 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDIMOS: Disentangling Instance-level Moving Object Segmentation
Jun 11, 2026Moving instance segmentation (MIS) attracts increasing attention due to its broad applications in traffic surveillance, autonomous driving, and animal tracking. Event cameras record asynchronous brightness changes, providing high temporal resolution and dynamic range, which makes them highly sensitive to motion information. By fusing event and image features, motion cues from events can complement spatial details from images, enhancing the performance of MIS. However, current multimodal MIS methods still struggle to segment small moving instances, as event cameras often yield sparse features under limited resolution. Moreover, event features entangle appearance attributes with motion cues, which further restricts effective cross-modal fusion. To address these challenges, we first propose a dual-disentangling feature extraction framework that separates and extracts appearance and motion information within both image and event modalities, thereby improving feature density. Subsequently, a multi-granularity cross-modal alignment is introduced to align distributionally and semantically consistent features across modalities, enabling more effective fusion with rich spatial and temporal details. The experiment results demonstrate that our method achieves state-of-the-art performance in multimodal MIS, especially for small instances under challenging conditions such as fast motion and low-light settings.
MDN: Parallelizing Stepwise Momentum for Delta Linear Attention
May 07, 2026Linear Attention (LA) offers a promising paradigm for scaling large language models (LLMs) to long sequences by avoiding the quadratic complexity of self-attention. Recent LA models such as Mamba2 and GDN interpret linear recurrences as closed-form online stochastic gradient descent (SGD), but naive SGD updates suffer from rapid information decay and suboptimal convergence in optimization. While momentum-based optimizers provide a natural remedy, they pose challenges in simultaneously achieving training efficiency and effectiveness. To address this, we develop a chunkwise parallel algorithm for LA with a stepwise momentum rule by geometrically reordering the update coefficients. Further, from a dynamical systems perspective, we analyze the momentum-based recurrence as a second-order system that introduces complex conjugate eigenvalues. This analysis guides the design of stable gating constraints. The resulting model, Momentum DeltaNet (MDN), leverages Triton kernels to achieve comparable training throughput with competitive linear models such as Mamba2 and KDA. Extensive experiments on the 400M and 1.3B parameter models demonstrate consistent performance improvements over strong baselines, including Transformers, Mamba2 and GDN, across diverse downstream evaluation benchmarks. Code: https://github.com/HuuYuLong/MomentumDeltaNet .
Exploring Data-Free LoRA Transferability for Video Diffusion Models
May 03, 2026Video diffusion models leveraging step distillation or causal distillation have achieved remarkable performance. However, adapting existing LoRAs to these variants remains a critical challenge due to weight space mismatches. We observe that direct application leads to style degradation and structural collapse, yet the underlying mechanisms remain poorly understood. To fill this gap, we delve into the weight space and identify that the incompatibility stems from spectral interference within shared functional clusters defined over singular subspaces. Specifically, our analysis reveals that while both paradigms respect spectral rigidity, they establish conflicting routing pathways that clash through constructive overload or destructive cancellation. To address this issue, we propose Cluster-Aware Spectral Arbitration (CASA), a data-free framework that dynamically arbitrates between safeguarding the target's manifold and restoring LoRA alignment based on spectral density. Extensive experiments demonstrate that CASA effectively mitigates artifacts and revives LoRA functionality. Our code is available at https://github.com/Noahwangyuchen/CASA
Sparsity-Aware Event-Driven Impulse Radio Transceivers for Reliable Neuromorphic Inference
Apr 26, 2026The growing number of Internet-of-Things (IoT) based artificial intelligence (AI) applications deployed at resource-constrained network edge call for ultra-reliable and low-latency data processing pipelines from distributed front-end sensors to remote inference units. Meanwhile, brain-inspired neuromorphic computing featuring spiking neural networks (SNNs) have arisen as a new paradigm for energy-efficient AI inference. However, significant energy and time expenses incurred in high-complexity transceivers that combat fading and multi-user interference hinder implementations of multi-user neuromorphic inference for edge intelligence. To address this challenge, we consider in this paper a broadband multi-user remote inference system that integrates event-based sensing and time-hopping (TH) on-off keying (OOK) based ultra-wideband (UWB) communications for reliable neuromorphic inference. Specifically, we propose a novel two-timescale repetition coding that leverages intra-frame pulse sparsity for low-latency repetition. We also develop two neuromorphic inference schemes based on: (i) digital spike encoding that recovers each pixel of the event-frame by threshold-adaptive detection via an SNN based sparsity estimator; and (ii) analog spike encoding that converts noisy correlator outputs at the receiver into analog-valued inputs for end-to-end (E2E) classification. Finally, numerical results validate the effectiveness of the proposed coding schemes, and reveal a signal-to-noise ratio (SNR)-dependent performance crossover between the two inference schemes, indicating that analog spike encoding based schemes are preferable with mild or high SNR while digital spike encoding based schemes remain robust in low SNR regime.
Guidance Matters: Rethinking the Evaluation Pitfall for Text-to-Image Generation
Feb 26, 2026Classifier-free guidance (CFG) has helped diffusion models achieve great conditional generation in various fields. Recently, more diffusion guidance methods have emerged with improved generation quality and human preference. However, can these emerging diffusion guidance methods really achieve solid and significant improvements? In this paper, we rethink recent progress on diffusion guidance. Our work mainly consists of four contributions. First, we reveal a critical evaluation pitfall that common human preference models exhibit a strong bias towards large guidance scales. Simply increasing the CFG scale can easily improve quantitative evaluation scores due to strong semantic alignment, even if image quality is severely damaged (e.g., oversaturation and artifacts). Second, we introduce a novel guidance-aware evaluation (GA-Eval) framework that employs effective guidance scale calibration to enable fair comparison between current guidance methods and CFG by identifying the effects orthogonal and parallel to CFG effects. Third, motivated by the evaluation pitfall, we design Transcendent Diffusion Guidance (TDG) method that can significantly improve human preference scores in the conventional evaluation framework but actually does not work in practice. Fourth, in extensive experiments, we empirically evaluate recent eight diffusion guidance methods within the conventional evaluation framework and the proposed GA-Eval framework. Notably, simply increasing the CFG scales can compete with most studied diffusion guidance methods, while all methods suffer severely from winning rate degradation over standard CFG. Our work would strongly motivate the community to rethink the evaluation paradigm and future directions of this field.
PhysBrain: Human Egocentric Data as a Bridge from Vision Language Models to Physical Intelligence
Dec 18, 2025



