 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Agents Enable User-Governed Personalization Beyond Platform Boundaries
May 10, 2026Personalization today is fundamentally platform-centric: services build user representations from the behavioral fragments they observe. Yet no platform can construct a complete picture of the user, as competitive incentives, legal constraints, user privacy concerns, and epistemic limits create persistent data barriers. This paper argues for a shift from platform-centric personalization to user-governed personalization, where only the user can integrate fragmented contexts across platforms and the offline world. The key asymmetry lies in data access: only users can aggregate their own cross-platform and offline information. Large language model (LLM) agents make such integration practically feasible for the first time by enabling reasoning over heterogeneous personal data and transforming users' cross-context information into actionable personalization capabilities. We provide proof-of-concept evidence that users equipped with cross-platform data exports and an off-the-shelf LLM agent can outperform single-platform personalization baselines. We conclude by outlining a research agenda for building scalable user-governed personalization systems.
SynPlanResearch-R1: Encouraging Tool Exploration for Deep Research with Synthetic Plans
Mar 09, 2026Research Agents enable models to gather information from the web using tools to answer user queries, requiring them to dynamically interleave internal reasoning with tool use. While such capabilities can in principle be learned via reinforcement learning with verifiable rewards (RLVR), we observe that agents often exhibit poor exploration behaviors, including premature termination and biased tool usage. As a result, RLVR alone yields limited improvements. We propose SynPlanResearch-R1, a framework that synthesizes tool-use trajectories that encourage deeper exploration to shape exploration