 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Multi-Task Low-Rank Model Adaptation
Mar 02, 2026Scaling multi-task low-rank adaptation (LoRA) to a large number of tasks induces catastrophic performance degradation, such as an accuracy drop from 88.2% to 2.0% on DOTA when scaling from 5 to 15 tasks. This failure is due to parameter and representation misalignment. We find that existing solutions, like regularization and dynamic routing, fail at scale because they are constrained by a fundamental trade-off: strengthening regularization to reduce inter-task conflict inadvertently suppresses the essential feature discrimination required for effective routing. In this work, we identify two root causes for this trade-off. First, uniform regularization disrupts inter-task knowledge sharing: shared underlying knowledge concentrates in high-SV components (89% alignment on Flanv2->BBH). Uniform regularization forces high-SV components to update in orthogonal directions, directly disrupting the shared knowledge. Second, Conflict Amplification: Applying LoRA at the component-level (e.g., W_q, W_v) amplifies gradient conflicts; we show block-level adaptation reduces this conflict by 76% with only 50% parameters. Based on these insights, we propose mtLoRA, a scalable solution with three novel designs: 1) Spectral-Aware Regularization to selectively orthogonalize low-SV components while preserving high-SV shared knowledge, 2) Block-Level Adaptation to mitigate conflict amplification and largely improve parameter efficiency, and 3) Fine-Grained Routing using dimension-specific weights for superior expressive power. On four large-scale (15-25 tasks) vision (DOTA and iNat2018) and NLP (Dolly-15k and BBH) benchmarks, mtLoRA achieves 91.7%, 81.5%, 44.5% and 38.5% accuracy on DOTA, iNat2018, Dolly-15k and BBH respectively, outperforming the state-of-the-art by 2.3% on average while using 47% fewer parameters and 24% less training time.
* Published as a conference paper at ICLR 2026. 21 pages, 4 figures, 11 tables. Code is available
Meta-Learning Hyperparameters for Parameter Efficient Fine-Tuning
Mar 02, 2026Training large foundation models from scratch for domain-specific applications is almost impossible due to data limits and long-tailed distributions -- taking remote sensing (RS) as an example. Fine-tuning natural image pre-trained models on RS images is a straightforward solution. To reduce computational costs and improve performance on tail classes, existing methods apply parameter-efficient fine-tuning (PEFT) techniques, such as LoRA and AdaptFormer. However, we observe that fixed hyperparameters -- such as intra-layer positions, layer depth, and scaling factors, can considerably hinder PEFT performance, as fine-tuning on RS images proves highly sensitive to these settings. To address this, we propose MetaPEFT, a method incorporating adaptive scalers that dynamically adjust module influence during fine-tuning. MetaPEFT dynamically adjusts three key factors of PEFT on RS images: module insertion, layer selection, and module-wise learning rates, which collectively control the influence of PEFT modules across the network. We conduct extensive experiments on three transfer-learning scenarios and five datasets in both RS and natural image domains. The results show that MetaPEFT achieves state-of-the-art performance in cross-spectral adaptation, requiring only a small amount of trainable parameters and improving tail-class accuracy significantly.
* Accepted by CVPR 2025 (Highlight). Code is available at: https://github.com/doem97/metalora
Reducing Class-Wise Performance Disparity via Margin Regularization
Jan 30, 2026Deep neural networks often exhibit substantial disparities in class-wise accuracy, even when trained on class-balanced data, posing concerns for reliable deployment. While prior efforts have explored empirical remedies, a theoretical understanding of such performance disparities in classification remains limited. In this work, we present Margin Regularization for Performance Disparity Reduction (MR$^2$), a theoretically principled regularization for classification by dynamically adjusting margins in both the logit and representation spaces. Our analysis establishes a margin-based, class-sensitive generalization bound that reveals how per-class feature variability contributes to error, motivating the use of larger margins for hard classes. Guided by this insight, MR$^2$ optimizes per-class logit margins proportional to feature spread and penalizes excessive representation margins to enhance intra-class compactness. Experiments on seven datasets, including ImageNet, and diverse pre-trained backbones (MAE, MoCov2, CLIP) demonstrate that MR$^2$ not only improves overall accuracy but also significantly boosts hard class performance without trading off easy classes, thus reducing performance disparity. Code is available at: https://github.com/BeierZhu/MR2
3D Question Answering via only 2D Vision-Language Models
May 28, 2025Large vision-language models (LVLMs) have significantly advanced numerous fields. In this work, we explore how to harness their potential to address 3D scene understanding tasks, using 3D question answering (3D-QA) as a representative example. Due to the limited training data in 3D, we do not train LVLMs but infer in a zero-shot manner. Specifically, we sample 2D views from a 3D point cloud and feed them into 2D models to answer a given question. When the 2D model is chosen, e.g., LLAVA-OV, the quality of sampled views matters the most. We propose cdViews, a novel approach to automatically selecting critical and diverse Views for 3D-QA. cdViews consists of two key components: viewSelector prioritizing critical views based on their potential to provide answer-specific information, and viewNMS enhancing diversity by removing redundant views based on spatial overlap. We evaluate cdViews on the widely-used ScanQA and SQA benchmarks, demonstrating that it achieves state-of-the-art performance in 3D-QA while relying solely on 2D models without fine-tuning. These findings support our belief that 2D LVLMs are currently the most effective alternative (of the resource-intensive 3D LVLMs) for addressing 3D tasks.
