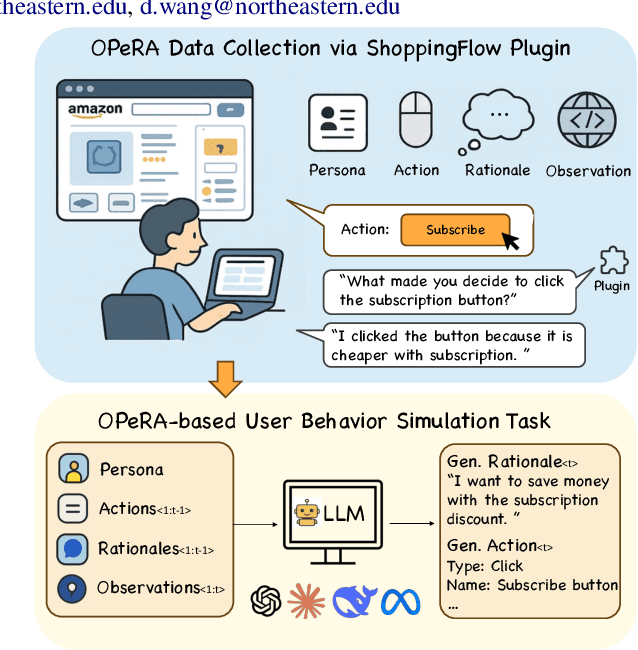
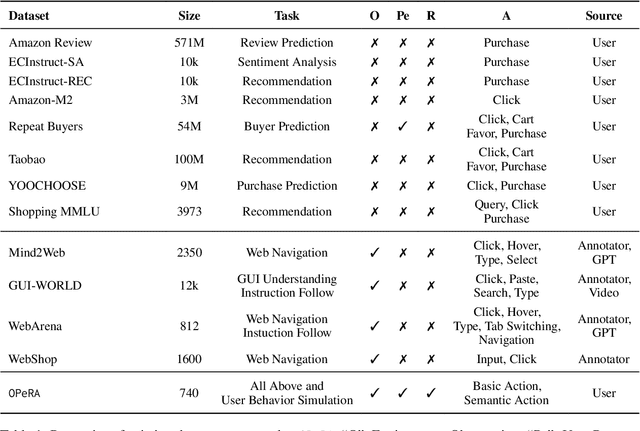
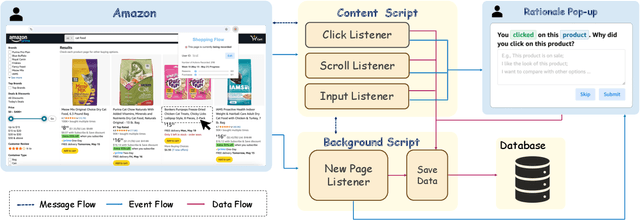
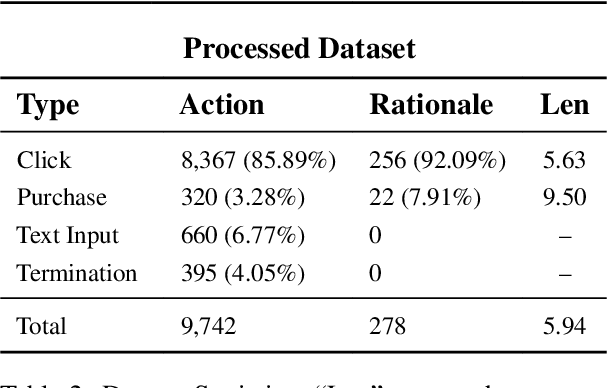
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.
OGGSplat: Open Gaussian Growing for Generalizable Reconstruction with Expanded Field-of-View
Jun 05, 2025Reconstructing semantic-aware 3D scenes from sparse views is a challenging yet essential research direction, driven by the demands of emerging applications such as virtual reality and embodied AI. Existing per-scene optimization methods require dense input views and incur high computational costs, while generalizable approaches often struggle to reconstruct regions outside the input view cone. In this paper, we propose OGGSplat, an open Gaussian growing method that expands the field-of-view in generalizable 3D reconstruction. Our key insight is that the semantic attributes of open Gaussians provide strong priors for image extrapolation, enabling both semantic consistency and visual plausibility. Specifically, once open Gaussians are initialized from sparse views, we introduce an RGB-semantic consistent inpainting module applied to selected rendered views. This module enforces bidirectional control between an image diffusion model and a semantic diffusion model. The inpainted regions are then lifted back into 3D space for efficient and progressive Gaussian parameter optimization. To evaluate our method, we establish a Gaussian Outpainting (GO) benchmark that assesses both semantic and generative quality of reconstructed open-vocabulary scenes. OGGSplat also demonstrates promising semantic-aware scene reconstruction capabilities when provided with two view images captured directly from a smartphone camera.