 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeF8Net: Fixed-Point 8-bit Only Multiplication for Network Quantization
Feb 10, 2022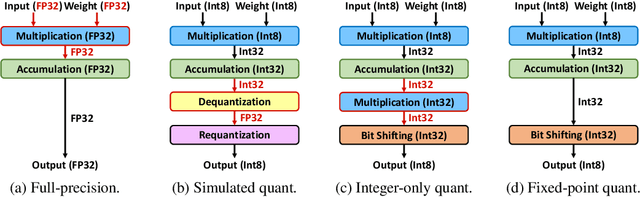
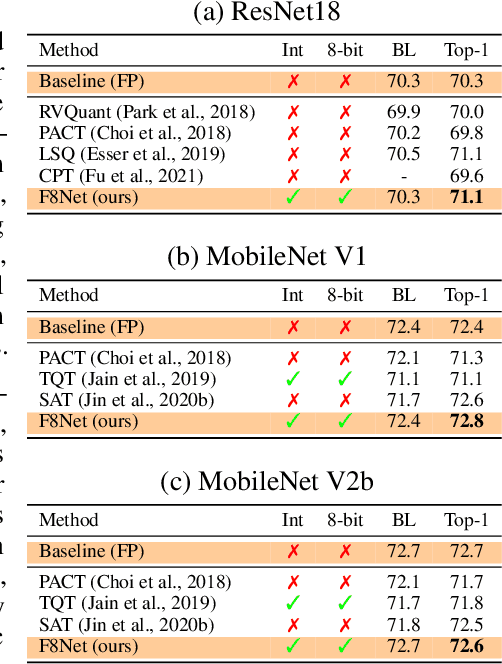
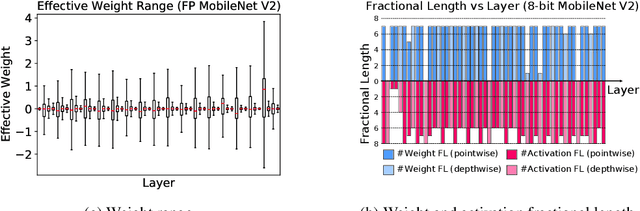
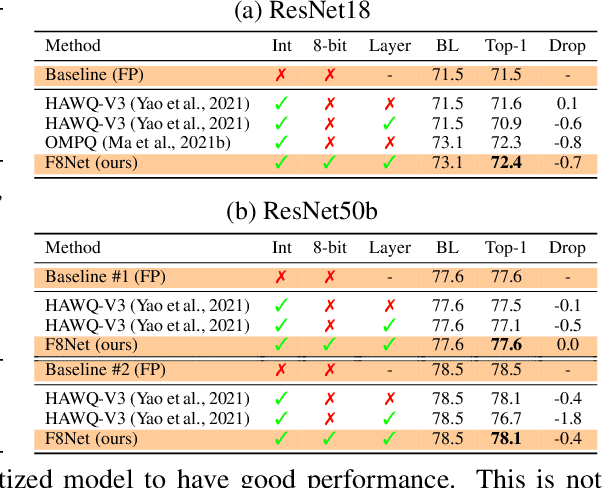
Neural network quantization is a promising compression technique to reduce memory footprint and save energy consumption, potentially leading to real-time inference. However, there is a performance gap between quantized and full-precision models. To reduce it, existing quantization approaches require high-precision INT32 or full-precision multiplication during inference for scaling or dequantization. This introduces a noticeable cost in terms of memory, speed, and required energy. To tackle these issues, we present F8Net, a novel quantization framework consisting of only fixed-point 8-bit multiplication. To derive our method, we first discuss the advantages of fixed-point multiplication with different formats of fixed-point numbers and study the statistical behavior of the associated fixed-point numbers. Second, based on the statistical and algorithmic analysis, we apply different fixed-point formats for weights and activations of different layers. We introduce a novel algorithm to automatically determine the right format for each layer during training. Third, we analyze a previous quantization algorithm -- parameterized clipping activation (PACT) -- and reformulate it using fixed-point arithmetic. Finally, we unify the recently proposed method for quantization fine-tuning and our fixed-point approach to show the potential of our method. We verify F8Net on ImageNet for MobileNet V1/V2 and ResNet18/50. Our approach achieves comparable and better performance, when compared not only to existing quantization techniques with INT32 multiplication or floating-point arithmetic, but also to the full-precision counterparts, achieving state-of-the-art performance.
