 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeometry-Preserving Orthonormal Initialization for Low-Rank Adaptation in RLVR
Jun 30, 2026Low-rank adaptation (LoRA) and its variants enable parameter-efficient fine-tuning of large language models under the supervised fine-tuning (SFT) paradigm. However, their efficacy and behavior under Reinforcement learning with verifiable rewards (RLVR) are less well understood. In particular, two structurally initialized LoRA variants, PiSSA and MiLoRA, which outperform standard LoRA under SFT, can underperform standard LoRA under RLVR and may even exhibit training instability. These observations suggest that how to initialize the low-rank matrices in RLVR remains unclear. In this work, we develop a theoretical analysis of LoRA in RLVR, showing that orthonormal initialization achieves the minimal gap between LoRA outcome and that of full fine-tuning. Guided by this insight, we propose geometry-preserving orthonormal initialization for low-rank adaptation in RLVR, leading to two new variants, RLPO and RLMO. Experiments on mathematical reasoning benchmarks show that the proposed orthonormal initialization stabilizes RLVR training and outperforms standard LoRA, contrasting with PiSSA and MiLoRA. Finally, our unified analysis for LoRA initialization also explains why PiSSA and MiLoRA can underperform in RLVR, which may be of independent interest. Code and checkpoints are publicly available at https://github.com/Richard-ZZZ/geometry-preserving-orthonormal-init-rlvr.
Harnessing Photonics for Machine Intelligence
Apr 12, 2026The exponential growth of machine-intelligence workloads is colliding with the power, memory, and interconnect limits of the post-Moore era, motivating compute substrates that scale beyond transistor density alone. Integrated photonics is emerging as a candidate for artificial intelligence (AI) acceleration by exploiting optical bandwidth and parallelism to reshape data movement and computation. This review reframes photonic computing from a circuits-and-systems perspective, moving beyond building-block progress toward cross-layer system analysis and full-stack design automation. We synthesize recent advances through a bottleneck-driven taxonomy that delineates the operating regimes and scaling trends where photonics can deliver end-to-end sustained benefits. A central theme is cross-layer co-design and workload-adaptive programmability to sustain high efficiency and versatility across evolving application domains at scale. We further argue that Electronic-Photonic Design Automation (EPDA) will be pivotal, enabling closed-loop co-optimization across simulation, inverse design, system modeling, and physical implementation. By charting a roadmap from laboratory prototypes to scalable, reproducible electronic-photonic ecosystems, this review aims to guide the CAS community toward an automated, system-centric era of photonic machine intelligence.
The Path Not Taken: RLVR Provably Learns Off the Principals
Nov 11, 2025Reinforcement Learning with Verifiable Rewards (RLVR) reliably improves the reasoning performance of large language models, yet it appears to modify only a small fraction of parameters. We revisit this paradox and show that sparsity is a surface artifact of a model-conditioned optimization bias: for a fixed pretrained model, updates consistently localize to preferred parameter regions, highly consistent across runs and largely invariant to datasets and RL recipes. We mechanistically explain these dynamics with a Three-Gate Theory: Gate I (KL Anchor) imposes a KL-constrained update; Gate II (Model Geometry) steers the step off principal directions into low-curvature, spectrum-preserving subspaces; and Gate III (Precision) hides micro-updates in non-preferred regions, making the off-principal bias appear as sparsity. We then validate this theory and, for the first time, provide a parameter-level characterization of RLVR's learning dynamics: RLVR learns off principal directions in weight space, achieving gains via minimal spectral drift, reduced principal-subspace rotation, and off-principal update alignment. In contrast, SFT targets principal weights, distorts the spectrum, and even lags RLVR. Together, these results provide the first parameter-space account of RLVR's training dynamics, revealing clear regularities in how parameters evolve. Crucially, we show that RL operates in a distinct optimization regime from SFT, so directly adapting SFT-era parameter-efficient fine-tuning (PEFT) methods can be flawed, as evidenced by our case studies on advanced sparse fine-tuning and LoRA variants. We hope this work charts a path toward a white-box understanding of RLVR and the design of geometry-aware, RLVR-native learning algorithms, rather than repurposed SFT-era heuristics.
PPAAS: PVT and Pareto Aware Analog Sizing via Goal-conditioned Reinforcement Learning
Jul 22, 2025



