 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyLoVQA: Dynamic Hypernetwork-Generated Low-Rank Adaptation for Continual Visual Question Answering
May 21, 2026Continual Visual Question Answering (VQA) requires learning from non-stationary streams of visual inputs and questions while preserving past knowledge. Most prior methods adapt by updating a largely shared parameter set. This often leads to cross-level task interference, hindering accurate adaptation to the current task and object. To address this limitation, we propose HyLoVQA. It maintains a drift-resilient memory bank of anchors. The bank stores the content of visual objects and textual tasks, and they are updated using current input features. Conditioned on retrieved anchors, a hypernetwork generates lightweight Low-Rank Adaptation (LoRA) adapters. This ensures parameter efficiency, allowing the model to adapt to each task and object dynamically. Additionally, we formulate an alignment loss that aligns semantic discrepancies in the feature space with functional changes in the parameter space, thereby constraining LoRA adapters to remain focused on the current task and object. Extensive experiments on VQA v2 and NExT-QA under both standard and compositional settings demonstrate the superiority of HyLoVQA over prior state-of-the-art methods.
CocoaBench: Evaluating Unified Digital Agents in the Wild
Apr 14, 2026LLM agents now perform strongly in software engineering, deep research, GUI automation, and various other applications, while recent agent scaffolds and models are increasingly integrating these capabilities into unified systems. Yet, most evaluations still test these capabilities in isolation, which leaves a gap for more diverse use cases that require agents to combine different capabilities. We introduce CocoaBench, a benchmark for unified digital agents built from human-designed, long-horizon tasks that require flexible composition of vision, search, and coding. Tasks are specified only by an instruction and an automatic evaluation function over the final output, enabling reliable and scalable evaluation across diverse agent infrastructures. We also present CocoaAgent, a lightweight shared scaffold for controlled comparison across model backbones. Experiments show that current agents remain far from reliable on CocoaBench, with the best evaluated system achieving only 45.1% success rate. Our analysis further points to substantial room for improvement in reasoning and planning, tool use and execution, and visual grounding.
MyGram: Modality-aware Graph Transformer with Global Distribution for Multi-modal Entity Alignment
Jan 17, 2026Multi-modal entity alignment aims to identify equivalent entities between two multi-modal Knowledge graphs by integrating multi-modal data, such as images and text, to enrich the semantic representations of entities. However, existing methods may overlook the structural contextual information within each modality, making them vulnerable to interference from shallow features. To address these challenges, we propose MyGram, a modality-aware graph transformer with global distribution for multi-modal entity alignment. Specifically, we develop a modality diffusion learning module to capture deep structural contextual information within modalities and enable fine-grained multi-modal fusion. In addition, we introduce a Gram Loss that acts as a regularization constraint by minimizing the volume of a 4-dimensional parallelotope formed by multi-modal features, thereby achieving global distribution consistency across modalities. We conduct experiments on five public datasets. Results show that MyGram outperforms baseline models, achieving a maximum improvement of 4.8% in Hits@1 on FBDB15K, 9.9% on FBYG15K, and 4.3% on DBP15K.
MacVQA: Adaptive Memory Allocation and Global Noise Filtering for Continual Visual Question Answering
Jan 05, 2026Visual Question Answering (VQA) requires models to reason over multimodal information, combining visual and textual data. With the development of continual learning, significant progress has been made in retaining knowledge and adapting to new information in the VQA domain. However, current methods often struggle with balancing knowledge retention, adaptation, and robust feature representation. To address these challenges, we propose a novel framework with adaptive memory allocation and global noise filtering called MacVQA for visual question answering. MacVQA fuses visual and question information while filtering noise to ensure robust representations, and employs prototype-based memory allocation to optimize feature quality and memory usage. These designs enable MacVQA to balance knowledge acquisition, retention, and compositional generalization in continual VQA learning. Experiments on ten continual VQA tasks show that MacVQA outperforms existing baselines, achieving 43.38% average accuracy and 2.32% average forgetting on standard tasks, and 42.53% average accuracy and 3.60% average forgetting on novel composition tasks.
Let the Barbarians In: How AI Can Accelerate Systems Performance Research
Dec 22, 2025Artificial Intelligence (AI) is beginning to transform the research process by automating the discovery of new solutions. This shift depends on the availability of reliable verifiers, which AI-driven approaches require to validate candidate solutions. Research focused on improving systems performance is especially well-suited to this paradigm because system performance problems naturally admit such verifiers: candidates can be implemented in real systems or simulators and evaluated against predefined workloads. We term this iterative cycle of generation, evaluation, and refinement AI-Driven Research for Systems (ADRS). Using several open-source ADRS instances (i.e., OpenEvolve, GEPA, and ShinkaEvolve), we demonstrate across ten case studies (e.g., multi-region cloud scheduling, mixture-of-experts load balancing, LLM-based SQL, transaction scheduling) that ADRS-generated solutions can match or even outperform human state-of-the-art designs. Based on these findings, we outline best practices (e.g., level of prompt specification, amount of feedback, robust evaluation) for effectively using ADRS, and we discuss future research directions and their implications. Although we do not yet have a universal recipe for applying ADRS across all of systems research, we hope our preliminary findings, together with the challenges we identify, offer meaningful guidance for future work as researcher effort shifts increasingly toward problem formulation and strategic oversight. Note: This paper is an extension of our prior work [14]. It adds extensive evaluation across multiple ADRS frameworks and provides deeper analysis and insights into best practices.
