 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFocus When Necessary: Adaptive Routing and Collaborative Grounding for Training-Free Visual Grounding
Jun 15, 2026While Multimodal Large Language Models (MLLMs) excel in cross-modal reasoning, they often struggle to perceive fine-grained details in complex high-resolution images. Recent training-free methods address this through image scaling and localized cropping. However, applying these manipulations indiscriminately introduces computational redundancy for simple queries and can degrade accuracy by truncating essential global context or introducing irrelevant background noise. To this end, we propose LazyMCoT, a dynamic and training-free framework that adaptively allocates visual grounding efforts based on sample difficulty. The framework features an Adaptive Routing mechanism that evaluates predictive uncertainty using first-token statistics from a single forward pass. This efficiently bypasses confident cases while ensuring the recall of difficult samples via conformal calibration. For these challenging cases, a Collaborative Grounding module integrates the inherent cross-modal attention of the model with an external visual expert through a two-stage refinement process. This refinement process generates a precise localized display to recover small or occluded targets. Extensive experiments across diverse benchmarks demonstrate that LazyMCoT rivals training-based approaches by simultaneously improving reasoning accuracy and reducing average inference latency. Our code is availble at https://github.com/TencentBAC/LazyMCoT.
Conan-embedding-v3: Fusing Modality-Specific Models for Omni-Modal Embedding
Jun 08, 2026Omni-modal retrieval promises a single embedding space for text, image, video, document, and audio inputs, but building such a unified retriever is difficult since these modalities differ in data distribution, architecture, and optimization dynamics. In this work, we present Conan-embedding-v3, a decouple--fuse--recover framework for omni-modal retrieval. Conan-embedding-v3 first trains modality specialists independently and fuses their task vectors into a single dense backbone, a strategy we call Decoupled Specialist Fusion. We show that this fusion composes visual, video, and document retrieval capabilities, but also exposes a failure mode for projector-based modalities: when audio is attached through an external encoder and projector, fusing the backbone leaves the projector calibrated to the audio-specialist backbone, causing a large audio retrieval regression despite copying all audio-specific modules unchanged. We call this failure Projector Drift. To repair it, Conan-embedding-v3 applies Projector Recovery (i.e., full-parameter fine-tuning of the projector while keeping the backbone frozen) followed by balanced multi-modal rehearsal. The resulting model supports these retrieval pathways in one backbone, achieving 74.9 scores on MMEB while obtaining 55.61 on the 30-task MAEB audio suite.
Lens Privacy Sealing: A New Benchmark and Method for Physical Privacy-Preserving Action Recognition
May 21, 2026RGB camera-based surveillance systems enable human action recognition for public safety and healthcare, yet raise serious privacy concerns. Existing methods rely on post-capture algorithms, which fail to protect privacy during data acquisition. We propose Lens Privacy Sealing (LPS), a simple hardware solution that physically obscures camera lenses with adjustable laminating film, providing pre-sensor privacy protection at minimal cost. Unlike software methods or expensive engineered optics, LPS achieves strong privacy through stochastic multi-layer scattering that is physically irreversible. We introduce the P$^3$AR dataset for privacy-preserving action recognition, featuring both large-scale replay-captured (P$^3$AR-NTU, 114K videos) and real-world collected (P$^3$AR-PKU) subsets with privacy attribute annotations. To handle video degradation from LPS, we propose MSPNet, a single-stage framework incorporating Inter-Frame Noise Suppressor (IFNS) and Cross-Frame Semantic Aggregator (CFSA), enhanced by contrastive language-image pre-training for robust semantic extraction. Extensive experiments demonstrate that MSPNet with IFNS and CFSA nearly doubles action recognition accuracy compared to baseline methods while suppressing identity recognition to low levels. Comprehensive validation shows LPS achieves a superior privacy-utility trade-off compared to state-of-the-art hardware methods, resists reconstruction attacks including PSF inversion and data-driven recovery, and generalizes robustly across optical configurations and challenging environments. Code is available at https://github.com/wangzy01/MSPNet.
AcceRL: A Distributed Asynchronous Reinforcement Learning and World Model Framework for Vision-Language-Action Models
Mar 19, 2026Reinforcement learning (RL) for large-scale Vision-Language-Action (VLA) models faces significant challenges in computational efficiency and data acquisition. We propose AcceRL, a fully asynchronous and decoupled RL framework designed to eliminate synchronization barriers by physically isolating training, inference, and rollouts. Crucially, AcceRL is the first to integrate a plug-and-play, trainable world model into a distributed asynchronous RL pipeline to generate virtual experiences. Experiments on the LIBERO benchmark demonstrate that AcceRL achieves state-of-the-art (SOTA) performance. Systematically, it exhibits super-linear scaling in throughput and highly efficient hardware utilization. Algorithmically, the world-model-augmented variant delivers unprecedented sample efficiency and robust training stability in complex control tasks.
