 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEVA-Net: Subject-Independent EEG Motor Decoding with Video-Derived Motor Priors
Jun 01, 2026Practical non-invasive Brain-Computer Interface (BCI) systems require EEG decoders with strong cross-subject generalization and minimal calibration. However, inter-subject variability and signal non-stationarity often entangle motor semantics with subject-specific noise, limiting subject-independent decoding. Recent multimodal approaches use text as a semantic anchor, yet text provides sparse and static supervision for inherently dynamic motor processes. To address this issue, we propose EVA-Net, a two-stage framework that uses action videos as semantic priors for subject-independent EEG motor decoding. In the first stage, EEG and video features are aligned in a shared space using cross-modal and supervised contrastive objectives to reduce subject-specific variation. In the second stage, video category prototypes and knowledge distillation transfer video-derived priors to an EEG-only classifier without adding inference overhead. Experiments on two public datasets show that EVA-Net achieves strong subject-independent decoding performance, including an 8.66% LOSO accuracy gain on EEGMMI. Ablation results further suggest that video provides a more effective semantic anchor than the text baseline considered in this work.
Self-Supervised Foundation Model for Calcium-imaging Population Dynamics
Apr 03, 2026Recent work suggests that large-scale, multi-animal modeling can significantly improve neural recording analysis. However, for functional calcium traces, existing approaches remain task-specific, limiting transfer across common neuroscience objectives. To address this challenge, we propose \textbf{CalM}, a self-supervised neural foundation model trained solely on neuronal calcium traces and adaptable to multiple downstream tasks, including forecasting and decoding. Our key contribution is a pretraining framework, composed of a high-performance tokenizer mapping single-neuron traces into a shared discrete vocabulary, and a dual-axis autoregressive transformer modeling dependencies along both the neural and the temporal axis. We evaluate CalM on a large-scale, multi-animal, multi-session dataset. On the neural population dynamics forecasting task, CalM outperforms strong specialized baselines after pretraining. With a task-specific head, CalM further adapts to the behavior decoding task and achieves superior results compared with supervised decoding models. Moreover, linear analyses of CalM representations reveal interpretable functional structures beyond predictive accuracy. Taken together, we propose a novel and effective self-supervised pretraining paradigm for foundation models based on calcium traces, paving the way for scalable pretraining and broad applications in functional neural analysis. Code will be released soon.
CarbonBench: A Global Benchmark for Upscaling of Carbon Fluxes Using Zero-Shot Learning
Mar 10, 2026Accurately quantifying terrestrial carbon exchange is essential for climate policy and carbon accounting, yet models must generalize to ecosystems underrepresented in sparse eddy covariance observations. Despite this challenge being a natural instance of zero-shot spatial transfer learning for time series regression, no standardized benchmark exists to rigorously evaluate model performance across geographically distinct locations with different climate regimes and vegetation types. We introduce CarbonBench, the first benchmark for zero-shot spatial transfer in carbon flux upscaling. CarbonBench comprises over 1.3 million daily observations from 567 flux tower sites globally (2000-2024). It provides: (1) stratified evaluation protocols that explicitly test generalization across unseen vegetation types and climate regimes, separating spatial transfer from temporal autocorrelation; (2) a harmonized set of remote sensing and meteorological features to enable flexible architecture design; and (3) baselines ranging from tree-based methods to domain-generalization architectures. By bridging machine learning methodologies and Earth system science, CarbonBench aims to enable systematic comparison of transfer learning methods, serves as a testbed for regression under distribution shift, and contributes to the next-generation climate modeling efforts.
Trajectory2Task: Training Robust Tool-Calling Agents with Synthesized Yet Verifiable Data for Complex User Intents
Jan 28, 2026Tool-calling agents are increasingly deployed in real-world customer-facing workflows. Yet most studies on tool-calling agents focus on idealized settings with general, fixed, and well-specified tasks. In real-world applications, user requests are often (1) ambiguous, (2) changing over time, or (3) infeasible due to policy constraints, and training and evaluation data that cover these diverse, complex interaction patterns remain under-represented. To bridge the gap, we present Trajectory2Task, a verifiable data generation pipeline for studying tool use at scale under three realistic user scenarios: ambiguous intent, changing intent, and infeasible intents. The pipeline first conducts multi-turn exploration to produce valid tool-call trajectories. It then converts these trajectories into user-facing tasks with controlled intent adaptations. This process yields verifiable task that support closed-loop evaluation and training. We benchmark seven state-of-the-art LLMs on the generated complex user scenario tasks and observe frequent failures. Finally, using successful trajectories obtained from task rollouts, we fine-tune lightweight LLMs and find consistent improvements across all three conditions, along with better generalization to unseen tool-use domains, indicating stronger general tool-calling ability.
