 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrontierSmith: Synthesizing Open-Ended Coding Problems at Scale
May 14, 2026Many real-world coding challenges are open-ended and admit no known optimal solution. Yet, recent progress in LLM coding has focused on well-defined tasks such as feature implementation, bug fixing, and competitive programming. Open-ended coding remains a weak spot for LLMs, largely because open-ended training problems are scarce and expensive to construct. Our goal is to synthesize open-ended coding problems at scale to train stronger LLM coders. We introduce FrontierSmith, an automated system for iteratively evolving open-ended problems from existing closed-ended coding tasks. Starting from competitive programming problems, FrontierSmith generates candidate open-ended variants by changing the problems'goals, restricting outputs, and generalizing inputs. It then uses a quantitative idea divergence metric to select problems that elicit genuinely diverse approaches from different solvers. Agents then generate test cases and verifiers for the surviving candidates. On two open-ended coding benchmarks, training on our synthesized data yields substantial gains over the base models: Qwen3.5-9B improves by +8.82 score on FrontierCS and +306.36 (Elo-rating-based performance) on ALE-bench; Qwen3.5-27B improves by +12.12 and +309.12, respectively. The synthesized problems also make agents take more turns and use more tokens, similar to human-curated ones, suggesting that closed-ended seeds can be a practical starting point for long-horizon coding data.
Do Androids Dream of Breaking the Game? Systematically Auditing AI Agent Benchmarks with BenchJack
May 12, 2026Agent benchmarks have become the de facto measure of frontier AI competence, guiding model selection, investment, and deployment. However, reward hacking, where agents maximize a score without performing the intended task, emerges spontaneously in frontier models without overfitting. We argue that benchmarks must be secure by design. From past incidents of reward hacks, we derive a taxonomy of eight recurring flaw patterns and compile them into the Agent-Eval Checklist for benchmark designers. We condense the insights into BenchJack, an automated red-teaming system that drives coding agents to audit benchmarks and identify possible reward-hacking exploits in a clairvoyant manner. Moreover, we extend BenchJack to an iterative generative-adversarial pipeline that discovers new flaws and patches them iteratively to improve benchmark robustness. We apply BenchJack to 10 popular agent benchmarks spanning software engineering, web navigation, desktop computing, and terminal operations. BenchJack synthesizes reward-hacking exploits that achieve near-perfect scores on most of the benchmarks without solving a single task, surfacing 219 distinct flaws across the eight classes. Moreover, BenchJack's extended pipeline reduces the hackable-task ratio from near 100% to under 10% on four benchmarks without fatal design flaws, fully patching WebArena and OSWorld within three iterations. Our results show that evaluation pipelines have not internalized an adversarial mindset, and that proactive auditing could help close the security gap for the fast-paced benchmarking space.
Combee: Scaling Prompt Learning for Self-Improving Language Model Agents
Apr 05, 2026Recent advances in prompt learning allow large language model agents to acquire task-relevant knowledge from inference-time context without parameter changes. For example, existing methods (like ACE or GEPA) can learn system prompts to improve accuracy based on previous agent runs. However, these methods primarily focus on single-agent or low-parallelism settings. This fundamentally limits their ability to efficiently learn from a large set of collected agentic traces. It would be efficient and beneficial to run prompt learning in parallel to accommodate the growing trend of learning from many agentic traces or parallel agent executions. Yet without a principled strategy for scaling, current methods suffer from quality degradation with high parallelism. To improve both the efficiency and quality of prompt learning, we propose Combee, a novel framework to scale parallel prompt learning for self-improving agents. Combee speeds up learning and enables running many agents in parallel while learning from their aggregate traces without quality degradation. To achieve this, Combee leverages parallel scans and employs an augmented shuffle mechanism; Combee also introduces a dynamic batch size controller to balance quality and delay. Evaluations on AppWorld, Terminal-Bench, Formula, and FiNER demonstrate that Combee achieves up to 17x speedup over previous methods with comparable or better accuracy and equivalent cost.