during cold-start supervised fine-tuning, providing a strong initialization for subsequent RL. Across seven multi-hop and open-web benchmarks, \framework improves performance by up to 6.0% on Qwen3-8B and 5.8% on Qwen3-4B backbones respectively compared to SOTA baselines. Further analyses of tool-use patterns and training dynamics compared to baselines shed light on the factors underlying these gains. Our code is publicly available at https://github.com/HansiZeng/syn-plan-research.
Adaptation of Agentic AI
Dec 22, 2025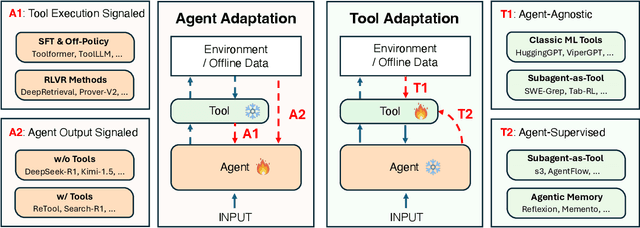
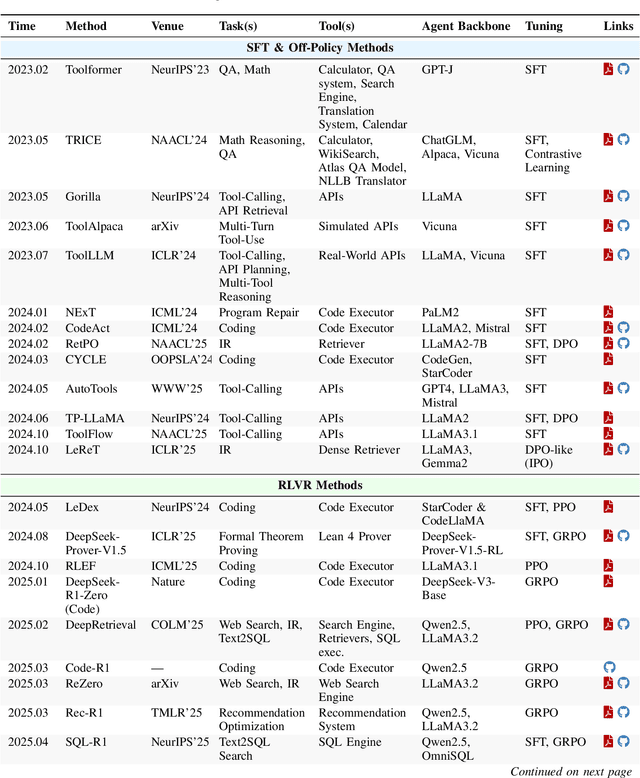
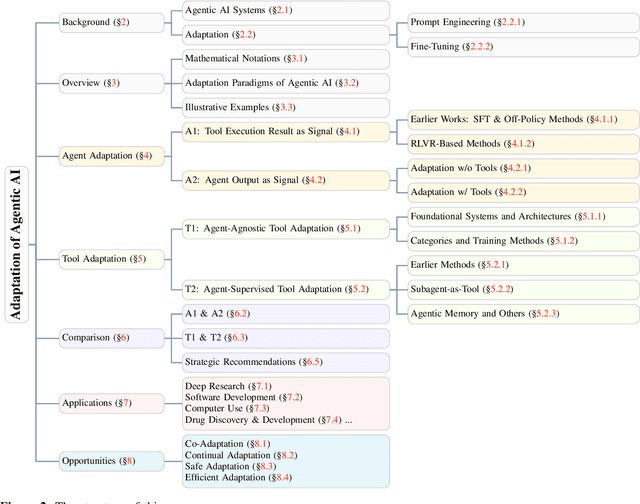
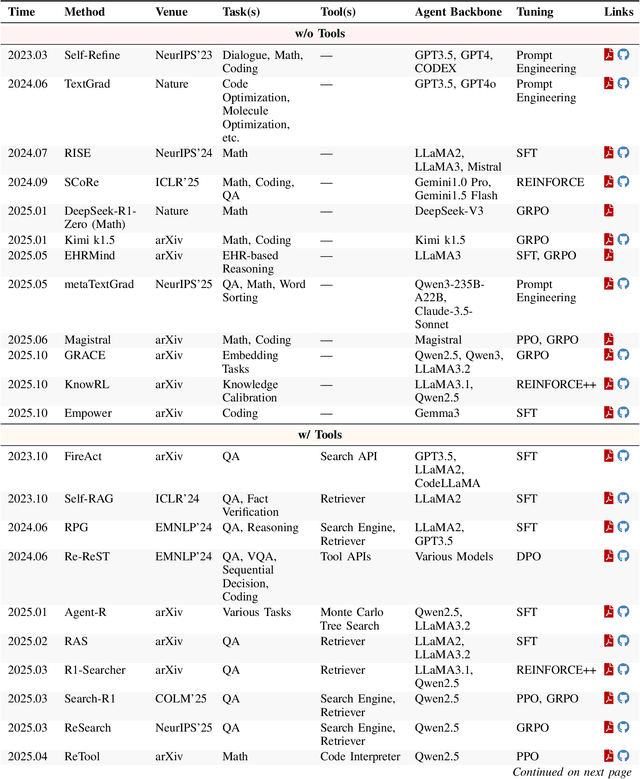
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Shop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025
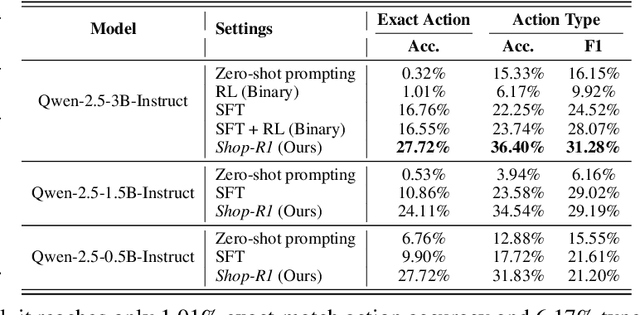
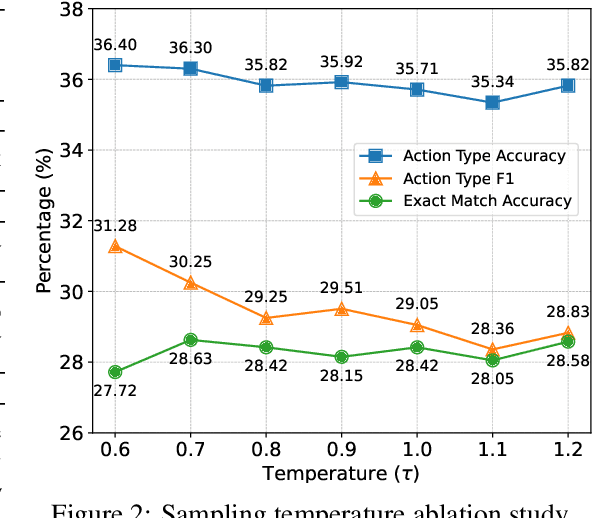
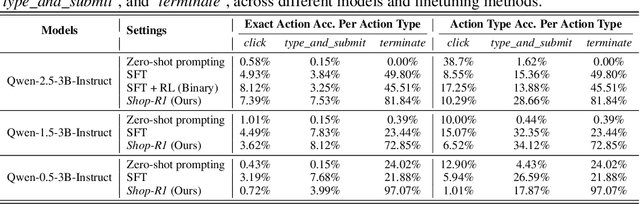
Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.
Training LLMs for EHR-Based Reasoning Tasks via Reinforcement Learning
May 30, 2025We present EHRMIND, a practical recipe for adapting large language models (LLMs) to complex clinical reasoning tasks using reinforcement learning with verifiable rewards (RLVR). While RLVR has succeeded in mathematics and coding, its application to healthcare contexts presents unique challenges due to the specialized knowledge and reasoning required for electronic health record (EHR) interpretation. Our pilot study on the MEDCALC benchmark reveals two key failure modes: (1) misapplied knowledge, where models possess relevant medical knowledge but apply it incorrectly, and (2) missing knowledge, where models lack essential domain knowledge. To address these cases, EHRMIND applies a two-stage solution: a lightweight supervised fine-tuning (SFT) warm-up that injects missing domain knowledge, stabilizes subsequent training, and encourages structured, interpretable outputs; followed by RLVR, which reinforces outcome