 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALER:Synthetic Scalable Adaptive Learning Environment for Reasoning
Jan 08, 2026Reinforcement learning (RL) offers a principled way to enhance the reasoning capabilities of large language models, yet its effectiveness hinges on training signals that remain informative as models evolve. In practice, RL progress often slows when task difficulty becomes poorly aligned with model capability, or when training is dominated by a narrow set of recurring problem patterns. To jointly address these issues, we propose SCALER (Synthetic sCalable Adaptive Learning Environment for Reasoning), a framework that sustains effective learning signals through adaptive environment design. SCALER introduces a scalable synthesis pipeline that converts real-world programming problems into verifiable reasoning environments with controllable difficulty and unbounded instance generation, enabling RL training beyond finite datasets while preserving strong correctness guarantees. Building on this, SCALER further employs an adaptive multi-environment RL strategy that dynamically adjusts instance difficulty and curates the active set of environments to track the model's capability frontier and maintain distributional diversity. This co-adaptation prevents reward sparsity, mitigates overfitting to narrow task patterns, and supports sustained improvement throughout training. Extensive experiments show that SCALER consistently outperforms dataset-based RL baselines across diverse reasoning benchmarks and exhibits more stable, long-horizon training dynamics.
Do LLMs Signal When They're Right? Evidence from Neuron Agreement
Oct 30, 2025Large language models (LLMs) commonly boost reasoning via sample-evaluate-ensemble decoders, achieving label free gains without ground truth. However, prevailing strategies score candidates using only external outputs such as token probabilities, entropies, or self evaluations, and these signals can be poorly calibrated after post training. We instead analyze internal behavior based on neuron activations and uncover three findings: (1) external signals are low dimensional projections of richer internal dynamics; (2) correct responses activate substantially fewer unique neurons than incorrect ones throughout generation; and (3) activations from correct responses exhibit stronger cross sample agreement, whereas incorrect ones diverge. Motivated by these observations, we propose Neuron Agreement Decoding (NAD), an unsupervised best-of-N method that selects candidates using activation sparsity and cross sample neuron agreement, operating solely on internal signals and without requiring comparable textual outputs. NAD enables early correctness prediction within the first 32 generated tokens and supports aggressive early stopping. Across math and science benchmarks with verifiable answers, NAD matches majority voting; on open ended coding benchmarks where majority voting is inapplicable, NAD consistently outperforms Avg@64. By pruning unpromising trajectories early, NAD reduces token usage by 99% with minimal loss in generation quality, showing that internal signals provide reliable, scalable, and efficient guidance for label free ensemble decoding.
CriticLean: Critic-Guided Reinforcement Learning for Mathematical Formalization
Jul 08, 2025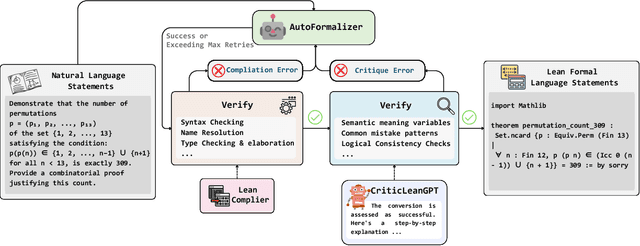

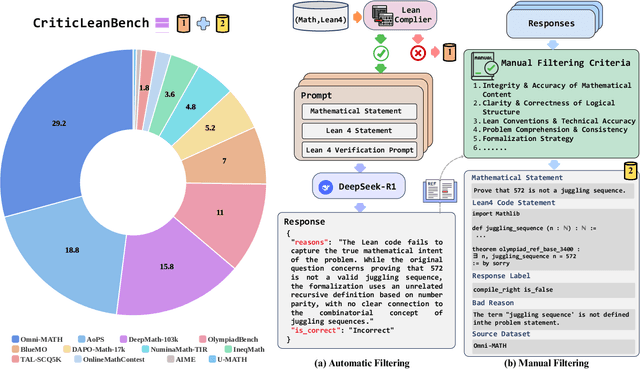
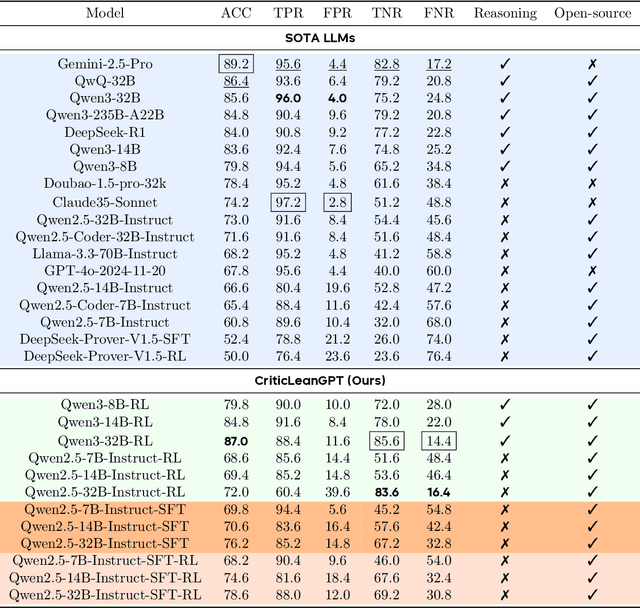
Translating natural language mathematical statements into formal, executable code is a fundamental challenge in automated theorem proving. While prior work has focused on generation and compilation success, little attention has been paid to the critic phase-the evaluation of whether generated formalizations truly capture the semantic intent of the original problem. In this paper, we introduce CriticLean, a novel critic-guided reinforcement learning framework that elevates the role of the critic from a passive validator to an active learning component. Specifically, first, we propose the CriticLeanGPT, trained via supervised fine-tuning and reinforcement learning, to rigorously assess the semantic fidelity of Lean 4 formalizations. Then, we introduce CriticLeanBench, a benchmark designed to measure models' ability to distinguish semantically correct from incorrect formalizations, and demonstrate that our trained CriticLeanGPT models can significantly outperform strong open- and closed-source baselines. Building on the CriticLean framework, we construct FineLeanCorpus, a dataset comprising over 285K problems that exhibits rich domain diversity, broad difficulty coverage, and high correctness based on human evaluation. Overall, our findings highlight that optimizing the critic phase is essential for producing reliable formalizations, and we hope our CriticLean will provide valuable insights for future advances in formal mathematical reasoning.