The Universal Landscape of Human Reasoning
Oct 24, 2025



Understanding how information is dynamically accumulated and transformed in human reasoning has long challenged cognitive psychology, philosophy, and artificial intelligence. Existing accounts, from classical logic to probabilistic models, illuminate aspects of output or individual modelling, but do not offer a unified, quantitative description of general human reasoning dynamics. To solve this, we introduce Information Flow Tracking (IF-Track), that uses large language models (LLMs) as probabilistic encoder to quantify information entropy and gain at each reasoning step. Through fine-grained analyses across diverse tasks, our method is the first successfully models the universal landscape of human reasoning behaviors within a single metric space. We show that IF-Track captures essential reasoning features, identifies systematic error patterns, and characterizes individual differences. Applied to discussion of advanced psychological theory, we first reconcile single- versus dual-process theories in IF-Track and discover the alignment of artificial and human cognition and how LLMs reshaping human reasoning process. This approach establishes a quantitative bridge between theory and measurement, offering mechanistic insights into the architecture of reasoning.
See, Think, Act: Online Shopper Behavior Simulation with VLM Agents
Oct 22, 2025LLMs have recently demonstrated strong potential in simulating online shopper behavior. Prior work has improved action prediction by applying SFT on action traces with LLM-generated rationales, and by leveraging RL to further enhance reasoning capabilities. Despite these advances, current approaches rely on text-based inputs and overlook the essential role of visual perception in shaping human decision-making during web GUI interactions. In this paper, we investigate the integration of visual information, specifically webpage screenshots, into behavior simulation via VLMs, leveraging OPeRA dataset. By grounding agent decision-making in both textual and visual modalities, we aim to narrow the gap between synthetic agents and real-world users, thereby enabling more cognitively aligned simulations of online shopping behavior. Specifically, we employ SFT for joint action prediction and rationale generation, conditioning on the full interaction context, which comprises action history, past HTML observations, and the current webpage screenshot. To further enhance reasoning capabilities, we integrate RL with a hierarchical reward structure, scaled by a difficulty-aware factor that prioritizes challenging decision points. Empirically, our studies show that incorporating visual grounding yields substantial gains: the combination of text and image inputs improves exact match accuracy by more than 6% over text-only inputs. These results indicate that multi-modal grounding not only boosts predictive accuracy but also enhances simulation fidelity in visually complex environments, which captures nuances of human attention and decision-making that text-only agents often miss. Finally, we revisit the design space of behavior simulation frameworks, identify key methodological limitations, and propose future research directions toward building efficient and effective human behavior simulators.
Customer-R1: Personalized Simulation of Human Behaviors via RL-based LLM Agent in Online Shopping
Oct 08, 2025


Simulating step-wise human behavior with Large Language Models (LLMs) has become an emerging research direction, enabling applications in various practical domains. While prior methods, including prompting, supervised fine-tuning (SFT), and reinforcement learning (RL), have shown promise in modeling step-wise behavior, they primarily learn a population-level policy without conditioning on a user's persona, yielding generic rather than personalized simulations. In this work, we pose a critical question: how can LLM agents better simulate personalized user behavior? We introduce Customer-R1, an RL-based method for personalized, step-wise user behavior simulation in online shopping environments. Our policy is conditioned on an explicit persona, and we optimize next-step rationale and action generation via action correctness reward signals. Experiments on the OPeRA dataset emonstrate that Customer-R1 not only significantly outperforms prompting and SFT-based baselines in next-action prediction tasks, but also better matches users' action distribution, indicating higher fidelity in personalized behavior simulation.
Empathy-R1: A Chain-of-Empathy and Reinforcement Learning Framework for Long-Form Mental Health Support
Sep 18, 2025Empathy is critical for effective mental health support, especially when addressing Long Counseling Texts (LCTs). However, existing Large Language Models (LLMs) often generate replies that are semantically fluent but lack the structured reasoning necessary for genuine psychological support, particularly in a Chinese context. To bridge this gap, we introduce Empathy-R1, a novel framework that integrates a Chain-of-Empathy (CoE) reasoning process with Reinforcement Learning (RL) to enhance response quality for LCTs. Inspired by cognitive-behavioral therapy, our CoE paradigm guides the model to sequentially reason about a help-seeker's emotions, causes, and intentions, making its thinking process both transparent and interpretable. Our framework is empowered by a new large-scale Chinese dataset, Empathy-QA, and a two-stage training process. First, Supervised Fine-Tuning instills the CoE's reasoning structure. Subsequently, RL, guided by a dedicated reward model, refines the therapeutic relevance and contextual appropriateness of the final responses. Experiments show that Empathy-R1 achieves strong performance on key automatic metrics. More importantly, human evaluations confirm its superiority, showing a clear preference over strong baselines and achieving a Win@1 rate of 44.30% on our new benchmark. By enabling interpretable and contextually nuanced responses, Empathy-R1 represents a significant advancement in developing responsible and genuinely beneficial AI for mental health support.