Toward Generalizable Evaluation in the LLM Era: A Survey Beyond Benchmarks
Apr 26, 2025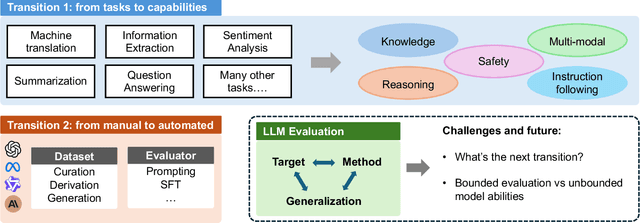
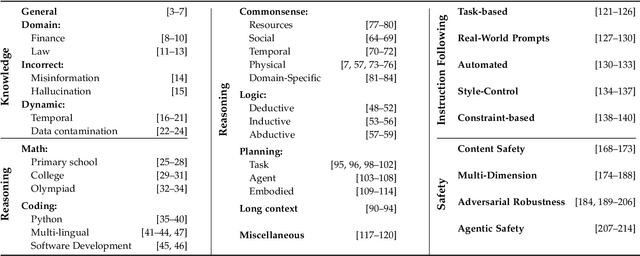
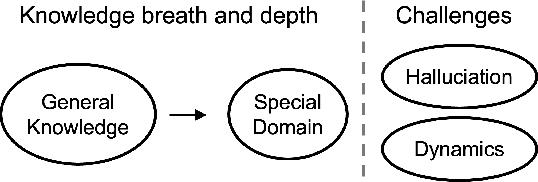
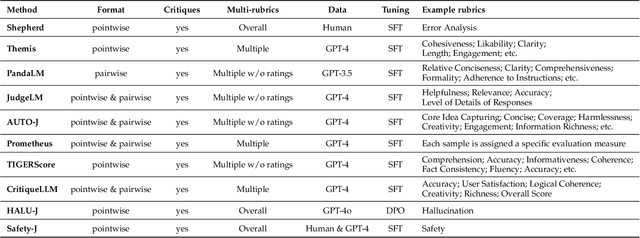
Large Language Models (LLMs) are advancing at an amazing speed and have become indispensable across academia, industry, and daily applications. To keep pace with the status quo, this survey probes the core challenges that the rise of LLMs poses for evaluation. We identify and analyze two pivotal transitions: (i) from task-specific to capability-based evaluation, which reorganizes benchmarks around core competencies such as knowledge, reasoning, instruction following, multi-modal understanding, and safety; and (ii) from manual to automated evaluation, encompassing dynamic dataset curation and "LLM-as-a-judge" scoring. Yet, even with these transitions, a crucial obstacle persists: the evaluation generalization issue. Bounded test sets cannot scale alongside models whose abilities grow seemingly without limit. We will dissect this issue, along with the core challenges of the above two transitions, from the perspectives of methods, datasets, evaluators, and metrics. Due to the fast evolving of this field, we will maintain a living GitHub repository (links are in each section) to crowd-source updates and corrections, and warmly invite contributors and collaborators.
Unsupervised Visual Chain-of-Thought Reasoning via Preference Optimization
Apr 25, 2025Chain-of-thought (CoT) reasoning greatly improves the interpretability and problem-solving abilities of multimodal large language models (MLLMs). However, existing approaches are focused on text CoT, limiting their ability to leverage visual cues. Visual CoT remains underexplored, and the only work is based on supervised fine-tuning (SFT) that relies on extensive labeled bounding-box data and is hard to generalize to unseen cases. In this paper, we introduce Unsupervised Visual CoT (UV-CoT), a novel framework for image-level CoT reasoning via preference optimization. UV-CoT performs preference comparisons between model-generated bounding boxes (one is preferred and the other is dis-preferred), eliminating the need for bounding-box annotations. We get such preference data by introducing an automatic data generation pipeline. Given an image, our target MLLM (e.g., LLaVA-1.5-7B) generates seed bounding boxes using a template prompt and then answers the question using each bounded region as input. An evaluator MLLM (e.g., OmniLLM-12B) ranks the responses, and these rankings serve as supervision to train the target MLLM with UV-CoT by minimizing negative log-likelihood losses. By emulating human perception--identifying key regions and reasoning based on them--UV-CoT can improve visual comprehension, particularly in spatial reasoning tasks where textual descriptions alone fall short. Our experiments on six datasets demonstrate the superiority of UV-CoT, compared to the state-of-the-art textual and visual CoT methods. Our zero-shot testing on four unseen datasets shows the strong generalization of UV-CoT. The code is available in https://github.com/kesenzhao/UV-CoT.