Com$^2$: A Causal-Guided Benchmark for Exploring Complex Commonsense Reasoning in Large Language Models
Jun 08, 2025Large language models (LLMs) have mastered abundant simple and explicit commonsense knowledge through pre-training, enabling them to achieve human-like performance in simple commonsense reasoning. Nevertheless, LLMs struggle to reason with complex and implicit commonsense knowledge that is derived from simple ones (such as understanding the long-term effects of certain events), an aspect humans tend to focus on more. Existing works focus on complex tasks like math and code, while complex commonsense reasoning remains underexplored due to its uncertainty and lack of structure. To fill this gap and align with real-world concerns, we propose a benchmark Com$^2$ focusing on complex commonsense reasoning. We first incorporate causal event graphs to serve as structured complex commonsense. Then we adopt causal theory~(e.g., intervention) to modify the causal event graphs and obtain different scenarios that meet human concerns. Finally, an LLM is employed to synthesize examples with slow thinking, which is guided by the logical relationships in the modified causal graphs. Furthermore, we use detective stories to construct a more challenging subset. Experiments show that LLMs struggle in reasoning depth and breadth, while post-training and slow thinking can alleviate this. The code and data are available at https://github.com/Waste-Wood/Com2.
Towards Storage-Efficient Visual Document Retrieval: An Empirical Study on Reducing Patch-Level Embeddings
Jun 05, 2025Despite the strong performance of ColPali/ColQwen2 in Visualized Document Retrieval (VDR), it encodes each page into multiple patch-level embeddings and leads to excessive memory usage. This empirical study investigates methods to reduce patch embeddings per page at minimum performance degradation. We evaluate two token-reduction strategies: token pruning and token merging. Regarding token pruning, we surprisingly observe that a simple random strategy outperforms other sophisticated pruning methods, though still far from satisfactory. Further analysis reveals that pruning is inherently unsuitable for VDR as it requires removing certain page embeddings without query-specific information. Turning to token merging (more suitable for VDR), we search for the optimal combinations of merging strategy across three dimensions and develop Light-ColPali/ColQwen2. It maintains 98.2% of retrieval performance with only 11.8% of original memory usage, and preserves 94.6% effectiveness at 2.8% memory footprint. We expect our empirical findings and resulting Light-ColPali/ColQwen2 offer valuable insights and establish a competitive baseline for future research towards efficient VDR.
Long or short CoT? Investigating Instance-level Switch of Large Reasoning Models
Jun 04, 2025



With the rapid advancement of large reasoning models, long Chain-of-Thought (CoT) prompting has demonstrated strong performance on complex tasks. However, this often comes with a significant increase in token usage. In this paper, we conduct a comprehensive empirical analysis comparing long and short CoT strategies. Our findings reveal that while long CoT can lead to performance improvements, its benefits are often marginal relative to its significantly higher token consumption. Specifically, long CoT tends to outperform when ample generation budgets are available, whereas short CoT is more effective under tighter budget constraints. These insights underscore the need for a dynamic approach that selects the proper CoT strategy based on task context and resource availability. To address this, we propose SwitchCoT, an automatic framework that adaptively chooses between long and short CoT strategies to balance reasoning accuracy and computational efficiency. Moreover, SwitchCoT is designed to be budget-aware, making it broadly applicable across scenarios with varying resource constraints. Experimental results demonstrate that SwitchCoT can reduce inference costs by up to 50% while maintaining high accuracy. Notably, under limited token budgets, it achieves performance comparable to, or even exceeding, that of using either long or short CoT alone.