FrontierCS: Evolving Challenges for Evolving Intelligence
Dec 17, 2025



We introduce FrontierCS, a benchmark of 156 open-ended problems across diverse areas of computer science, designed and reviewed by experts, including CS PhDs and top-tier competitive programming participants and problem setters. Unlike existing benchmarks that focus on tasks with known optimal solutions, FrontierCS targets problems where the optimal solution is unknown, but the quality of a solution can be objectively evaluated. Models solve these tasks by implementing executable programs rather than outputting a direct answer. FrontierCS includes algorithmic problems, which are often NP-hard variants of competitive programming problems with objective partial scoring, and research problems with the same property. For each problem we provide an expert reference solution and an automatic evaluator. Combining open-ended design, measurable progress, and expert curation, FrontierCS provides a benchmark at the frontier of computer-science difficulty. Empirically, we find that frontier reasoning models still lag far behind human experts on both the algorithmic and research tracks, that increasing reasoning budgets alone does not close this gap, and that models often over-optimize for generating merely workable code instead of discovering high-quality algorithms and system designs.
EVICPRESS: Joint KV-Cache Compression and Eviction for Efficient LLM Serving
Dec 16, 2025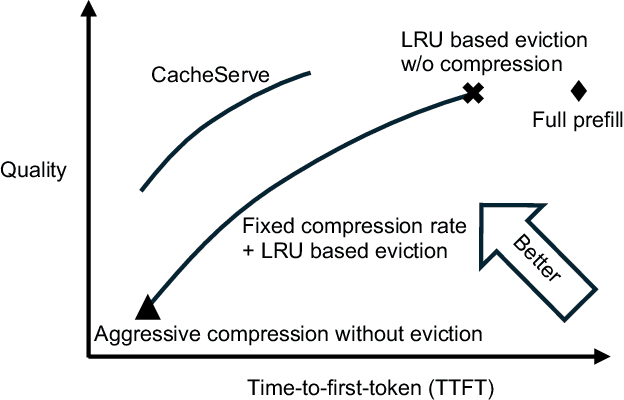
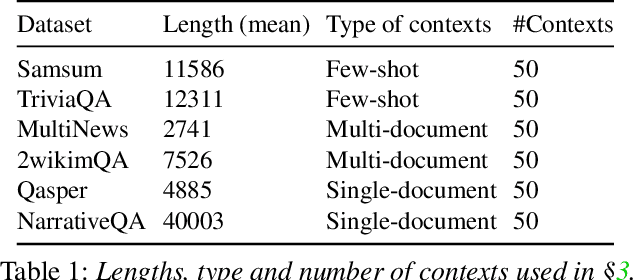
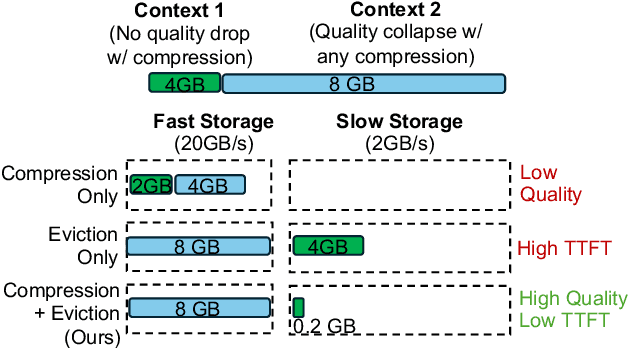
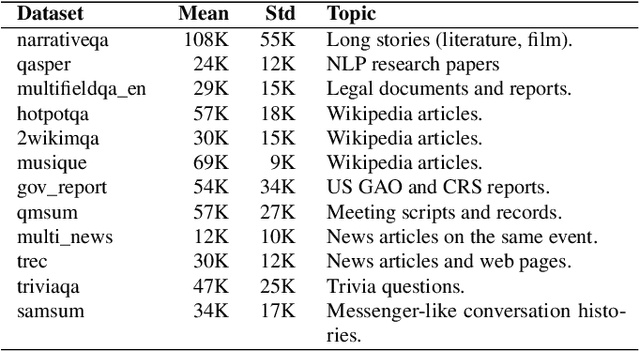
Reusing KV cache is essential for high efficiency of Large Language Model (LLM) inference systems. With more LLM users, the KV cache footprint can easily exceed GPU memory capacity, so prior work has proposed to either evict KV cache to lower-tier storage devices, or compress KV cache so that more KV cache can be fit in the fast memory. However, prior work misses an important opportunity: jointly optimizing the eviction and compression decisions across all KV caches to minimize average generation latency without hurting quality. We propose EVICPRESS, a KV-cache management system that applies lossy compression and adaptive eviction to KV cache across multiple storage tiers. Specifically, for each KV cache of a context, EVICPRESS considers the effect of compression and eviction of the KV cache on the average generation quality and delay across all contexts as a whole. To achieve this, EVICPRESS proposes a unified utility function that quantifies the effect of quality and delay of the lossy compression or eviction. To this end, EVICPRESS's profiling module periodically updates the utility function scores on all possible eviction-compression configurations for all contexts and places KV caches using a fast heuristic to rearrange KV caches on all storage tiers, with the goal of maximizing the utility function scores on each storage tier. Compared to the baselines that evict KV cache or compress KV cache, EVICPRESS achieves higher KV-cache hit rates on fast devices, i.e., lower delay, while preserving high generation quality by applying conservative compression to contexts that are sensitive to compression errors. Evaluation on 12 datasets and 5 models demonstrates that EVICPRESS achieves up to 2.19x faster time-to-first-token (TTFT) at equivalent generation quality.
