 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdSum: Two-stream Audio-visual Summarization for Automated Video Advertisement Clipping
Oct 30, 2025Advertisers commonly need multiple versions of the same advertisement (ad) at varying durations for a single campaign. The traditional approach involves manually selecting and re-editing shots from longer video ads to create shorter versions, which is labor-intensive and time-consuming. In this paper, we introduce a framework for automated video ad clipping using video summarization techniques. We are the first to frame video clipping as a shot selection problem, tailored specifically for advertising. Unlike existing general video summarization methods that primarily focus on visual content, our approach emphasizes the critical role of audio in advertising. To achieve this, we develop a two-stream audio-visual fusion model that predicts the importance of video frames, where importance is defined as the likelihood of a frame being selected in the firm-produced short ad. To address the lack of ad-specific datasets, we present AdSum204, a novel dataset comprising 102 pairs of 30-second and 15-second ads from real advertising campaigns. Extensive experiments demonstrate that our model outperforms state-of-the-art methods across various metrics, including Average Precision, Area Under Curve, Spearman, and Kendall.
OPeRA: A Dataset of Observation, Persona, Rationale, and Action for Evaluating LLMs on Human Online Shopping Behavior Simulation
Jun 05, 2025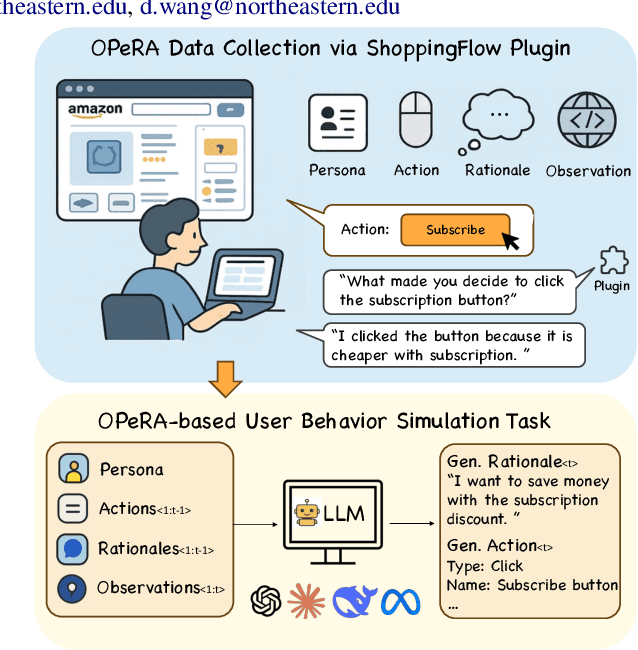
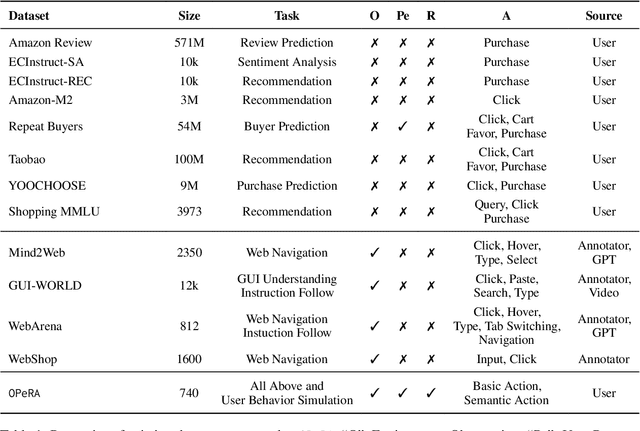
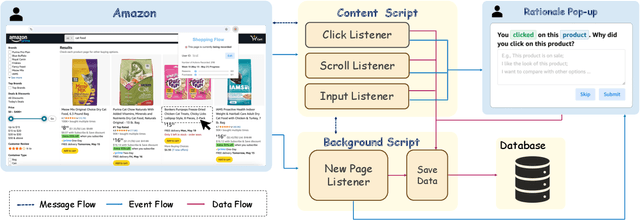
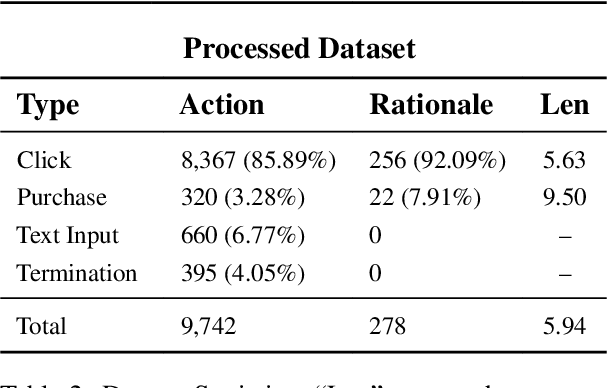
Can large language models (LLMs) accurately simulate the next web action of a specific user? While LLMs have shown promising capabilities in generating ``believable'' human behaviors, evaluating their ability to mimic real user behaviors remains an open challenge, largely due to the lack of high-quality, publicly available datasets that capture both the observable actions and the internal reasoning of an actual human user. To address this gap, we introduce OPERA, a novel dataset of Observation, Persona, Rationale, and Action collected from real human participants during online shopping sessions. OPERA is the first public dataset that comprehensively captures: user personas, browser observations, fine-grained web actions, and self-reported just-in-time rationales. We developed both an online questionnaire and a custom browser plugin to gather this dataset with high fidelity. Using OPERA, we establish the first benchmark to evaluate how well current LLMs can predict a specific user's next action and rationale with a given persona and <observation, action, rationale> history. This dataset lays the groundwork for future research into LLM agents that aim to act as personalized digital twins for human.