 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Text-to-Image Diffusion Models for Unsupervised Visual Object Tracking
May 26, 2026Unsupervised visual object tracking is a challenging task that requires following arbitrary targets in videos without training on ground-truth annotations. Despite considerable progress, existing state-of-the-art unsupervised trackers often struggle in scenarios that demand fine-grained understanding of semantic and visual structural information within video frames. Text-to-image diffusion models are well known for their ability to generate images that accurately reflect the semantics and structures described in the input prompt, demonstrating a strong grasp of visual semantics and structures. Building on this capability, we approach the unsupervised tracking from a new perspective by exploiting the rich semantic knowledge encoded in pretrained text-to-image diffusion models. To adapt the diffusion models, which are originally developed for image generation, to the tracking task, we reinterpret the models as a bridge between text and image modalities. This connection is realized through the cross-attention mechanism: when both text and an image are input into the models, they highlight the regions of the image that are semantically aligned with the text in the cross-attention maps. We therefore learn a prompt that represents the tracking target and activates its corresponding region in the cross-attention map for each frame, which enables object tracking with the diffusion model. Specifically, our method Diff-Tracking is composed of two main components: an initial prompt learner and an online prompt updater. The initial prompt learner generates a prompt that captures the target object in the first frame, allowing the diffusion model to identify the target. The online prompt updater refines the prompt based on motion information, enabling consistent tracking across video frames. We evaluate our approach on six challenging tracking datasets demonstrate the effectiveness of our approach.
Lens Privacy Sealing: A New Benchmark and Method for Physical Privacy-Preserving Action Recognition
May 21, 2026RGB camera-based surveillance systems enable human action recognition for public safety and healthcare, yet raise serious privacy concerns. Existing methods rely on post-capture algorithms, which fail to protect privacy during data acquisition. We propose Lens Privacy Sealing (LPS), a simple hardware solution that physically obscures camera lenses with adjustable laminating film, providing pre-sensor privacy protection at minimal cost. Unlike software methods or expensive engineered optics, LPS achieves strong privacy through stochastic multi-layer scattering that is physically irreversible. We introduce the P$^3$AR dataset for privacy-preserving action recognition, featuring both large-scale replay-captured (P$^3$AR-NTU, 114K videos) and real-world collected (P$^3$AR-PKU) subsets with privacy attribute annotations. To handle video degradation from LPS, we propose MSPNet, a single-stage framework incorporating Inter-Frame Noise Suppressor (IFNS) and Cross-Frame Semantic Aggregator (CFSA), enhanced by contrastive language-image pre-training for robust semantic extraction. Extensive experiments demonstrate that MSPNet with IFNS and CFSA nearly doubles action recognition accuracy compared to baseline methods while suppressing identity recognition to low levels. Comprehensive validation shows LPS achieves a superior privacy-utility trade-off compared to state-of-the-art hardware methods, resists reconstruction attacks including PSF inversion and data-driven recovery, and generalizes robustly across optical configurations and challenging environments. Code is available at https://github.com/wangzy01/MSPNet.
Chain-of-Look Spatial Reasoning for Dense Surgical Instrument Counting
Feb 11, 2026Accurate counting of surgical instruments in Operating Rooms (OR) is a critical prerequisite for ensuring patient safety during surgery. Despite recent progress of large visual-language models and agentic AI, accurately counting such instruments remains highly challenging, particularly in dense scenarios where instruments are tightly clustered. To address this problem, we introduce Chain-of-Look, a novel visual reasoning framework that mimics the sequential human counting process by enforcing a structured visual chain, rather than relying on classic object detection which is unordered. This visual chain guides the model to count along a coherent spatial trajectory, improving accuracy in complex scenes. To further enforce the physical plausibility of the visual chain, we introduce the neighboring loss function, which explicitly models the spatial constraints inherent to densely packed surgical instruments. We also present SurgCount-HD, a new dataset comprising 1,464 high-density surgical instrument images. Extensive experiments demonstrate that our method outperforms state-of-the-art approaches for counting (e.g., CountGD, REC) as well as Multimodality Large Language Models (e.g., Qwen, ChatGPT) in the challenging task of dense surgical instrument counting.
