 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeenKT: Knowledge Mastery-State Disambiguation for Knowledge Tracing
Dec 21, 2025Knowledge Tracing (KT) aims to dynamically model a student's mastery of knowledge concepts based on their historical learning interactions. Most current methods rely on single-point estimates, which cannot distinguish true ability from outburst or carelessness, creating ambiguity in judging mastery. To address this issue, we propose a Knowledge Mastery-State Disambiguation for Knowledge Tracing model (KeenKT), which represents a student's knowledge state at each interaction using a Normal-Inverse-Gaussian (NIG) distribution, thereby capturing the fluctuations in student learning behaviors. Furthermore, we design an NIG-distance-based attention mechanism to model the dynamic evolution of the knowledge state. In addition, we introduce a diffusion-based denoising reconstruction loss and a distributional contrastive learning loss to enhance the model's robustness. Extensive experiments on six public datasets demonstrate that KeenKT outperforms SOTA KT models in terms of prediction accuracy and sensitivity to behavioral fluctuations. The proposed method yields the maximum AUC improvement of 5.85% and the maximum ACC improvement of 6.89%.
Variance Reduction in Training Forecasting Models with Subgroup Sampling
Mar 02, 2021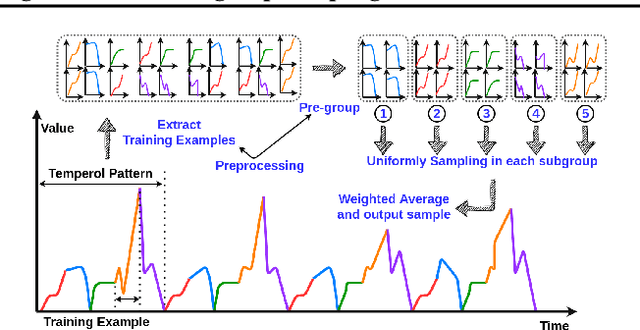
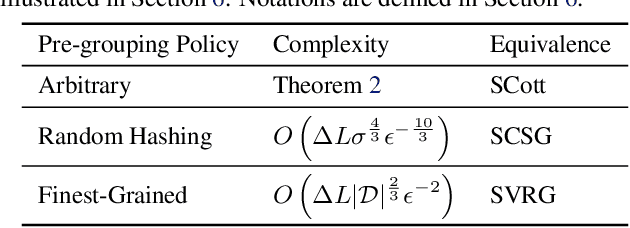
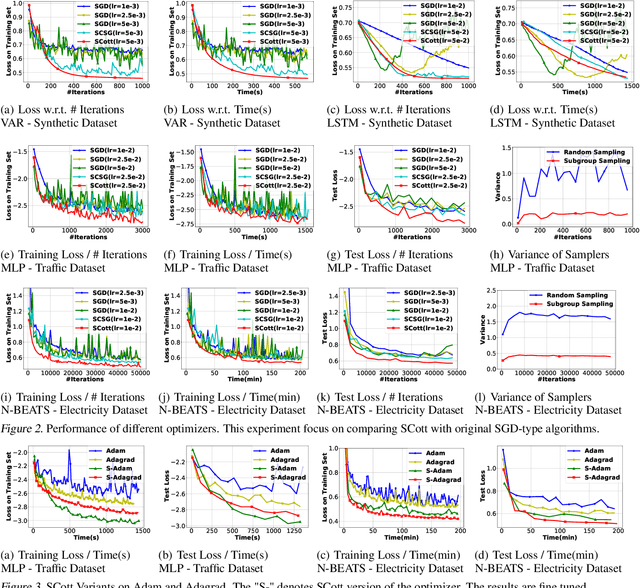
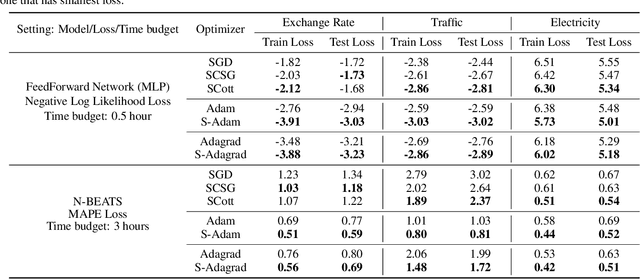
In real-world applications of large-scale time series, one often encounters the situation where the temporal patterns of time series, while drifting over time, differ from one another in the same dataset. In this paper, we provably show under such heterogeneity, training a forecasting model with commonly used stochastic optimizers (e.g. SGD) potentially suffers large gradient variance, and thus requires long time training. To alleviate this issue, we propose a sampling strategy named Subgroup Sampling, which mitigates the large variance via sampling over pre-grouped time series. We further introduce SCott, a variance reduced SGD-style optimizer that co-designs subgroup sampling with the control variate method. In theory, we provide the convergence guarantee of SCott on smooth non-convex objectives. Empirically, we evaluate SCott and other baseline optimizers on both synthetic and real-world time series forecasting problems, and show SCott converges faster with respect to both iterations and wall clock time. Additionally, we show two SCott variants that can speed up Adam and Adagrad without compromising generalization of forecasting models.
Improve black-box sequential anomaly detector relevancy with limited user feedback
Sep 15, 2020


Anomaly detectors are often designed to catch statistical anomalies. End-users typically do not have interest in all of the detected outliers, but only those relevant to their application. Given an existing black-box sequential anomaly detector, this paper proposes a method to improve its user relevancy using a small number of human feedback. As our first contribution, the method is agnostic to the detector: it only assumes access to its anomaly scores, without requirement on any additional information inside it. Inspired by a fact that anomalies are of different types, our approach identifies these types and utilizes user feedback to assign relevancy to types. This relevancy score, as our second contribution, is used to adjust the subsequent anomaly selection process. Empirical results on synthetic and real-world datasets show that our approach yields significant improvements on precision and recall over a range of anomaly detectors.