Agentic Context Engineering: Evolving Contexts for Self-Improving Language Models
Oct 06, 2025



Large language model (LLM) applications such as agents and domain-specific reasoning increasingly rely on context adaptation -- modifying inputs with instructions, strategies, or evidence, rather than weight updates. Prior approaches improve usability but often suffer from brevity bias, which drops domain insights for concise summaries, and from context collapse, where iterative rewriting erodes details over time. Building on the adaptive memory introduced by Dynamic Cheatsheet, we introduce ACE (Agentic Context Engineering), a framework that treats contexts as evolving playbooks that accumulate, refine, and organize strategies through a modular process of generation, reflection, and curation. ACE prevents collapse with structured, incremental updates that preserve detailed knowledge and scale with long-context models. Across agent and domain-specific benchmarks, ACE optimizes contexts both offline (e.g., system prompts) and online (e.g., agent memory), consistently outperforming strong baselines: +10.6% on agents and +8.6% on finance, while significantly reducing adaptation latency and rollout cost. Notably, ACE could adapt effectively without labeled supervision and instead by leveraging natural execution feedback. On the AppWorld leaderboard, ACE matches the top-ranked production-level agent on the overall average and surpasses it on the harder test-challenge split, despite using a smaller open-source model. These results show that comprehensive, evolving contexts enable scalable, efficient, and self-improving LLM systems with low overhead.
HypoEval: Hypothesis-Guided Evaluation for Natural Language Generation
Apr 09, 2025Large language models (LLMs) have demonstrated great potential for automating the evaluation of natural language generation. Previous frameworks of LLM-as-a-judge fall short in two ways: they either use zero-shot setting without consulting any human input, which leads to low alignment, or fine-tune LLMs on labeled data, which requires a non-trivial number of samples. Moreover, previous methods often provide little reasoning behind automated evaluations. In this paper, we propose HypoEval, Hypothesis-guided Evaluation framework, which first uses a small corpus of human evaluations to generate more detailed rubrics for human judgments and then incorporates a checklist-like approach to combine LLM's assigned scores on each decomposed dimension to acquire overall scores. With only 30 human evaluations, HypoEval achieves state-of-the-art performance in alignment with both human rankings (Spearman correlation) and human scores (Pearson correlation), on average outperforming G-Eval by 11.86% and fine-tuned Llama-3.1-8B-Instruct with at least 3 times more human evaluations by 11.95%. Furthermore, we conduct systematic studies to assess the robustness of HypoEval, highlighting its effectiveness as a reliable and interpretable automated evaluation framework.