Robotic generalization relies on physical intelligence: the ability to reason about state changes, contact-rich interactions, and long-horizon planning under egocentric perception and action. However, most VLMs are trained primarily on third-person data, creating a fundamental viewpoint mismatch for humanoid robots. Scaling robot egocentric data collection remains impractical due to high cost and limited diversity, whereas large-scale human egocentric videos offer a scalable alternative that naturally capture rich interaction context and causal structure. The key challenge is to convert raw egocentric videos into structured and reliable embodiment training supervision. Accordingly, we propose an Egocentric2Embodiment translation pipeline that transforms first-person videos into multi-level, schema-driven VQA supervision with enforced evidence grounding and temporal consistency, enabling the construction of the Egocentric2Embodiment dataset (E2E-3M) at scale. An egocentric-aware embodied brain, termed PhysBrain, is obtained by training on the E2E-3M dataset. PhysBrain exhibits substantially improved egocentric understanding, particularly for planning on EgoThink. It provides an egocentric-aware initialization that enables more sample-efficient VLA fine-tuning and higher SimplerEnv success rates (53.9\%), demonstrating effective transfer from human egocentric supervision to downstream robot control.
SpikingMamba: Towards Energy-Efficient Large Language Models via Knowledge Distillation from Mamba
Oct 06, 2025