correctness and refines the model's decision-making. We demonstrate the effectiveness of our method across diverse clinical applications, including medical calculations (MEDCALC), patient-trial matching (TREC CLINICAL TRIALS), and disease diagnosis (EHRSHOT). EHRMIND delivers consistent gains in accuracy, interpretability, and cross-task generalization. These findings offer practical guidance for applying RLVR to enhance LLM capabilities in healthcare settings.
TrialPanorama: Database and Benchmark for Systematic Review and Design of Clinical Trials
May 22, 2025Developing artificial intelligence (AI) for vertical domains requires a solid data foundation for both training and evaluation. In this work, we introduce TrialPanorama, a large-scale, structured database comprising 1,657,476 clinical trial records aggregated from 15 global sources. The database captures key aspects of trial design and execution, including trial setups, interventions, conditions, biomarkers, and outcomes, and links them to standard biomedical ontologies such as DrugBank and MedDRA. This structured and ontology-grounded design enables TrialPanorama to serve as a unified, extensible resource for a wide range of clinical trial tasks, including trial planning, design, and summarization. To demonstrate its utility, we derive a suite of benchmark tasks directly from the TrialPanorama database. The benchmark spans eight tasks across two categories: three for systematic review (study search, study screening, and evidence summarization) and five for trial design (arm design, eligibility criteria, endpoint selection, sample size estimation, and trial completion assessment). The experiments using five state-of-the-art large language models (LLMs) show that while general-purpose LLMs exhibit some zero-shot capability, their performance is still inadequate for high-stakes clinical trial workflows. We release TrialPanorama database and the benchmark to facilitate further research on AI for clinical trials.
