 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTEP-LLM: Generating CAD STEP Models from Natural Language with Large Language Models
Jan 19, 2026Computer-aided design (CAD) is vital to modern manufacturing, yet model creation remains labor-intensive and expertise-heavy. To enable non-experts to translate intuitive design intent into manufacturable artifacts, recent large language models-based text-to-CAD efforts focus on command sequences or script-based formats like CadQuery. However, these formats are kernel-dependent and lack universality for manufacturing. In contrast, the Standard for the Exchange of Product Data (STEP, ISO 10303) file is a widely adopted, neutral boundary representation (B-rep) format directly compatible with manufacturing, but its graph-structured, cross-referenced nature poses unique challenges for auto-regressive LLMs. To address this, we curate a dataset of ~40K STEP-caption pairs and introduce novel preprocessing tailored for the graph-structured format of STEP, including a depth-first search-based reserialization that linearizes cross-references while preserving locality and chain-of-thought(CoT)-style structural annotations that guide global coherence. We integrate retrieval-augmented generation to ground predictions in relevant examples for supervised fine-tuning, and refine generation quality through reinforcement learning with a specific Chamfer Distance-based geometric reward. Experiments demonstrate consistent gains of our STEP-LLM in geometric fidelity over the Text2CAD baseline, with improvements arising from multiple stages of our framework: the RAG module substantially enhances completeness and renderability, the DFS-based reserialization strengthens overall accuracy, and the RL further reduces geometric discrepancy. Both metrics and visual comparisons confirm that STEP-LLM generates shapes with higher fidelity than Text2CAD. These results show the feasibility of LLM-driven STEP model generation from natural language, showing its potential to democratize CAD design for manufacturing.
See, Think, Act: Online Shopper Behavior Simulation with VLM Agents
Oct 22, 2025LLMs have recently demonstrated strong potential in simulating online shopper behavior. Prior work has improved action prediction by applying SFT on action traces with LLM-generated rationales, and by leveraging RL to further enhance reasoning capabilities. Despite these advances, current approaches rely on text-based inputs and overlook the essential role of visual perception in shaping human decision-making during web GUI interactions. In this paper, we investigate the integration of visual information, specifically webpage screenshots, into behavior simulation via VLMs, leveraging OPeRA dataset. By grounding agent decision-making in both textual and visual modalities, we aim to narrow the gap between synthetic agents and real-world users, thereby enabling more cognitively aligned simulations of online shopping behavior. Specifically, we employ SFT for joint action prediction and rationale generation, conditioning on the full interaction context, which comprises action history, past HTML observations, and the current webpage screenshot. To further enhance reasoning capabilities, we integrate RL with a hierarchical reward structure, scaled by a difficulty-aware factor that prioritizes challenging decision points. Empirically, our studies show that incorporating visual grounding yields substantial gains: the combination of text and image inputs improves exact match accuracy by more than 6% over text-only inputs. These results indicate that multi-modal grounding not only boosts predictive accuracy but also enhances simulation fidelity in visually complex environments, which captures nuances of human attention and decision-making that text-only agents often miss. Finally, we revisit the design space of behavior simulation frameworks, identify key methodological limitations, and propose future research directions toward building efficient and effective human behavior simulators.
Token Buncher: Shielding LLMs from Harmful Reinforcement Learning Fine-Tuning
Aug 28, 2025



As large language models (LLMs) continue to grow in capability, so do the risks of harmful misuse through fine-tuning. While most prior studies assume that attackers rely on supervised fine-tuning (SFT) for such misuse, we systematically demonstrate that reinforcement learning (RL) enables adversaries to more effectively break safety alignment and facilitate advanced harmful task assistance, under matched computational budgets. To counter this emerging threat, we propose TokenBuncher, the first effective defense specifically targeting RL-based harmful fine-tuning. TokenBuncher suppresses the foundation on which RL relies: model response uncertainty. By constraining uncertainty, RL-based fine-tuning can no longer exploit distinct reward signals to drive the model toward harmful behaviors. We realize this defense through entropy-as-reward RL and a Token Noiser mechanism designed to prevent the escalation of expert-domain harmful capabilities. Extensive experiments across multiple models and RL algorithms show that TokenBuncher robustly mitigates harmful RL fine-tuning while preserving benign task utility and finetunability. Our results highlight that RL-based harmful fine-tuning poses a greater systemic risk than SFT, and that TokenBuncher provides an effective and general defense.
Shop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025
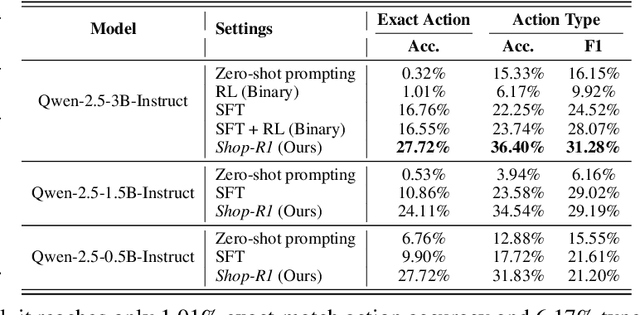
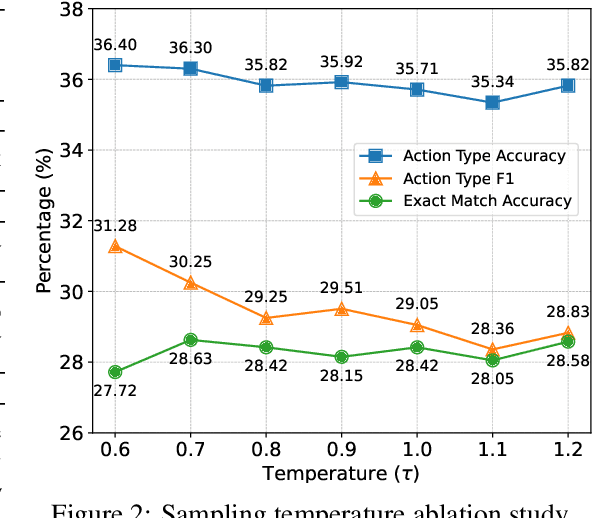
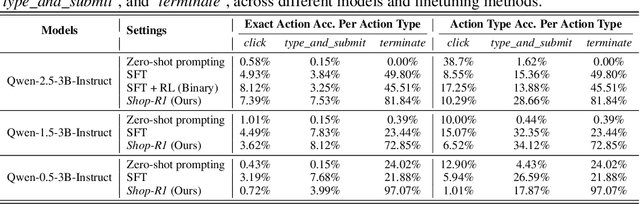
Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.