Shop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025
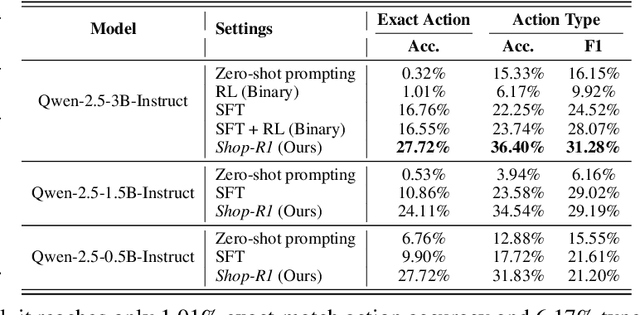
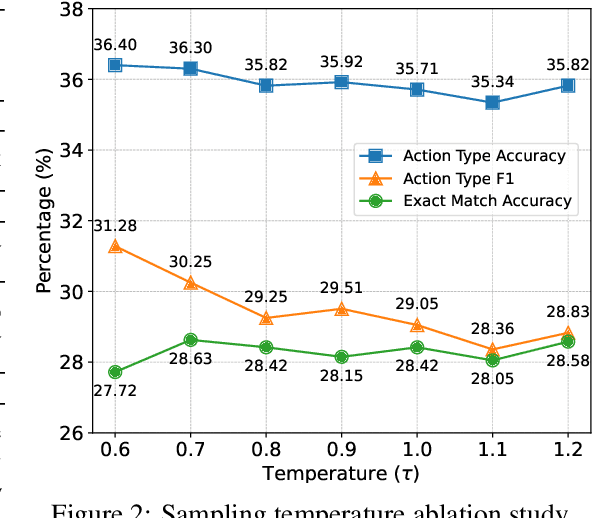
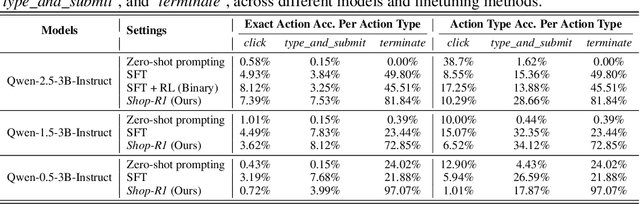
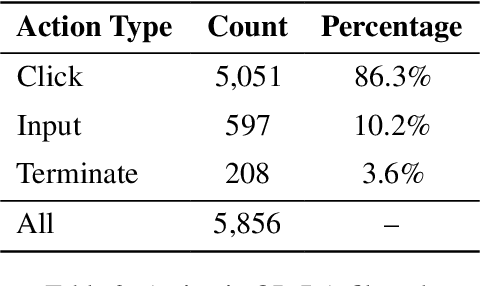
Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.
AI4Research: A Survey of Artificial Intelligence for Scientific Research
Jul 02, 2025Recent advancements in artificial intelligence (AI), particularly in large language models (LLMs) such as OpenAI-o1 and DeepSeek-R1, have demonstrated remarkable capabilities in complex domains such as logical reasoning and experimental coding. Motivated by these advancements, numerous studies have explored the application of AI in the innovation process, particularly in the context of scientific research. These AI technologies primarily aim to develop systems that can autonomously conduct research processes across a wide range of scientific disciplines. Despite these significant strides, a comprehensive survey on AI for Research (AI4Research) remains absent, which hampers our understanding and impedes further development in this field. To address this gap, we present a comprehensive survey and offer a unified perspective on AI4Research. Specifically, the main contributions of our work are as follows: (1) Systematic taxonomy: We first introduce a systematic taxonomy to classify five mainstream tasks in AI4Research. (2) New frontiers: Then, we identify key research gaps and highlight promising future directions, focusing on the rigor and scalability of automated experiments, as well as the societal impact. (3) Abundant applications and resources: Finally, we compile a wealth of resources, including relevant multidisciplinary applications, data corpora, and tools. We hope our work will provide the research community with quick access to these resources and stimulate innovative breakthroughs in AI4Research.