 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSENTINEL: Failure-Driven Reinforcement Learning for Training Tool-Using Language Model Agents
Jun 11, 2026Language model agents are increasingly effective in solving realistic tasks through multi-turn tool use. However, training reliable tool-using agents remains challenging in practice. While reinforcement learning provides an on-policy paradigm for improving agents from their own environment interactions, its effectiveness depends heavily on the training task distribution. When tasks are fixed before training, the task distribution can become increasingly mismatched with the policy's evolving capabilities, causing many rollouts to be spent on uninformative tasks. We propose SENTINEL, a failure-driven reinforcement learning framework that turns the Solver's rollout failures into targeted training tasks. SENTINEL follows a Controller--Proposer--Solver loop: the Controller analyzes failed trajectories and summarizes recurring error patterns, the Proposer generates executable tasks that stress these weaknesses, and the Solver is trained on the targeted tasks. On Tau2-Bench Retail with Qwen3-4B-Thinking-2507, SENTINEL improves Pass\^{}1 from 66.4 to 74.9 and outperforms RL on general synthetic tasks across Pass\^{}k metrics. These results demonstrate that model failures provide an effective and scalable source of targeted training signal for improving tool-using language model agents.
Latent Action Reparameterization for Efficient Agent Inference
May 19, 2026Large language model (LLM) agents often rely on long sequences of low-level textual actions, resulting in large effective decision horizons and high inference cost. While prior work has focused on improving inference efficiency through system-level optimizations or prompt engineering, we argue that a key bottleneck lies in the representation of the action space itself. We propose Latent Action Reparameterization (LAR), a framework that learns a compact latent action space in which each latent action corresponds to a multi-step semantic behavior. By reparameterizing agent actions into latent units, LAR enables decision making over a shorter effective horizon while preserving the expressiveness of the original action space. Unlike hand-crafted macros or hierarchical controllers, latent actions are learned from agent trajectories and integrated directly into the model, allowing both planning and execution to operate over abstract action representations. Across a range of LLM-based agent benchmarks, LAR significantly reduces the effective action horizon and improves inference efficiency under fixed compute budgets. As a consequence, our approach achieves substantial reductions in action tokens and corresponding wall-clock inference time, while maintaining or improving task success rates. These results suggest that action representation learning is a critical and underexplored factor in scaling efficient LLM agent inference, complementary to advances in model architecture and hardware.
Trajectory2Task: Training Robust Tool-Calling Agents with Synthesized Yet Verifiable Data for Complex User Intents
Jan 28, 2026Tool-calling agents are increasingly deployed in real-world customer-facing workflows. Yet most studies on tool-calling agents focus on idealized settings with general, fixed, and well-specified tasks. In real-world applications, user requests are often (1) ambiguous, (2) changing over time, or (3) infeasible due to policy constraints, and training and evaluation data that cover these diverse, complex interaction patterns remain under-represented. To bridge the gap, we present Trajectory2Task, a verifiable data generation pipeline for studying tool use at scale under three realistic user scenarios: ambiguous intent, changing intent, and infeasible intents. The pipeline first conducts multi-turn exploration to produce valid tool-call trajectories. It then converts these trajectories into user-facing tasks with controlled intent adaptations. This process yields verifiable task that support closed-loop evaluation and training. We benchmark seven state-of-the-art LLMs on the generated complex user scenario tasks and observe frequent failures. Finally, using successful trajectories obtained from task rollouts, we fine-tune lightweight LLMs and find consistent improvements across all three conditions, along with better generalization to unseen tool-use domains, indicating stronger general tool-calling ability.