CacheBlend: Fast Large Language Model Serving with Cached Knowledge Fusion
May 26, 2024



Large language models (LLMs) often incorporate multiple text chunks in their inputs to provide the necessary contexts. To speed up the prefill of the long LLM inputs, one can pre-compute the KV cache of a text and re-use the KV cache when the context is reused as the prefix of another LLM input. However, the reused text chunks are not always the input prefix, and when they are not, their precomputed KV caches cannot be directly used since they ignore the text's cross-attention with the preceding text in the LLM input. Thus, the benefits of reusing KV caches remain largely unrealized. This paper tackles just one question: when an LLM input contains multiple text chunks, how to quickly combine their precomputed KV caches in order to achieve the same generation quality as the expensive full prefill (i.e., without reusing KV cache)? We present CacheBlend, a scheme that reuses the pre-computed KV caches, regardless prefix or not, and selectively recomputes the KV values of a small subset of tokens to partially update each reused KV cache. In the meantime,the small extra delay for recomputing some tokens can be pipelined with the retrieval of KV caches within the same job,allowing CacheBlend to store KV caches in slower devices with more storage capacity while retrieving them without increasing the inference delay. By comparing CacheBlend with the state-of-the-art KV cache reusing schemes on three open-source LLMs of various sizes and four popular benchmark datasets of different tasks, we show that CacheBlend reduces time-to-first-token (TTFT) by 2.2-3.3X and increases the inference throughput by 2.8-5X, compared with full KV recompute, without compromising generation quality or incurring more storage cost.
Chatterbox: Robust Transport for LLM Token Streaming under Unstable Network
Jan 23, 2024



To render each generated token in real time, the LLM server generates response tokens one by one and streams each generated token (or group of a few tokens) through the network to the user right after it is generated, which we refer to as LLM token streaming. However, under unstable network conditions, the LLM token streaming experience could suffer greatly from stalls since one packet loss could block the rendering of tokens contained in subsequent packets even if they arrive on time. With a real-world measurement study, we show that current applications including ChatGPT, Claude, and Bard all suffer from increased stall under unstable network. For this emerging token streaming problem in LLM Chatbots, we propose a novel transport layer scheme, called Chatterbox, which puts new generated tokens as well as currently unacknowledged tokens in the next outgoing packet. This ensures that each packet contains some new tokens and can be independently rendered when received, thus avoiding aforementioned stalls caused by missing packets. Through simulation under various network conditions, we show Chatterbox reduces stall ratio (proportion of token rendering wait time) by 71.0% compared to the token streaming method commonly used by real chatbot applications and by 31.6% compared to a custom packet duplication scheme. By tailoring Chatterbox to fit the token-by-token generation of LLM, we enable the Chatbots to respond like an eloquent speaker for users to better enjoy pervasive AI.
CacheGen: Fast Context Loading for Language Model Applications
Oct 11, 2023



As large language models (LLMs) take on more complex tasks, their inputs incorporate longer contexts to respond to questions that require domain knowledge or user-specific conversational histories. Yet, using long contexts poses a challenge for responsive LLM systems, as nothing can be generated until all the contexts are fetched to and processed by the LLM. Existing systems optimize only the computation delay in context processing (e.g., by caching intermediate key-value features of the text context) but often cause longer network delays in context fetching (e.g., key-value features consume orders of magnitude larger bandwidth than the text context). This paper presents CacheGen to minimize the delays in fetching and processing contexts for LLMs. CacheGen reduces the bandwidth needed for transmitting long contexts' key-value (KV) features through a novel encoder that compresses KV features into more compact bitstream representations. The encoder combines adaptive quantization with a tailored arithmetic coder, taking advantage of the KV features' distributional properties, such as locality across tokens. Furthermore, CacheGen minimizes the total delay in fetching and processing a context by using a controller that determines when to load the context as compressed KV features or raw text and picks the appropriate compression level if loaded as KV features. We test CacheGen on three models of various sizes and three datasets of different context lengths. Compared to recent methods that handle long contexts, CacheGen reduces bandwidth usage by 3.7-4.3x and the total delay in fetching and processing contexts by 2.7-3x while maintaining similar LLM performance on various tasks as loading the text contexts.