s3: You Don't Need That Much Data to Train a Search Agent via RL
May 20, 2025Retrieval-augmented generation (RAG) systems empower large language models (LLMs) to access external knowledge during inference. Recent advances have enabled LLMs to act as search agents via reinforcement learning (RL), improving information acquisition through multi-turn interactions with retrieval engines. However, existing approaches either optimize retrieval using search-only metrics (e.g., NDCG) that ignore downstream utility or fine-tune the entire LLM to jointly reason and retrieve-entangling retrieval with generation and limiting the real search utility and compatibility with frozen or proprietary models. In this work, we propose s3, a lightweight, model-agnostic framework that decouples the searcher from the generator and trains the searcher using a Gain Beyond RAG reward: the improvement in generation accuracy over naive RAG. s3 requires only 2.4k training samples to outperform baselines trained on over 70x more data, consistently delivering stronger downstream performance across six general QA and five medical QA benchmarks.
Rec-R1: Bridging Generative Large Language Models and User-Centric Recommendation Systems via Reinforcement Learning
Mar 31, 2025



We propose Rec-R1, a general reinforcement learning framework that bridges large language models (LLMs) with recommendation systems through closed-loop optimization. Unlike prompting and supervised fine-tuning (SFT), Rec-R1 directly optimizes LLM generation using feedback from a fixed black-box recommendation model, without relying on synthetic SFT data from proprietary models such as GPT-4o. This avoids the substantial cost and effort required for data distillation. To verify the effectiveness of Rec-R1, we evaluate it on two representative tasks: product search and sequential recommendation. Experimental results demonstrate that Rec-R1 not only consistently outperforms prompting- and SFT-based methods, but also achieves significant gains over strong discriminative baselines, even when used with simple retrievers such as BM25. Moreover, Rec-R1 preserves the general-purpose capabilities of the LLM, unlike SFT, which often impairs instruction-following and reasoning. These findings suggest Rec-R1 as a promising foundation for continual task-specific adaptation without catastrophic forgetting.
Multi-Keypoint Affordance Representation for Functional Dexterous Grasping
Feb 27, 2025



Functional dexterous grasping requires precise hand-object interaction, going beyond simple gripping. Existing affordance-based methods primarily predict coarse interaction regions and cannot directly constrain the grasping posture, leading to a disconnection between visual perception and manipulation. To address this issue, we propose a multi-keypoint affordance representation for functional dexterous grasping, which directly encodes task-driven grasp configurations by localizing functional contact points. Our method introduces Contact-guided Multi-Keypoint Affordance (CMKA), leveraging human grasping experience images for weak supervision combined with Large Vision Models for fine affordance feature extraction, achieving generalization while avoiding manual keypoint annotations. Additionally, we present a Keypoint-based Grasp matrix Transformation (KGT) method, ensuring spatial consistency between hand keypoints and object contact points, thus providing a direct link between visual perception and dexterous grasping actions. Experiments on public real-world FAH datasets, IsaacGym simulation, and challenging robotic tasks demonstrate that our method significantly improves affordance localization accuracy, grasp consistency, and generalization to unseen tools and tasks, bridging the gap between visual affordance learning and dexterous robotic manipulation. The source code and demo videos will be publicly available at https://github.com/PopeyePxx/MKA.
Learning by Analogy: Enhancing Few-Shot Prompting for Math Word Problem Solving with Computational Graph-Based Retrieval
Nov 25, 2024



Large language models (LLMs) are known to struggle with complicated reasoning tasks such as math word problems (MWPs). In this paper, we present how analogy from similarly structured questions can improve LLMs' problem-solving capabilities for MWPs. Specifically, we rely on the retrieval of problems with similar computational graphs to the given question to serve as exemplars in the prompt, providing the correct reasoning path for the generation model to refer to. Empirical results across six math word problem datasets demonstrate the effectiveness of our proposed method, which achieves a significant improvement of up to 6.7 percent on average in absolute value, compared to baseline methods. These results highlight our method's potential in addressing the reasoning challenges in current LLMs.