Universal Skeleton Understanding via Differentiable Rendering and MLLMs
Mar 18, 2026Multimodal large language models (MLLMs) exhibit strong visual-language reasoning, yet remain confined to their native modalities and cannot directly process structured, non-visual data such as human skeletons. Existing methods either compress skeleton dynamics into lossy feature vectors for text alignment, or quantize motion into discrete tokens that generalize poorly across heterogeneous skeleton formats. We present SkeletonLLM, which achieves universal skeleton understanding by translating arbitrary skeleton sequences into the MLLM's native visual modality. At its core is DrAction, a differentiable, format-agnostic renderer that converts skeletal kinematics into compact image sequences. Because the pipeline is end-to-end differentiable, MLLM gradients can directly guide the rendering to produce task-informative visual tokens. To further enhance reasoning capabilities, we introduce a cooperative training strategy: Causal Reasoning Distillation transfers structured, step-by-step reasoning from a teacher model, while Discriminative Finetuning sharpens decision boundaries between confusable actions. SkeletonLLM demonstrates strong generalization on diverse tasks including recognition, captioning, reasoning, and cross-format transfer -- suggesting a viable path for applying MLLMs to non-native modalities. Code will be released upon acceptance.
Superman: Unifying Skeleton and Vision for Human Motion Perception and Generation
Feb 02, 2026Human motion analysis tasks, such as temporal 3D pose estimation, motion prediction, and motion in-betweening, play an essential role in computer vision. However, current paradigms suffer from severe fragmentation. First, the field is split between ``perception'' models that understand motion from video but only output text, and ``generation'' models that cannot perceive from raw visual input. Second, generative MLLMs are often limited to single-frame, static poses using dense, parametric SMPL models, failing to handle temporal motion. Third, existing motion vocabularies are built from skeleton data alone, severing the link to the visual domain. To address these challenges, we introduce Superman, a unified framework that bridges visual perception with temporal, skeleton-based motion generation. Our solution is twofold. First, to overcome the modality disconnect, we propose a Vision-Guided Motion Tokenizer. Leveraging the natural geometric alignment between 3D skeletons and visual data, this module pioneers robust joint learning from both modalities, creating a unified, cross-modal motion vocabulary. Second, grounded in this motion language, a single, unified MLLM architecture is trained to handle all tasks. This module flexibly processes diverse, temporal inputs, unifying 3D skeleton pose estimation from video (perception) with skeleton-based motion prediction and in-betweening (generation). Extensive experiments on standard benchmarks, including Human3.6M, demonstrate that our unified method achieves state-of-the-art or competitive performance across all motion tasks. This showcases a more efficient and scalable path for generative motion analysis using skeletons.
Trustworthy Evaluation of Robotic Manipulation: A New Benchmark and AutoEval Methods
Jan 26, 2026Driven by the rapid evolution of Vision-Action and Vision-Language-Action models, imitation learning has significantly advanced robotic manipulation capabilities. However, evaluation methodologies have lagged behind, hindering the establishment of Trustworthy Evaluation for these behaviors. Current paradigms rely on binary success rates, failing to address the critical dimensions of trust: Source Authenticity (i.e., distinguishing genuine policy behaviors from human teleoperation) and Execution Quality (e.g., smoothness and safety). To bridge these gaps, we propose a solution that combines the Eval-Actions benchmark and the AutoEval architecture. First, we construct the Eval-Actions benchmark to support trustworthiness analysis. Distinct from existing datasets restricted to successful human demonstrations, Eval-Actions integrates VA and VLA policy execution trajectories alongside human teleoperation data, explicitly including failure scenarios. This dataset is structured around three core supervision signals: Expert Grading (EG), Rank-Guided preferences (RG), and Chain-of-Thought (CoT). Building on this, we propose the AutoEval architecture: AutoEval leverages Spatio-Temporal Aggregation for semantic assessment, augmented by an auxiliary Kinematic Calibration Signal to refine motion smoothness; AutoEval Plus (AutoEval-P) incorporates the Group Relative Policy Optimization (GRPO) paradigm to enhance logical reasoning capabilities. Experiments show AutoEval achieves Spearman's Rank Correlation Coefficients (SRCC) of 0.81 and 0.84 under the EG and RG protocols, respectively. Crucially, the framework possesses robust source discrimination capabilities, distinguishing between policy-generated and teleoperated videos with 99.6% accuracy, thereby establishing a rigorous standard for trustworthy robotic evaluation. Our project and code are available at https://term-bench.github.io/.