Generalized Visual Relation Detection with Diffusion Models
Apr 16, 2025



Visual relation detection (VRD) aims to identify relationships (or interactions) between object pairs in an image. Although recent VRD models have achieved impressive performance, they are all restricted to pre-defined relation categories, while failing to consider the semantic ambiguity characteristic of visual relations. Unlike objects, the appearance of visual relations is always subtle and can be described by multiple predicate words from different perspectives, e.g., ``ride'' can be depicted as ``race'' and ``sit on'', from the sports and spatial position views, respectively. To this end, we propose to model visual relations as continuous embeddings, and design diffusion models to achieve generalized VRD in a conditional generative manner, termed Diff-VRD. We model the diffusion process in a latent space and generate all possible relations in the image as an embedding sequence. During the generation, the visual and text embeddings of subject-object pairs serve as conditional signals and are injected via cross-attention. After the generation, we design a subsequent matching stage to assign the relation words to subject-object pairs by considering their semantic similarities. Benefiting from the diffusion-based generative process, our Diff-VRD is able to generate visual relations beyond the pre-defined category labels of datasets. To properly evaluate this generalized VRD task, we introduce two evaluation metrics, i.e., text-to-image retrieval and SPICE PR Curve inspired by image captioning. Extensive experiments in both human-object interaction (HOI) detection and scene graph generation (SGG) benchmarks attest to the superiority and effectiveness of Diff-VRD.
Unified Generative and Discriminative Training for Multi-modal Large Language Models
Nov 01, 2024



In recent times, Vision-Language Models (VLMs) have been trained under two predominant paradigms. Generative training has enabled Multimodal Large Language Models (MLLMs) to tackle various complex tasks, yet issues such as hallucinations and weak object discrimination persist. Discriminative training, exemplified by models like CLIP, excels in zero-shot image-text classification and retrieval, yet struggles with complex scenarios requiring fine-grained semantic differentiation. This paper addresses these challenges by proposing a unified approach that integrates the strengths of both paradigms. Considering interleaved image-text sequences as the general format of input samples, we introduce a structure-induced training strategy that imposes semantic relationships between input samples and the MLLM's hidden state. This approach enhances the MLLM's ability to capture global semantics and distinguish fine-grained semantics. By leveraging dynamic sequence alignment within the Dynamic Time Warping framework and integrating a novel kernel for fine-grained semantic differentiation, our method effectively balances generative and discriminative tasks. Extensive experiments demonstrate the effectiveness of our approach, achieving state-of-the-art results in multiple generative tasks, especially those requiring cognitive and discrimination abilities. Additionally, our method surpasses discriminative benchmarks in interleaved and fine-grained retrieval tasks. By employing a retrieval-augmented generation strategy, our approach further enhances performance in some generative tasks within one model, offering a promising direction for future research in vision-language modeling.
Reverse Modeling in Large Language Models
Oct 13, 2024



Humans are accustomed to reading and writing in a forward manner, and this natural bias extends to text understanding in auto-regressive large language models (LLMs). This paper investigates whether LLMs, like humans, struggle with reverse modeling, specifically with reversed text inputs. We found that publicly available pre-trained LLMs cannot understand such inputs. However, LLMs trained from scratch with both forward and reverse texts can understand them equally well during inference. Our case study shows that different-content texts result in different losses if input (to LLMs) in different directions -- some get lower losses for forward while some for reverse. This leads us to a simple and nice solution for data selection based on the loss differences between forward and reverse directions. Using our selected data in continued pretraining can boost LLMs' performance by a large margin across different language understanding benchmarks.
Towards Natural Image Matting in the Wild via Real-Scenario Prior
Oct 09, 2024



Recent approaches attempt to adapt powerful interactive segmentation models, such as SAM, to interactive matting and fine-tune the models based on synthetic matting datasets. However, models trained on synthetic data fail to generalize to complex and occlusion scenes. We address this challenge by proposing a new matting dataset based on the COCO dataset, namely COCO-Matting. Specifically, the construction of our COCO-Matting includes accessory fusion and mask-to-matte, which selects real-world complex images from COCO and converts semantic segmentation masks to matting labels. The built COCO-Matting comprises an extensive collection of 38,251 human instance-level alpha mattes in complex natural scenarios. Furthermore, existing SAM-based matting methods extract intermediate features and masks from a frozen SAM and only train a lightweight matting decoder by end-to-end matting losses, which do not fully exploit the potential of the pre-trained SAM. Thus, we propose SEMat which revamps the network architecture and training objectives. For network architecture, the proposed feature-aligned transformer learns to extract fine-grained edge and transparency features. The proposed matte-aligned decoder aims to segment matting-specific objects and convert coarse masks into high-precision mattes. For training objectives, the proposed regularization and trimap loss aim to retain the prior from the pre-trained model and push the matting logits extracted from the mask decoder to contain trimap-based semantic information. Extensive experiments across seven diverse datasets demonstrate the superior performance of our method, proving its efficacy in interactive natural image matting. We open-source our code, models, and dataset at https://github.com/XiaRho/SEMat.