See, Think, Act: Online Shopper Behavior Simulation with VLM Agents
Oct 22, 2025LLMs have recently demonstrated strong potential in simulating online shopper behavior. Prior work has improved action prediction by applying SFT on action traces with LLM-generated rationales, and by leveraging RL to further enhance reasoning capabilities. Despite these advances, current approaches rely on text-based inputs and overlook the essential role of visual perception in shaping human decision-making during web GUI interactions. In this paper, we investigate the integration of visual information, specifically webpage screenshots, into behavior simulation via VLMs, leveraging OPeRA dataset. By grounding agent decision-making in both textual and visual modalities, we aim to narrow the gap between synthetic agents and real-world users, thereby enabling more cognitively aligned simulations of online shopping behavior. Specifically, we employ SFT for joint action prediction and rationale generation, conditioning on the full interaction context, which comprises action history, past HTML observations, and the current webpage screenshot. To further enhance reasoning capabilities, we integrate RL with a hierarchical reward structure, scaled by a difficulty-aware factor that prioritizes challenging decision points. Empirically, our studies show that incorporating visual grounding yields substantial gains: the combination of text and image inputs improves exact match accuracy by more than 6% over text-only inputs. These results indicate that multi-modal grounding not only boosts predictive accuracy but also enhances simulation fidelity in visually complex environments, which captures nuances of human attention and decision-making that text-only agents often miss. Finally, we revisit the design space of behavior simulation frameworks, identify key methodological limitations, and propose future research directions toward building efficient and effective human behavior simulators.
Multi-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation
Jul 28, 2025



Nearly all human work is collaborative; thus, the evaluation of real-world NLP applications often requires multiple dimensions that align with diverse human perspectives. As real human evaluator resources are often scarce and costly, the emerging "LLM-as-a-judge" paradigm sheds light on a promising approach to leverage LLM agents to believably simulate human evaluators. Yet, to date, existing LLM-as-a-judge approaches face two limitations: persona descriptions of agents are often arbitrarily designed, and the frameworks are not generalizable to other