Device sizing is a critical yet challenging step in analog and mixed-signal circuit design, requiring careful optimization to meet diverse performance specifications. This challenge is further amplified under process, voltage, and temperature (PVT) variations, which cause circuit behavior to shift across different corners. While reinforcement learning (RL) has shown promise in automating sizing for fixed targets, training a generalized policy that can adapt to a wide range of design specifications under PVT variations requires much more training samples and resources. To address these challenges, we propose a \textbf{Goal-conditioned RL framework} that enables efficient policy training for analog device sizing across PVT corners, with strong generalization capability. To improve sample efficiency, we introduce Pareto-front Dominance Goal Sampling, which constructs an automatic curriculum by sampling goals from the Pareto frontier of previously achieved goals. This strategy is further enhanced by integrating Conservative Hindsight Experience Replay, which assigns relabeled goals with conservative virtual rewards to stabilize training and accelerate convergence. To reduce simulation overhead, our framework incorporates a Skip-on-Fail simulation strategy, which skips full-corner simulations when nominal-corner simulation fails to meet target specifications. Experiments on benchmark circuits demonstrate $\sim$1.6$\times$ improvement in sample efficiency and $\sim$4.1$\times$ improvement in simulation efficiency compared to existing sizing methods. Code and benchmarks are publicly available at https://github.com/SeunggeunKimkr/PPAAS
Can Test-Time Scaling Improve World Foundation Model?
Mar 31, 2025World foundation models, which simulate the physical world by predicting future states from current observations and inputs, have become central to many applications in physical intelligence, including autonomous driving and robotics. However, these models require substantial computational resources for pretraining and are further constrained by available data during post-training. As such, scaling computation at test time emerges as both a critical and practical alternative to traditional model enlargement or re-training. In this work, we introduce SWIFT, a test-time scaling framework tailored for WFMs. SWIFT integrates our extensible WFM evaluation toolkit with process-level inference strategies, including fast tokenization, probability-based Top-K pruning, and efficient beam search. Empirical results on the COSMOS model demonstrate that test-time scaling exists even in a compute-optimal way. Our findings reveal that test-time scaling laws hold for WFMs and that SWIFT provides a scalable and effective pathway for improving WFM inference without retraining or increasing model size. The code is available at https://github.com/Mia-Cong/SWIFT.git.
APOLLO: SGD-like Memory, AdamW-level Performance
Dec 09, 2024



Large language models (LLMs) are notoriously memory-intensive during training, particularly with the popular AdamW optimizer. This memory burden necessitates using more or higher-end GPUs or reducing batch sizes, limiting training scalability and throughput. To address this, various memory-efficient optimizers have been proposed to reduce optimizer memory usage. However, they face critical challenges: (i) reliance on costly SVD operations; (ii) significant performance trade-offs compared to AdamW; and (iii) still substantial optimizer memory overhead to maintain competitive performance. In this work, we identify that AdamW's learning rate adaptation rule can be effectively coarsened as a structured learning rate update. Based on this insight, we propose Approximated Gradient Scaling for Memory-Efficient LLM Optimization (APOLLO), which approximates learning rate scaling using an auxiliary low-rank optimizer state based on pure random projection. This structured learning rate update rule makes APOLLO highly tolerant to further memory reductions while delivering comparable pre-training performance. Even its rank-1 variant, APOLLO-Mini, achieves superior pre-training performance compared to AdamW with SGD-level memory costs. Extensive experiments demonstrate that the APOLLO series performs on-par with or better than AdamW, while achieving greater memory savings by nearly eliminating the optimization states of AdamW. These savings provide significant system-level benefits: (1) Enhanced Throughput: 3x throughput on an 8xA100-80GB setup compared to AdamW by supporting 4x larger batch sizes. (2) Improved Model Scalability: Pre-training LLaMA-13B with naive DDP on A100-80GB GPUs without system-level optimizations. (3) Low-End GPU Friendly Pre-training: Pre-training LLaMA-7B on a single GPU using less than 12 GB of memory with weight quantization.
PACE: Pacing Operator Learning to Accurate Optical Field Simulation for Complicated Photonic Devices
Nov 05, 2024