KeenKT: Knowledge Mastery-State Disambiguation for Knowledge Tracing
Dec 21, 2025Knowledge Tracing (KT) aims to dynamically model a student's mastery of knowledge concepts based on their historical learning interactions. Most current methods rely on single-point estimates, which cannot distinguish true ability from outburst or carelessness, creating ambiguity in judging mastery. To address this issue, we propose a Knowledge Mastery-State Disambiguation for Knowledge Tracing model (KeenKT), which represents a student's knowledge state at each interaction using a Normal-Inverse-Gaussian (NIG) distribution, thereby capturing the fluctuations in student learning behaviors. Furthermore, we design an NIG-distance-based attention mechanism to model the dynamic evolution of the knowledge state. In addition, we introduce a diffusion-based denoising reconstruction loss and a distributional contrastive learning loss to enhance the model's robustness. Extensive experiments on six public datasets demonstrate that KeenKT outperforms SOTA KT models in terms of prediction accuracy and sensitivity to behavioral fluctuations. The proposed method yields the maximum AUC improvement of 5.85% and the maximum ACC improvement of 6.89%.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
Analyzing Planner Design Trade-offs for MAPF under Realistic Simulation
Dec 10, 2025Multi-Agent Path Finding (MAPF) algorithms are increasingly deployed in industrial warehouses and automated manufacturing facilities, where robots must operate reliably under real-world physical constraints. However, existing MAPF evaluation frameworks typically rely on simplified robot models, leaving a substantial gap between algorithmic benchmarks and practical performance. Recent frameworks such as SMART, incorporate kinodynamic modeling and offer the MAPF community a platform for large-scale, realistic evaluation. Building on this capability, this work investigates how key planner design choices influence performance under realistic execution settings. We systematically study three fundamental factors: (1) the relationship between solution optimality and execution performance, (2) the sensitivity of system performance to inaccuracies in kinodynamic modeling, and (3) the interaction between model accuracy and plan optimality. Empirically, we examine these factors to understand how these design choices affect performance in realistic scenarios. We highlight open challenges and research directions to steer the community toward practical, real-world deployment.
LEANN: A Low-Storage Vector Index
Jun 09, 2025Embedding-based search is widely used in applications such as recommendation and retrieval-augmented generation (RAG). Recently, there is a growing demand to support these capabilities over personal data stored locally on devices. However, maintaining the necessary data structure associated with the embedding-based search is often infeasible due to its high storage overhead. For example, indexing 100 GB of raw data requires 150 to 700 GB of storage, making local deployment impractical. Reducing this overhead while maintaining search quality and latency becomes a critical challenge. In this paper, we present LEANN, a storage-efficient approximate nearest neighbor (ANN) search index optimized for resource-constrained personal devices. LEANN combines a compact graph-based structure with an efficient on-the-fly recomputation strategy to enable fast and accurate retrieval with minimal storage overhead. Our evaluation shows that LEANN reduces index size to under 5% of the original raw data, achieving up to 50 times smaller storage than standard indexes, while maintaining 90% top-3 recall in under 2 seconds on real-world question answering benchmarks.
Spark-TTS: An Efficient LLM-Based Text-to-Speech Model with Single-Stream Decoupled Speech Tokens
Mar 03, 2025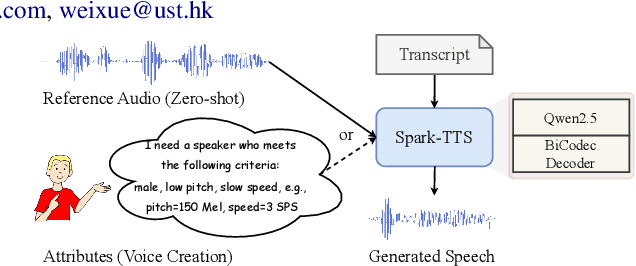



Recent advancements in large language models (LLMs) have driven significant progress in zero-shot text-to-speech (TTS) synthesis. However, existing foundation models rely on multi-stage processing or complex architectures for predicting multiple codebooks, limiting efficiency and integration flexibility. To overcome these challenges, we introduce Spark-TTS, a novel system powered by BiCodec, a single-stream speech codec that decomposes speech into two complementary token types: low-bitrate semantic tokens for linguistic content and fixed-length global tokens for speaker attributes. This disentangled representation, combined with the Qwen2.5 LLM and a chain-of-thought (CoT) generation approach, enables both coarse-grained control (e.g., gender, speaking style) and fine-grained adjustments (e.g., precise pitch values, speaking rate). To facilitate research in controllable TTS, we introduce VoxBox, a meticulously curated 100,000-hour dataset with comprehensive attribute annotations. Extensive experiments demonstrate that Spark-TTS not only achieves state-of-the-art zero-shot voice cloning but also generates highly customizable voices that surpass the limitations of reference-based synthesis. Source code, pre-trained models, and audio samples are available at https://github.com/SparkAudio/Spark-TTS.