Language-Guided Transformer Tokenizer for Human Motion Generation
Feb 09, 2026In this paper, we focus on motion discrete tokenization, which converts raw motion into compact discrete tokens--a process proven crucial for efficient motion generation. In this paradigm, increasing the number of tokens is a common approach to improving motion reconstruction quality, but more tokens make it more difficult for generative models to learn. To maintain high reconstruction quality while reducing generation complexity, we propose leveraging language to achieve efficient motion tokenization, which we term Language-Guided Tokenization (LG-Tok). LG-Tok aligns natural language with motion at the tokenization stage, yielding compact, high-level semantic representations. This approach not only strengthens both tokenization and detokenization but also simplifies the learning of generative models. Furthermore, existing tokenizers predominantly adopt convolutional architectures, whose local receptive fields struggle to support global language guidance. To this end, we propose a Transformer-based Tokenizer that leverages attention mechanisms to enable effective alignment between language and motion. Additionally, we design a language-drop scheme, in which language conditions are randomly removed during training, enabling the detokenizer to support language-free guidance during generation. On the HumanML3D and Motion-X generation benchmarks, LG-Tok achieves Top-1 scores of 0.542 and 0.582, outperforming state-of-the-art methods (MARDM: 0.500 and 0.528), and with FID scores of 0.057 and 0.088, respectively, versus 0.114 and 0.147. LG-Tok-mini uses only half the tokens while maintaining competitive performance (Top-1: 0.521/0.588, FID: 0.085/0.071), validating the efficiency of our semantic representations.
CamReasoner: Reinforcing Camera Movement Understanding via Structured Spatial Reasoning
Jan 30, 2026Understanding camera dynamics is a fundamental pillar of video spatial intelligence. However, existing multimodal models predominantly treat this task as a black-box classification, often confusing physically distinct motions by relying on superficial visual patterns rather than geometric cues. We present CamReasoner, a framework that reformulates camera movement understanding as a structured inference process to bridge the gap between perception and cinematic logic. Our approach centers on the Observation-Thinking-Answer (O-T-A) paradigm, which compels the model to decode spatio-temporal cues such as trajectories and view frustums within an explicit reasoning block. To instill this capability, we construct a Large-scale Inference Trajectory Suite comprising 18k SFT reasoning chains and 38k RL feedback samples. Notably, we are the first to employ RL for logical alignment in this domain, ensuring motion inferences are grounded in physical geometry rather than contextual guesswork. By applying Reinforcement Learning to the Observation-Think-Answer (O-T-A) reasoning paradigm, CamReasoner effectively suppresses hallucinations and achieves state-of-the-art performance across multiple benchmarks.
PoseMoE: Mixture-of-Experts Network for Monocular 3D Human Pose Estimation
Dec 18, 2025The lifting-based methods have dominated monocular 3D human pose estimation by leveraging detected 2D poses as intermediate representations. The 2D component of the final 3D human pose benefits from the detected 2D poses, whereas its depth counterpart must be estimated from scratch. The lifting-based methods encode the detected 2D pose and unknown depth in an entangled feature space, explicitly introducing depth uncertainty to the detected 2D pose, thereby limiting overall estimation accuracy. This work reveals that the depth representation is pivotal for the estimation process. Specifically, when depth is in an initial, completely unknown state, jointly encoding depth features with 2D pose features is detrimental to the estimation process. In contrast, when depth is initially refined to a more dependable state via network-based estimation, encoding it together with 2D pose information is beneficial. To address this limitation, we present a Mixture-of-Experts network for monocular 3D pose estimation named PoseMoE. Our approach introduces: (1) A mixture-of-experts network where specialized expert modules refine the well-detected 2D pose features and learn the depth features. This mixture-of-experts design disentangles the feature encoding process for 2D pose and depth, therefore reducing the explicit influence of uncertain depth features on 2D pose features. (2) A cross-expert knowledge aggregation module is proposed to aggregate cross-expert spatio-temporal contextual information. This step enhances features through bidirectional mapping between 2D pose and depth. Extensive experiments show that our proposed PoseMoE outperforms the conventional lifting-based methods on three widely used datasets: Human3.6M, MPI-INF-3DHP, and 3DPW.