Electromagnetic field simulation is central to designing, optimizing, and validating photonic devices and circuits. However, costly computation associated with numerical simulation poses a significant bottleneck, hindering scalability and turnaround time in the photonic circuit design process. Neural operators offer a promising alternative, but existing SOTA approaches, NeurOLight, struggle with predicting high-fidelity fields for real-world complicated photonic devices, with the best reported 0.38 normalized mean absolute error in NeurOLight. The inter-plays of highly complex light-matter interaction, e.g., scattering and resonance, sensitivity to local structure details, non-uniform learning complexity for full-domain simulation, and rich frequency information, contribute to the failure of existing neural PDE solvers. In this work, we boost the prediction fidelity to an unprecedented level for simulating complex photonic devices with a novel operator design driven by the above challenges. We propose a novel cross-axis factorized PACE operator with a strong long-distance modeling capacity to connect the full-domain complex field pattern with local device structures. Inspired by human learning, we further divide and conquer the simulation task for extremely hard cases into two progressively easy tasks, with a first-stage model learning an initial solution refined by a second model. On various complicated photonic device benchmarks, we demonstrate one sole PACE model is capable of achieving 73% lower error with 50% fewer parameters compared with various recent ML for PDE solvers. The two-stage setup further advances high-fidelity simulation for even more intricate cases. In terms of runtime, PACE demonstrates 154-577x and 11.8-12x simulation speedup over numerical solver using scipy or highly-optimized pardiso solver, respectively. We open sourced the code and dataset.
INSIGHT: Universal Neural Simulator for Analog Circuits Harnessing Autoregressive Transformers
Jul 10, 2024



Analog front-end design heavily relies on specialized human expertise and costly trial-and-error simulations, which motivated many prior works on analog design automation. However, efficient and effective exploration of the vast and complex design space remains constrained by the time-consuming nature of CPU-based SPICE simulations, making effective design automation a challenging endeavor. In this paper, we introduce INSIGHT, a GPU-powered, technology-independent, effective universal neural simulator in the analog front-end design automation loop. INSIGHT accurately predicts the performance metrics of analog circuits across various technology nodes, significantly reducing inference time. Notably, its autoregressive capabilities enable INSIGHT to accurately predict simulation-costly critical transient specifications leveraging less expensive performance metric information. The low cost and high fidelity feature make INSIGHT a good substitute for standard simulators in analog front-end optimization frameworks. INSIGHT is compatible with any optimization framework, facilitating enhanced design space exploration for sample efficiency through sophisticated offline learning and adaptation techniques. Our experiments demonstrate that INSIGHT-M, a model-based batch reinforcement learning framework that leverages INSIGHT for analog sizing, achieves at least 50X improvement in sample efficiency across circuits. To the best of our knowledge, this marks the first use of autoregressive transformers in analog front-end design.
LLM-Enhanced Bayesian Optimization for Efficient Analog Layout Constraint Generation
Jun 07, 2024



Analog layout synthesis faces significant challenges due to its dependence on manual processes, considerable time requirements, and performance instability. Current Bayesian Optimization (BO)-based techniques for analog layout synthesis, despite their potential for automation, suffer from slow convergence and extensive data needs, limiting their practical application. This paper presents the \texttt{LLANA} framework, a novel approach that leverages Large Language Models (LLMs) to enhance BO by exploiting the few-shot learning abilities of LLMs for more efficient generation of analog design-dependent parameter constraints. Experimental results demonstrate that \texttt{LLANA} not only achieves performance comparable to state-of-the-art (SOTA) BO methods but also enables a more effective exploration of the analog circuit design space, thanks to LLM's superior contextual understanding and learning efficiency. The code is available at \url{https://github.com/dekura/LLANA}.
Integrated multi-operand optical neurons for scalable and hardware-efficient deep learning
May 31, 2023


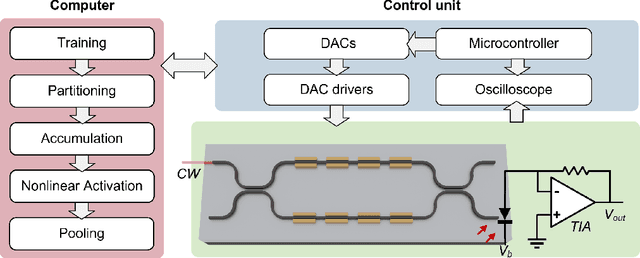
The optical neural network (ONN) is a promising hardware platform for next-generation neuromorphic computing due to its high parallelism, low latency, and low energy consumption. However, previous integrated photonic tensor cores (PTCs) consume numerous single-operand optical modulators for signal and weight encoding, leading to large area costs and high propagation loss to implement large tensor operations. This work proposes a scalable and efficient optical dot-product engine based on customized multi-operand photonic devices, namely multi-operand optical neurons (MOON). We experimentally demonstrate the utility of a MOON using a multi-operand-Mach-Zehnder-interferometer (MOMZI) in image recognition tasks. Specifically, our MOMZI-based ONN achieves a measured accuracy of 85.89% in the street view house number (SVHN) recognition dataset with 4-bit voltage control precision. Furthermore, our performance analysis reveals that a 128x128 MOMZI-based PTCs outperform their counterparts based on single-operand MZIs by one to two order-of-magnitudes in propagation loss, optical delay, and total device footprint, with comparable matrix expressivity.