Large Language Models (LLMs) have achieved remarkable performance across tasks but remain energy-intensive due to dense matrix operations. Spiking neural networks (SNNs) improve energy efficiency by replacing dense matrix multiplications with sparse accumulations. Their sparse spike activity enables efficient LLMs deployment on edge devices. However, prior SNN-based LLMs often sacrifice performance for efficiency, and recovering accuracy typically requires full pretraining, which is costly and impractical. To address this, we propose SpikingMamba, an energy-efficient SNN-based LLMs distilled from Mamba that improves energy efficiency with minimal accuracy sacrifice. SpikingMamba integrates two key components: (a) TI-LIF, a ternary-integer spiking neuron that preserves semantic polarity through signed multi-level spike representations. (b) A training-exclusive Smoothed Gradient Compensation (SGC) path mitigating quantization loss while preserving spike-driven efficiency. We employ a single-stage distillation strategy to transfer the zero-shot ability of pretrained Mamba and further enhance it via reinforcement learning (RL). Experiments show that SpikingMamba-1.3B achieves a 4.76$\times$ energy benefit, with only a 4.78\% zero-shot accuracy gap compared to the original Mamba, and achieves a further 2.55\% accuracy improvement after RL.
Event-Based Eye Tracking. 2025 Event-based Vision Workshop
Apr 25, 2025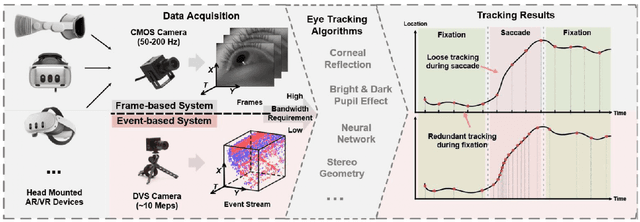
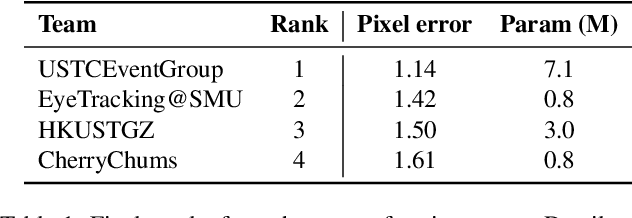
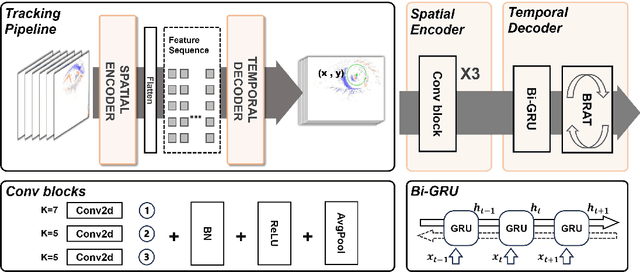

This survey serves as a review for the 2025 Event-Based Eye Tracking Challenge organized as part of the 2025 CVPR event-based vision workshop. This challenge focuses on the task of predicting the pupil center by processing event camera recorded eye movement. We review and summarize the innovative methods from teams rank the top in the challenge to advance future event-based eye tracking research. In each method, accuracy, model size, and number of operations are reported. In this survey, we also discuss event-based eye tracking from the perspective of hardware design.
Exploring Temporal Dynamics in Event-based Eye Tracker
Mar 31, 2025



Eye-tracking is a vital technology for human-computer interaction, especially in wearable devices such as AR, VR, and XR. The realization of high-speed and high-precision eye-tracking using frame-based image sensors is constrained by their limited temporal resolution, which impairs the accurate capture of rapid ocular dynamics, such as saccades and blinks. Event cameras, inspired by biological vision systems, are capable of perceiving eye movements with extremely low power consumption and ultra-high temporal resolution. This makes them a promising solution for achieving high-speed, high-precision tracking with rich temporal dynamics. In this paper, we propose TDTracker, an effective eye-tracking framework that captures rapid eye movements by thoroughly modeling temporal dynamics from both implicit and explicit perspectives. TDTracker utilizes 3D convolutional neural networks to capture implicit short-term temporal dynamics and employs a cascaded structure consisting of a Frequency-aware Module, GRU, and Mamba to extract explicit long-term temporal dynamics. Ultimately, a prediction heatmap is used for eye coordinate regression. Experimental results demonstrate that TDTracker achieves state-of-the-art (SOTA) performance on the synthetic SEET dataset and secured Third place in the CVPR event-based eye-tracking challenge 2025. Our code is available at https://github.com/rhwxmx/TDTracker.
ClearSight: Human Vision-Inspired Solutions for Event-Based Motion Deblurring
Jan 27, 2025



Motion deblurring addresses the challenge of image blur caused by camera or scene movement. Event cameras provide motion information that is encoded in the asynchronous event streams. To efficiently leverage the temporal information of event streams, we employ Spiking Neural Networks (SNNs) for motion feature extraction and Artificial Neural Networks (ANNs) for color information processing. Due to the non-uniform distribution and inherent redundancy of event data, existing cross-modal feature fusion methods exhibit certain limitations. Inspired by the visual attention mechanism in the human visual system, this study introduces a bioinspired dual-drive hybrid network (BDHNet). Specifically, the Neuron Configurator Module (NCM) is designed to dynamically adjusts neuron configurations based on cross-modal features, thereby focusing the spikes in blurry regions and adapting to varying blurry scenarios dynamically. Additionally, the Region of Blurry Attention Module (RBAM) is introduced to generate a blurry mask in an unsupervised manner, effectively extracting motion clues from the event features and guiding more accurate cross-modal feature fusion. Extensive subjective and objective evaluations demonstrate that our method outperforms current state-of-the-art methods on both synthetic and real-world datasets.