tasks. To address these challenges, we propose MAJ-EVAL, a Multi-Agent-as-Judge evaluation framework that can automatically construct multiple evaluator personas with distinct dimensions from relevant text documents (e.g., research papers), instantiate LLM agents with the personas, and engage in-group debates with multi-agents to Generate multi-dimensional feedback. Our evaluation experiments in both the educational and medical domains demonstrate that MAJ-EVAL can generate evaluation results that better align with human experts' ratings compared with conventional automated evaluation metrics and existing LLM-as-a-judge methods.
Shop-R1: Rewarding LLMs to Simulate Human Behavior in Online Shopping via Reinforcement Learning
Jul 23, 2025
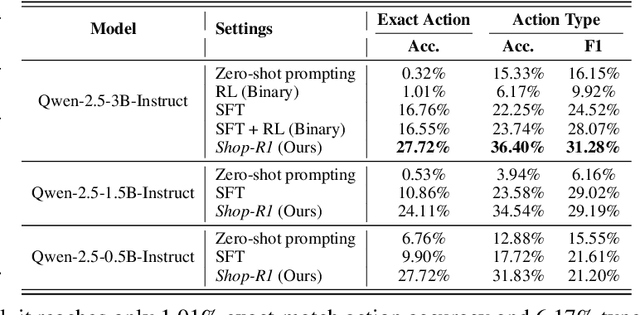
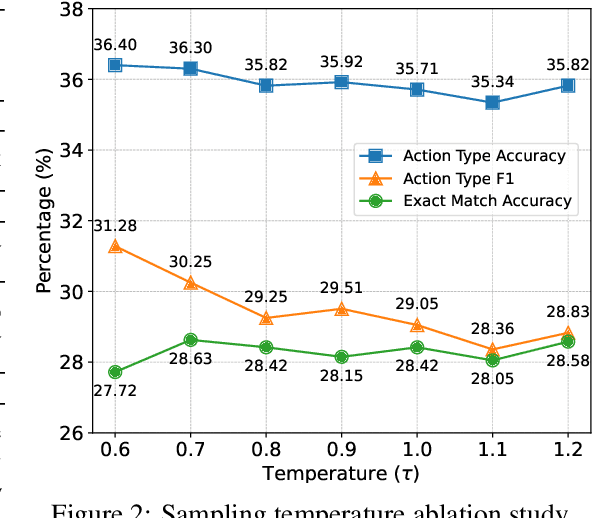
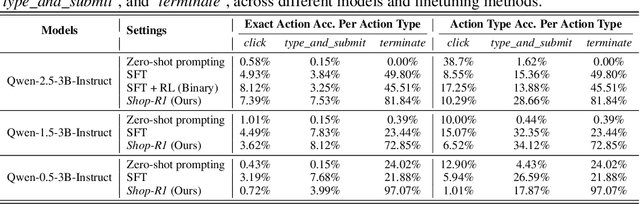
Large Language Models (LLMs) have recently demonstrated strong potential in generating 'believable human-like' behavior in web environments. Prior work has explored augmenting training data with LLM-synthesized rationales and applying supervised fine-tuning (SFT) to enhance reasoning ability, which in turn can improve downstream action prediction. However, the performance of such approaches remains inherently bounded by the reasoning capabilities of the model used to generate the rationales. In this paper, we introduce Shop-R1, a novel reinforcement learning (RL) framework aimed at enhancing the reasoning ability of LLMs for simulation of real human behavior in online shopping environments Specifically, Shop-R1 decomposes the human behavior simulation task into two stages: rationale generation and action prediction, each guided by distinct reward signals. For rationale generation, we leverage internal model signals (e.g., logit distributions) to guide the reasoning process in a self-supervised manner. For action prediction, we propose a hierarchical reward structure with difficulty-aware scaling to prevent reward hacking and enable fine-grained reward assignment. This design evaluates both high-level action types and the correctness of fine-grained sub-action details (attributes and values), rewarding outputs proportionally to their difficulty. Experimental results show that our method achieves a relative improvement of over 65% compared to the baseline.
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025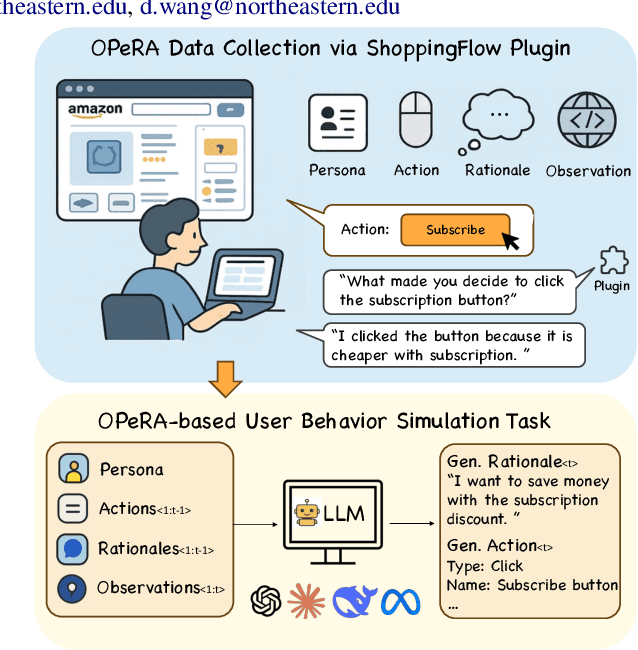
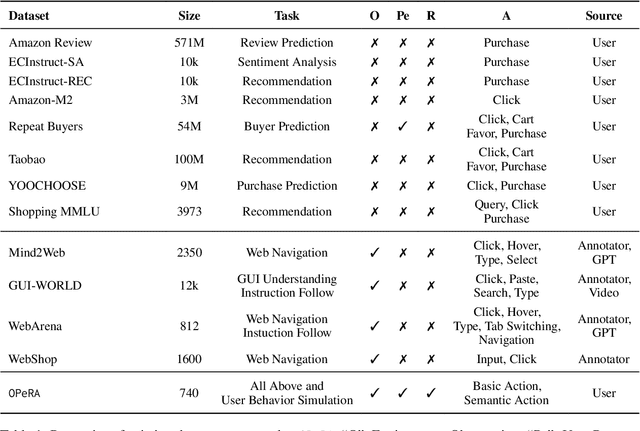
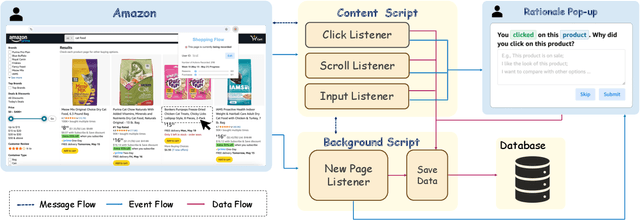
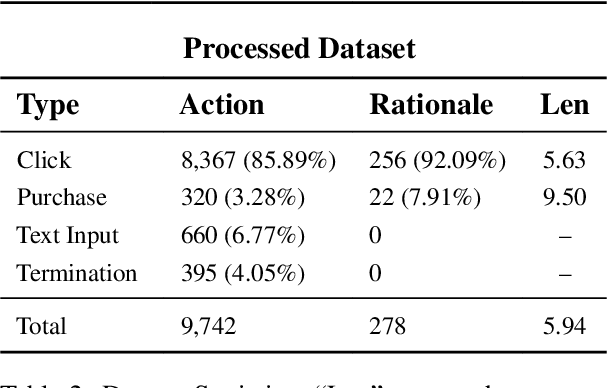
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.