Render-of-Thought: Rendering Textual Chain-of-Thought as Images for Visual Latent Reasoning
Jan 21, 2026Chain-of-Thought (CoT) prompting has achieved remarkable success in unlocking the reasoning capabilities of Large Language Models (LLMs). Although CoT prompting enhances reasoning, its verbosity imposes substantial computational overhead. Recent works often focus exclusively on outcome alignment and lack supervision on the intermediate reasoning process. These deficiencies obscure the analyzability of the latent reasoning chain. To address these challenges, we introduce Render-of-Thought (RoT), the first framework to reify the reasoning chain by rendering textual steps into images, making the latent rationale explicit and traceable. Specifically, we leverage the vision encoders of existing Vision Language Models (VLMs) as semantic anchors to align the vision embeddings with the textual space. This design ensures plug-and-play implementation without incurring additional pre-training overhead. Extensive experiments on mathematical and logical reasoning benchmarks demonstrate that our method achieves 3-4x token compression and substantial inference acceleration compared to explicit CoT. Furthermore, it maintains competitive performance against other methods, validating the feasibility of this paradigm. Our code is available at https://github.com/TencentBAC/RoT
ReSeek: A Self-Correcting Framework for Search Agents with Instructive Rewards
Oct 01, 2025



Search agents powered by Large Language Models (LLMs) have demonstrated significant potential in tackling knowledge-intensive tasks. Reinforcement learning (RL) has emerged as a powerful paradigm for training these agents to perform complex, multi-step reasoning. However, prior RL-based methods often rely on sparse or rule-based rewards, which can lead agents to commit to suboptimal or erroneous reasoning paths without the ability to recover. To address these limitations, we propose ReSeek, a novel self-correcting framework for training search agents. Our framework introduces a self-correction mechanism that empowers the agent to dynamically identify and recover from erroneous search paths during an episode. By invoking a special JUDGE action, the agent can judge the information and re-plan its search strategy. To guide this process, we design a