UST-SSM: Unified Spatio-Temporal State Space Models for Point Cloud Video Modeling
Aug 20, 2025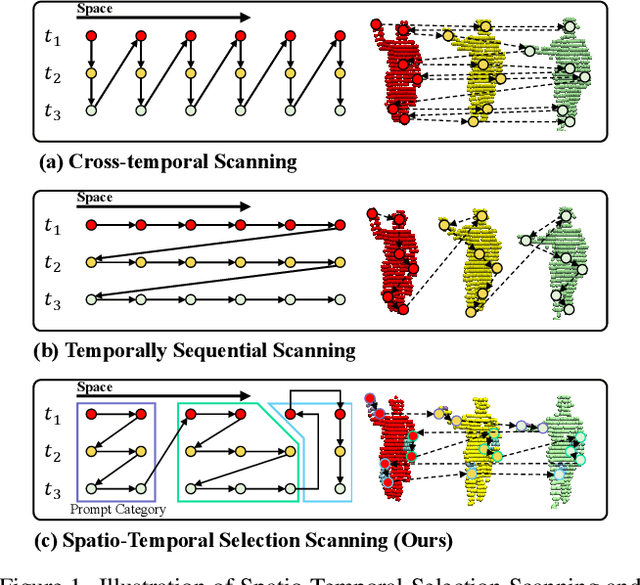
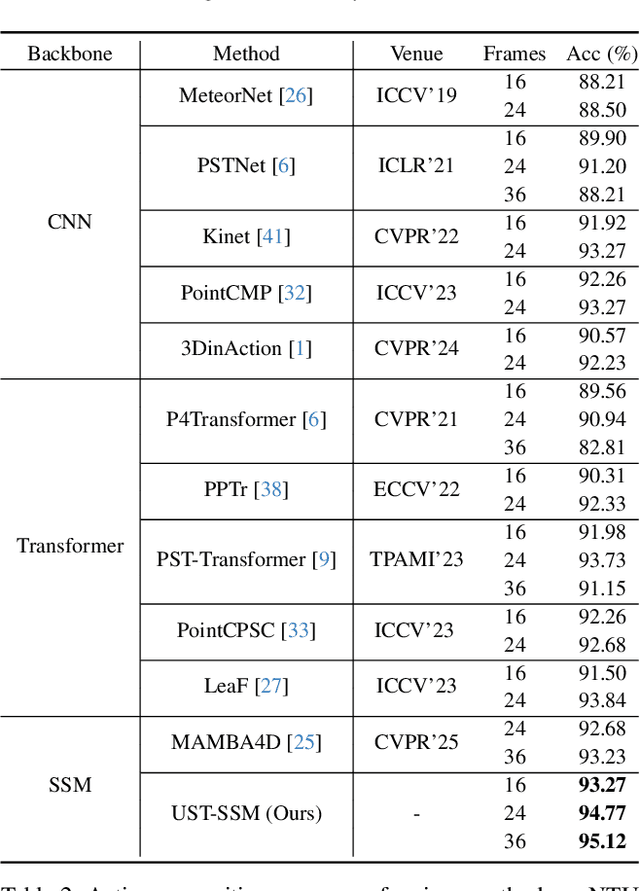
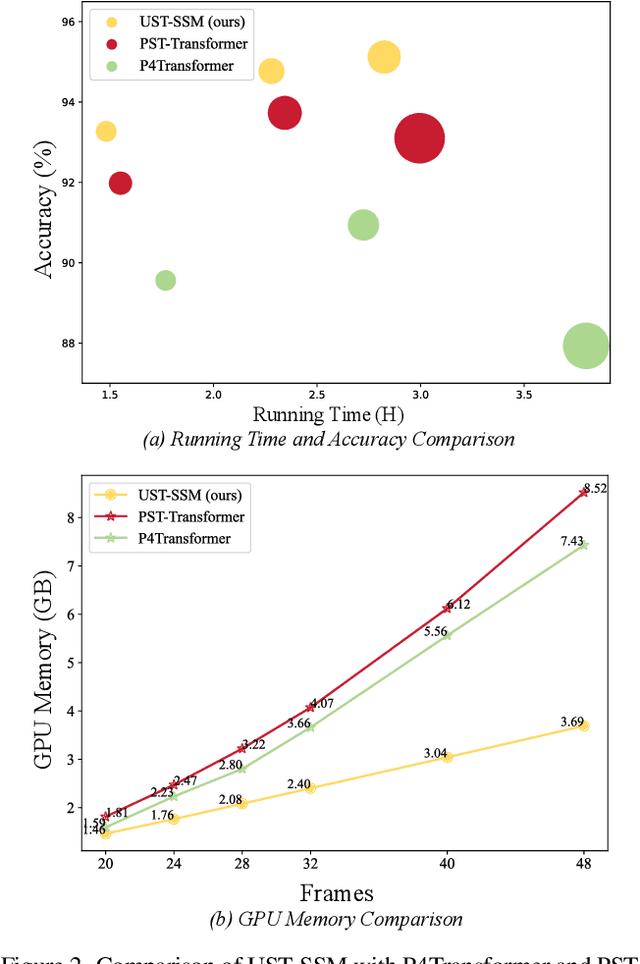
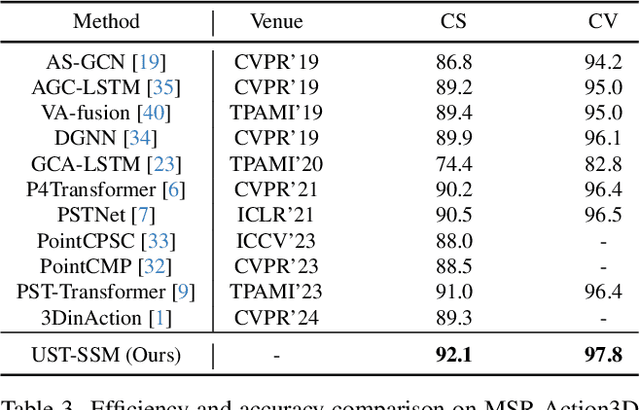
Point cloud videos capture dynamic 3D motion while reducing the effects of lighting and viewpoint variations, making them highly effective for recognizing subtle and continuous human actions. Although Selective State Space Models (SSMs) have shown good performance in sequence modeling with linear complexity, the spatio-temporal disorder of point cloud videos hinders their unidirectional modeling when directly unfolding the point cloud video into a 1D sequence through temporally sequential scanning. To address this challenge, we propose the Unified Spatio-Temporal State Space Model (UST-SSM), which extends the latest advancements in SSMs to point cloud videos. Specifically, we introduce Spatial-Temporal Selection Scanning (STSS), which reorganizes unordered points into semantic-aware sequences through prompt-guided clustering, thereby enabling the effective utilization of points that are spatially and temporally distant yet similar within the sequence. For missing 4D geometric and motion details, Spatio-Temporal Structure Aggregation (STSA) aggregates spatio-temporal features and compensates. To improve temporal interaction within the sampled sequence, Temporal Interaction Sampling (TIS) enhances fine-grained temporal dependencies through non-anchor frame utilization and expanded receptive fields. Experimental results on the MSR-Action3D, NTU RGB+D, and Synthia 4D datasets validate the effectiveness of our method. Our code is available at https://github.com/wangzy01/UST-SSM.