UXAgent: A System for Simulating Usability Testing of Web Design with LLM Agents
Apr 13, 2025



Usability testing is a fundamental research method that user experience (UX) researchers use to evaluate and iterate a web design, but\textbf{ how to evaluate and iterate the usability testing study design } itself? Recent advances in Large Language Model-simulated Agent (\textbf{LLM Agent}) research inspired us to design \textbf{UXAgent} to support UX researchers in evaluating and reiterating their usability testing study design before they conduct the real human-subject study. Our system features a Persona Generator module, an LLM Agent module, and a Universal Browser Connector module to automatically generate thousands of simulated users to interactively test the target website. The system also provides an Agent Interview Interface and a Video Replay Interface so that the UX researchers can easily review and analyze the generated qualitative and quantitative log data. Through a heuristic evaluation, five UX researcher participants praised the innovation of our system but also expressed concerns about the future of LLM Agent usage in UX studies.
UXAgent: An LLM Agent-Based Usability Testing Framework for Web Design
Feb 18, 2025



Usability testing is a fundamental yet challenging (e.g., inflexible to iterate the study design flaws and hard to recruit study participants) research method for user experience (UX) researchers to evaluate a web design. Recent advances in Large Language Model-simulated Agent (LLM-Agent) research inspired us to design UXAgent to support UX researchers in evaluating and reiterating their usability testing study design before they conduct the real human subject study. Our system features an LLM-Agent module and a universal browser connector module so that UX researchers can automatically generate thousands of simulated users to test the target website. The results are shown in qualitative (e.g., interviewing how an agent thinks ), quantitative (e.g., # of actions), and video recording formats for UX researchers to analyze. Through a heuristic user evaluation with five UX researchers, participants praised the innovation of our system but also expressed concerns about the future of LLM Agent-assisted UX study.
Towards Robustness Analysis of E-Commerce Ranking System
Mar 07, 2024



Information retrieval (IR) is a pivotal component in various applications. Recent advances in machine learning (ML) have enabled the integration of ML algorithms into IR, particularly in ranking systems. While there is a plethora of research on the robustness of ML-based ranking systems, these studies largely neglect commercial e-commerce systems and fail to establish a connection between real-world and manipulated query relevance. In this paper, we present the first systematic measurement study on the robustness of e-commerce ranking systems. We define robustness as the consistency of ranking outcomes for semantically identical queries. To quantitatively analyze robustness, we propose a novel metric that considers both ranking position and item-specific information that are absent in existing metrics. Our large-scale measurement study with real-world data from e-commerce retailers reveals an open opportunity to measure and improve robustness since semantically identical queries often yield inconsistent ranking results. Based on our observations, we propose several solution directions to enhance robustness, such as the use of Large Language Models. Note that the issue of robustness discussed herein does not constitute an error or oversight. Rather, in scenarios where there exists a vast array of choices, it is feasible to present a multitude of products in various permutations, all of which could be equally appealing. However, this extensive selection may lead to customer confusion. As e-commerce retailers use various techniques to improve the quality of search results, we hope that this research offers valuable guidance for measuring the robustness of the ranking systems.