dense, instructive process reward function, which decomposes into a correctness reward for retrieving factual information and a utility reward for finding information genuinely useful for the query. Furthermore, to mitigate the risk of data contamination in existing datasets, we introduce FictionalHot, a new and challenging benchmark with recently curated questions requiring complex reasoning. Being intuitively reasonable and practically simple, extensive experiments show that agents trained with ReSeek significantly outperform SOTA baselines in task success rate and path faithfulness.
UST-SSM: Unified Spatio-Temporal State Space Models for Point Cloud Video Modeling
Aug 20, 2025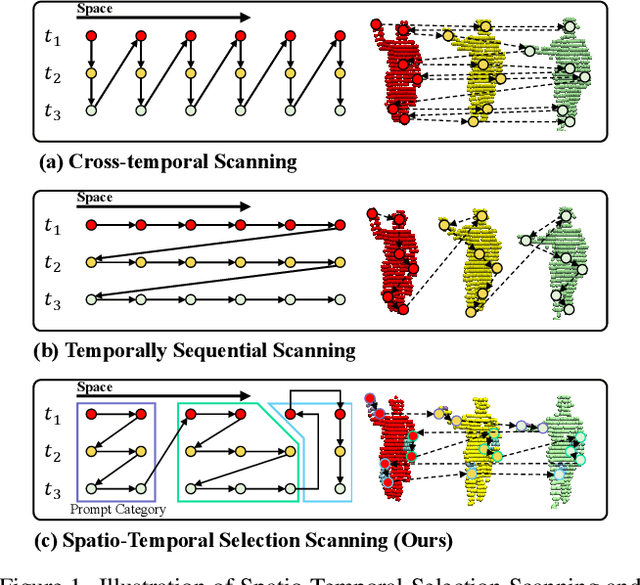
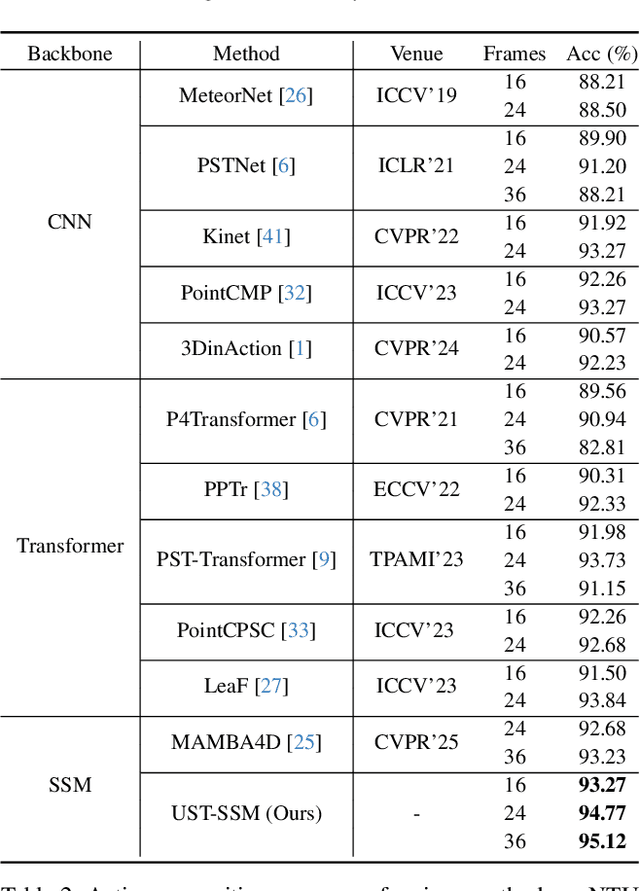
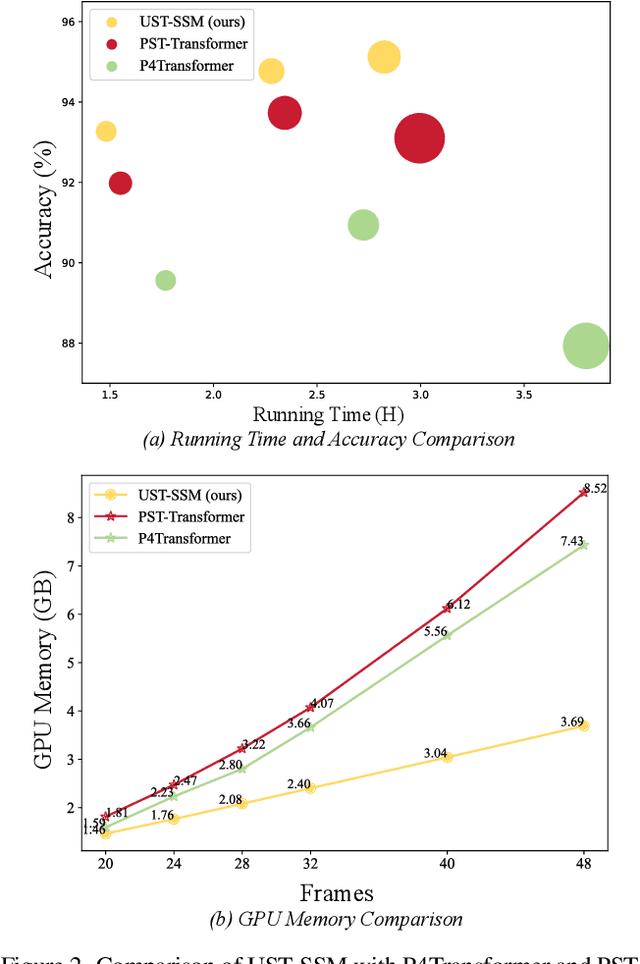
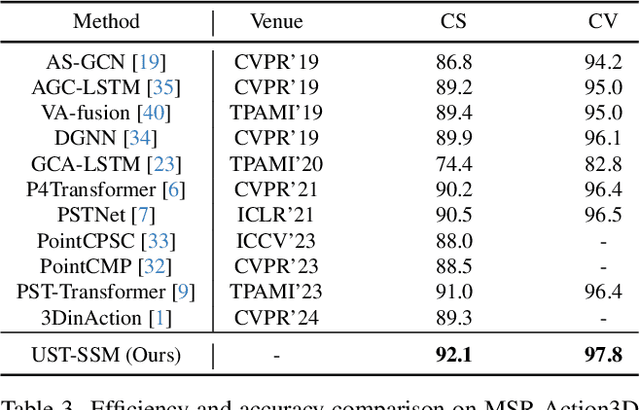
Point cloud videos capture dynamic 3D motion while reducing the effects of lighting and viewpoint variations, making them highly effective for recognizing subtle and continuous human actions. Although Selective State Space Models (SSMs) have shown good performance in sequence modeling with linear complexity, the spatio-temporal disorder of point cloud videos hinders their unidirectional modeling when directly unfolding the point cloud video into a 1D sequence through temporally sequential scanning. To address this challenge, we propose the Unified Spatio-Temporal State Space Model (UST-SSM), which extends the latest advancements in SSMs to point cloud videos. Specifically, we introduce Spatial-Temporal Selection Scanning (STSS), which reorganizes unordered points into semantic-aware sequences through prompt-guided clustering, thereby enabling the effective utilization of points that are spatially and temporally distant yet similar within the sequence. For missing 4D geometric and motion details, Spatio-Temporal Structure Aggregation (STSA) aggregates spatio-temporal features and compensates. To improve temporal interaction within the sampled sequence, Temporal Interaction Sampling (TIS) enhances fine-grained temporal dependencies through non-anchor frame utilization and expanded receptive fields. Experimental results on the MSR-Action3D, NTU RGB+D, and Synthia 4D datasets validate the effectiveness of our method. Our code is available at https://github.com/wangzy01/UST-SSM.