 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePPAAS: PVT and Pareto Aware Analog Sizing via Goal-conditioned Reinforcement Learning
Jul 22, 2025



Device sizing is a critical yet challenging step in analog and mixed-signal circuit design, requiring careful optimization to meet diverse performance specifications. This challenge is further amplified under process, voltage, and temperature (PVT) variations, which cause circuit behavior to shift across different corners. While reinforcement learning (RL) has shown promise in automating sizing for fixed targets, training a generalized policy that can adapt to a wide range of design specifications under PVT variations requires much more training samples and resources. To address these challenges, we propose a \textbf{Goal-conditioned RL framework} that enables efficient policy training for analog device sizing across PVT corners, with strong generalization capability. To improve sample efficiency, we introduce Pareto-front Dominance Goal Sampling, which constructs an automatic curriculum by sampling goals from the Pareto frontier of previously achieved goals. This strategy is further enhanced by integrating Conservative Hindsight Experience Replay, which assigns relabeled goals with conservative virtual rewards to stabilize training and accelerate convergence. To reduce simulation overhead, our framework incorporates a Skip-on-Fail simulation strategy, which skips full-corner simulations when nominal-corner simulation fails to meet target specifications. Experiments on benchmark circuits demonstrate $\sim$1.6$\times$ improvement in sample efficiency and $\sim$4.1$\times$ improvement in simulation efficiency compared to existing sizing methods. Code and benchmarks are publicly available at https://github.com/SeunggeunKimkr/PPAAS
A Simple Method to Reduce Off-chip Memory Accesses on Convolutional Neural Networks
Jan 28, 2019



For convolutional neural networks, a simple algorithm to reduce off-chip memory accesses is proposed by maximally utilizing on-chip memory in a neural process unit. Especially, the algorithm provides an effective way to process a module which consists of multiple branches and a merge layer. For Inception-V3 on Samsung's NPU in Exynos, our evaluation shows that the proposed algorithm makes off-chip memory accesses reduced by 1/50, and accordingly achieves 97.59 % reduction in the amount of feature-map data to be transferred from/to off-chip memory.
Convolutional Neural Network Quantization using Generalized Gamma Distribution
Oct 31, 2018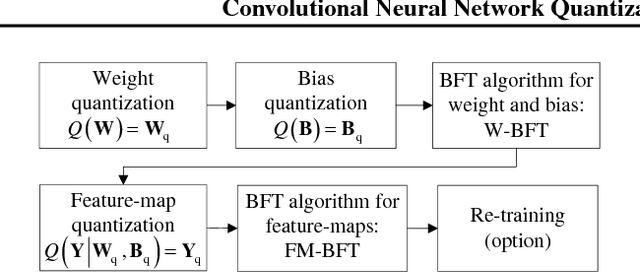
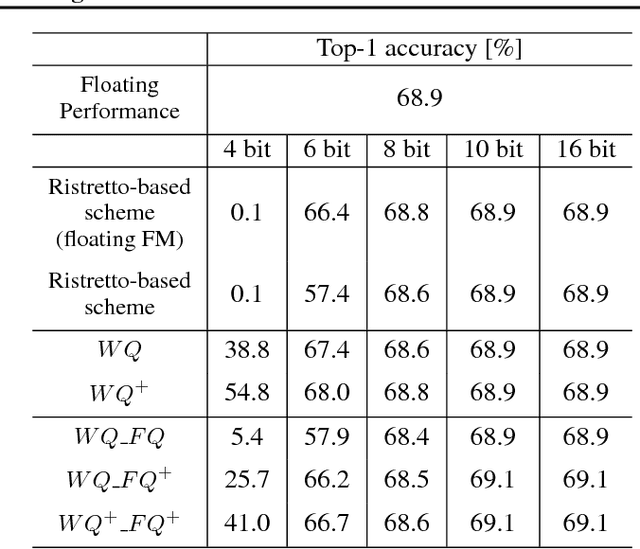
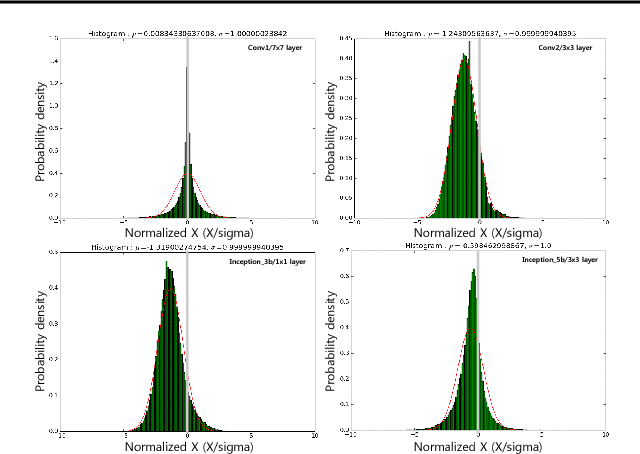
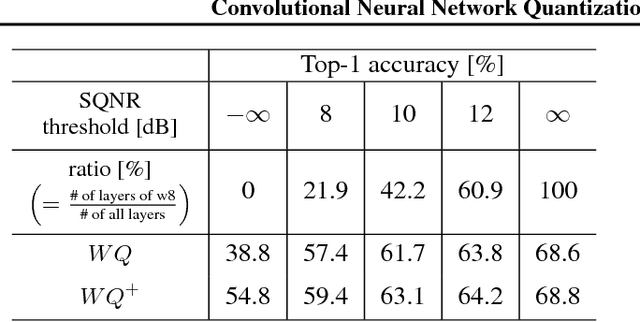
As edge applications using convolutional neural networks (CNN) models grow, it is becoming necessary to introduce dedicated hardware accelerators in which network parameters and feature-map data are represented with limited precision. In this paper we propose a novel quantization algorithm for energy-efficient deployment of the hardware accelerators. For weights and biases, the optimal bit length of the fractional part is determined so that the quantization error is minimized over their distribution. For feature-map data, meanwhile, their sample distribution is well approximated with the generalized gamma distribution (GGD), and accordingly the optimal quantization step size can be obtained through the asymptotical closed form solution of GGD. The proposed quantization algorithm has a higher signal-to-quantization-noise ratio (SQNR) than other quantization schemes previously proposed for CNNs, and even can be more improved by tuning the quantization parameters, resulting in efficient implementation of the hardware accelerators for CNNs in terms of power consumption and memory bandwidth.