Disentangling Language and Culture for Evaluating Multilingual Large Language Models
May 30, 2025This paper introduces a Dual Evaluation Framework to comprehensively assess the multilingual capabilities of LLMs. By decomposing the evaluation along the dimensions of linguistic medium and cultural context, this framework enables a nuanced analysis of LLMs' ability to process questions within both native and cross-cultural contexts cross-lingually. Extensive evaluations are conducted on a wide range of models, revealing a notable "CulturalLinguistic Synergy" phenomenon, where models exhibit better performance when questions are culturally aligned with the language. This phenomenon is further explored through interpretability probing, which shows that a higher proportion of specific neurons are activated in a language's cultural context. This activation proportion could serve as a potential indicator for evaluating multilingual performance during model training. Our findings challenge the prevailing notion that LLMs, primarily trained on English data, perform uniformly across languages and highlight the necessity of culturally and linguistically model evaluations. Our code can be found at https://yingjiahao14. github.io/Dual-Evaluation/.
FRAbench and GenEval: Scaling Fine-Grained Aspect Evaluation across Tasks, Modalities
May 19, 2025Evaluating the open-ended outputs of large language models (LLMs) has become a bottleneck as model capabilities, task diversity, and modality coverage rapidly expand. Existing "LLM-as-a-Judge" evaluators are typically narrow in a few tasks, aspects, or modalities, and easily suffer from low consistency. In this paper, we argue that explicit, fine-grained aspect specification is the key to both generalizability and objectivity in automated evaluation. To do so, we introduce a hierarchical aspect taxonomy spanning 112 aspects that unifies evaluation across four representative settings - Natural Language Generation, Image Understanding, Image Generation, and Interleaved Text-and-Image Generation. Building on this taxonomy, we create FRAbench, a benchmark comprising 60.4k pairwise samples with 325k aspect-level labels obtained from a combination of human and LLM annotations. FRAbench provides the first large-scale, multi-modal resource for training and meta-evaluating fine-grained LMM judges. Leveraging FRAbench, we develop GenEval, a fine-grained evaluator generalizable across tasks and modalities. Experiments show that GenEval (i) attains high agreement with GPT-4o and expert annotators, (ii) transfers robustly to unseen tasks and modalities, and (iii) reveals systematic weaknesses of current LMMs on evaluation.
Teach2Eval: An Indirect Evaluation Method for LLM by Judging How It Teaches
May 18, 2025Recent progress in large language models (LLMs) has outpaced the development of effective evaluation methods. Traditional benchmarks rely on task-specific metrics and static datasets, which often suffer from fairness issues, limited scalability, and contamination risks. In this paper, we introduce Teach2Eval, an indirect evaluation framework inspired by the Feynman Technique. Instead of directly testing LLMs on predefined tasks, our method evaluates a model's multiple abilities to teach weaker student models to perform tasks effectively. By converting open-ended tasks into standardized multiple-choice questions (MCQs) through teacher-generated feedback, Teach2Eval enables scalable, automated, and multi-dimensional assessment. Our approach not only avoids data leakage and memorization but also captures a broad range of cognitive abilities that are orthogonal to current benchmarks. Experimental results across 26 leading LLMs show strong alignment with existing human and model-based dynamic rankings, while offering additional interpretability for training guidance.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025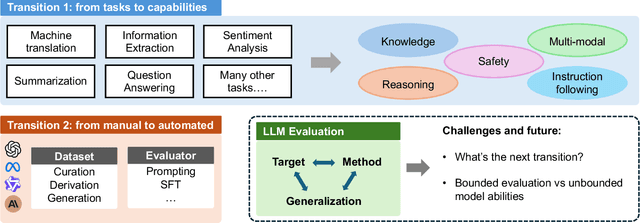
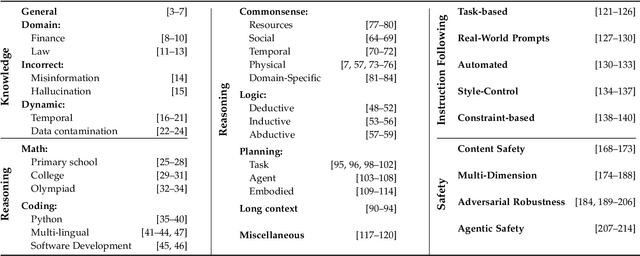
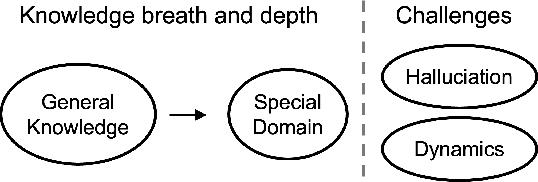
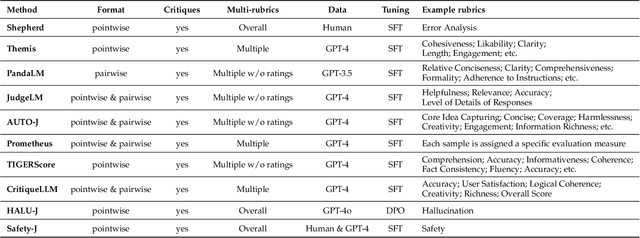
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.