PP-Motion: Physical-Perceptual Fidelity Evaluation for Human Motion Generation
Aug 11, 2025Human motion generation has found widespread applications in AR/VR, film, sports, and medical rehabilitation, offering a cost-effective alternative to traditional motion capture systems. However, evaluating the fidelity of such generated motions is a crucial, multifaceted task. Although previous approaches have attempted at motion fidelity evaluation using human perception or physical constraints, there remains an inherent gap between human-perceived fidelity and physical feasibility. Moreover, the subjective and coarse binary labeling of human perception further undermines the development of a robust data-driven metric. We address these issues by introducing a physical labeling method. This method evaluates motion fidelity by calculating the minimum modifications needed for a motion to align with physical laws. With this approach, we are able to produce fine-grained, continuous physical alignment annotations that serve as objective ground truth. With these annotations, we propose PP-Motion, a novel data-driven metric to evaluate both physical and perceptual fidelity of human motion. To effectively capture underlying physical priors, we employ Pearson's correlation loss for the training of our metric. Additionally, by incorporating a human-based perceptual fidelity loss, our metric can capture fidelity that simultaneously considers both human perception and physical alignment. Experimental results demonstrate that our metric, PP-Motion, not only aligns with physical laws but also aligns better with human perception of motion fidelity than previous work.
Recognizing Actions from Robotic View for Natural Human-Robot Interaction
Jul 30, 2025



Natural Human-Robot Interaction (N-HRI) requires robots to recognize human actions at varying distances and states, regardless of whether the robot itself is in motion or stationary. This setup is more flexible and practical than conventional human action recognition tasks. However, existing benchmarks designed for traditional action recognition fail to address the unique complexities in N-HRI due to limited data, modalities, task categories, and diversity of subjects and environments. To address these challenges, we introduce ACTIVE (Action from Robotic View), a large-scale dataset tailored specifically for perception-centric robotic views prevalent in mobile service robots. ACTIVE comprises 30 composite action categories, 80 participants, and 46,868 annotated video instances, covering both RGB and point cloud modalities. Participants performed various human actions in diverse environments at distances ranging from 3m to 50m, while the camera platform was also mobile, simulating real-world scenarios of robot perception with varying camera heights due to uneven ground. This comprehensive and challenging benchmark aims to advance action and attribute recognition research in N-HRI. Furthermore, we propose ACTIVE-PC, a method that accurately perceives human actions at long distances using Multilevel Neighborhood Sampling, Layered Recognizers, Elastic Ellipse Query, and precise decoupling of kinematic interference from human actions. Experimental results demonstrate the effectiveness of ACTIVE-PC. Our code is available at: https://github.com/wangzy01/ACTIVE-Action-from-Robotic-View.
$A^2R^2$: Advancing Img2LaTeX Conversion via Visual Reasoning with Attention-Guided Refinement
Jul 28, 2025Img2LaTeX is a practically significant task that involves converting mathematical expressions or tabular data from images into LaTeX code. In recent years, vision-language models (VLMs) have demonstrated strong performance across a variety of visual understanding tasks, owing to their generalization capabilities. While some studies have explored the use of VLMs for the Img2LaTeX task, their performance often falls short of expectations. Empirically, VLMs sometimes struggle with fine-grained visual elements, leading to inaccurate LaTeX predictions. To address this challenge, we propose $A^2R^2$: Advancing Img2LaTeX Conversion via Visual Reasoning with Attention-Guided Refinement, a framework that effectively integrates attention localization and iterative refinement within a visual reasoning framework, enabling VLMs to perform self-correction and progressively improve prediction quality. For effective evaluation, we introduce a new dataset, Img2LaTex-Hard-1K, consisting of 1,100 carefully curated and challenging examples designed to rigorously evaluate the capabilities of VLMs within this task domain. Extensive experimental results demonstrate that: (1) $A^2R^2$ significantly improves model performance across six evaluation metrics spanning both textual and visual levels, consistently outperforming other baseline methods; (2) Increasing the number of inference rounds yields notable performance gains, underscoring the potential of $A^2R^2$ in test-time scaling scenarios; (3) Ablation studies and human evaluations validate the practical effectiveness of our approach, as well as the strong synergy among its core components during inference.