 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAR: Efficient Large Language Models via Module-aware Architecture Refinement
Jan 29, 2026Large Language Models (LLMs) excel across diverse domains but suffer from high energy costs due to quadratic attention and dense Feed-Forward Network (FFN) operations. To address these issues, we propose Module-aware Architecture Refinement (MAR), a two-stage framework that integrates State Space Models (SSMs) for linear-time sequence modeling and applies activation sparsification to reduce FFN costs. In addition, to mitigate low information density and temporal mismatch in integrating Spiking Neural Networks (SNNs) with SSMs, we design the Adaptive Ternary Multi-step Neuron (ATMN) and the Spike-aware Bidirectional Distillation Strategy (SBDS). Extensive experiments demonstrate that MAR effectively restores the performance of its dense counterpart under constrained resources while substantially reducing inference energy consumption. Furthermore, it outperforms efficient models of comparable or even larger scale, underscoring its potential for building efficient and practical LLMs.
SpikingMamba: Towards Energy-Efficient Large Language Models via Knowledge Distillation from Mamba
Oct 06, 2025



Large Language Models (LLMs) have achieved remarkable performance across tasks but remain energy-intensive due to dense matrix operations. Spiking neural networks (SNNs) improve energy efficiency by replacing dense matrix multiplications with sparse accumulations. Their sparse spike activity enables efficient LLMs deployment on edge devices. However, prior SNN-based LLMs often sacrifice performance for efficiency, and recovering accuracy typically requires full pretraining, which is costly and impractical. To address this, we propose SpikingMamba, an energy-efficient SNN-based LLMs distilled from Mamba that improves energy efficiency with minimal accuracy sacrifice. SpikingMamba integrates two key components: (a) TI-LIF, a ternary-integer spiking neuron that preserves semantic polarity through signed multi-level spike representations. (b) A training-exclusive Smoothed Gradient Compensation (SGC) path mitigating quantization loss while preserving spike-driven efficiency. We employ a single-stage distillation strategy to transfer the zero-shot ability of pretrained Mamba and further enhance it via reinforcement learning (RL). Experiments show that SpikingMamba-1.3B achieves a 4.76$\times$ energy benefit, with only a 4.78\% zero-shot accuracy gap compared to the original Mamba, and achieves a further 2.55\% accuracy improvement after RL.
SNN2ANN: A Fast and Memory-Efficient Training Framework for Spiking Neural Networks
Jun 19, 2022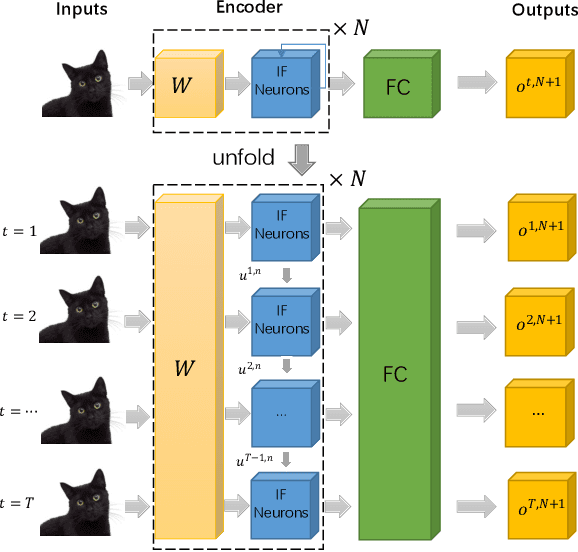
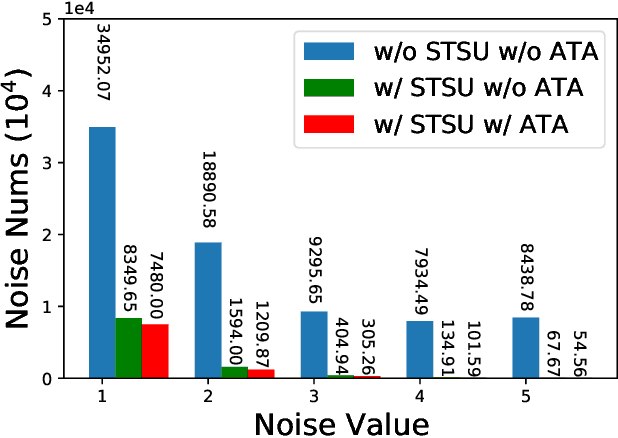
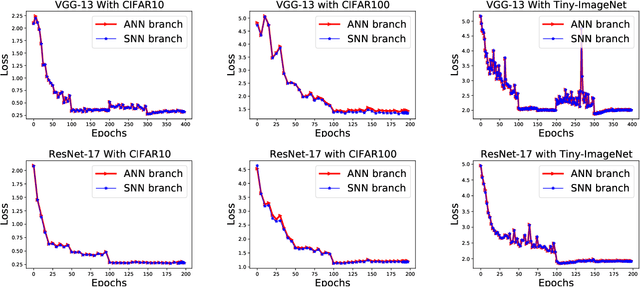
Spiking neural networks are efficient computation models for low-power environments. Spike-based BP algorithms and ANN-to-SNN (ANN2SNN) conversions are successful techniques for SNN training. Nevertheless, the spike-base BP training is slow and requires large memory costs. Though ANN2NN provides a low-cost way to train SNNs, it requires many inference steps to mimic the well-trained ANN for good performance. In this paper, we propose a SNN-to-ANN (SNN2ANN) framework to train the SNN in a fast and memory-efficient way. The SNN2ANN consists of 2 components: a) a weight sharing architecture between ANN and SNN and b) spiking mapping units. Firstly, the architecture trains the weight-sharing parameters on the ANN branch, resulting in fast training and low memory costs for SNN. Secondly, the spiking mapping units ensure that the activation values of the ANN are the spiking features. As a result, the classification error of the SNN can be optimized by training the ANN branch. Besides, we design an adaptive threshold adjustment (ATA) algorithm to address the noisy spike problem. Experiment results show that our SNN2ANN-based models perform well on the benchmark datasets (CIFAR10, CIFAR100, and Tiny-ImageNet). Moreover, the SNN2ANN can achieve comparable accuracy under 0.625x time steps, 0.377x training time, 0.27x GPU memory costs, and 0.33x spike activities of the Spike-based BP model.