Coarsening the Granularity: Towards Structurally Sparse Lottery Tickets
Feb 09, 2022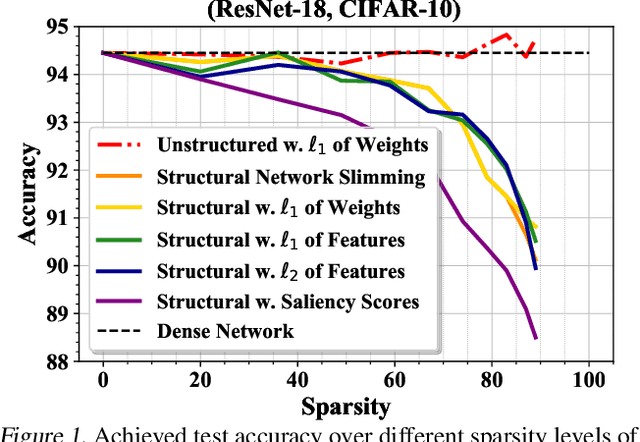
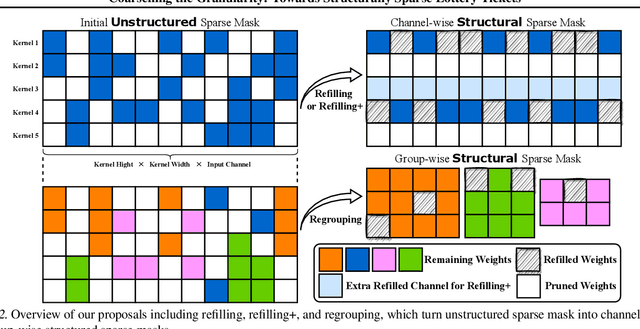
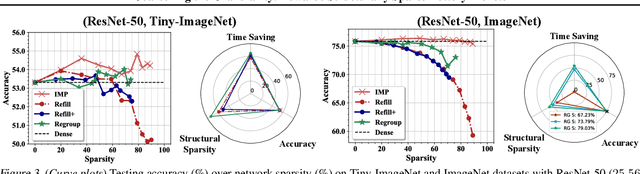
The lottery ticket hypothesis (LTH) has shown that dense models contain highly sparse subnetworks (i.e., winning tickets) that can be trained in isolation to match full accuracy. Despite many exciting efforts being made, there is one "commonsense" seldomly challenged: a winning ticket is found by iterative magnitude pruning (IMP) and hence the resultant pruned subnetworks have only unstructured sparsity. That gap limits the appeal of winning tickets in practice, since the highly irregular sparse patterns are challenging to accelerate on hardware. Meanwhile, directly substituting structured pruning for unstructured pruning in IMP damages performance more severely and is usually unable to locate winning tickets. In this paper, we demonstrate the first positive result that a structurally sparse winning ticket can be effectively found in general. The core idea is to append "post-processing techniques" after each round of (unstructured) IMP, to enforce the formation of structural sparsity. Specifically, we first "re-fill" pruned elements back in some channels deemed to be important, and then "re-group" non-zero elements to create flexible group-wise structural patterns. Both our identified channel- and group-wise structural subnetworks win the lottery, with substantial inference speedups readily supported by existing hardware. Extensive experiments, conducted on diverse datasets across multiple network backbones, consistently validate our proposal, showing that the hardware acceleration roadblock of LTH is now removed. Specifically, the structural winning tickets obtain up to {64.93%, 64.84%, 64.84%} running time savings at {36% ~ 80%, 74%, 58%} sparsity on {CIFAR, Tiny-ImageNet, ImageNet}, while maintaining comparable accuracy. Codes are available in https://github.com/VITA-Group/Structure-LTH.
AirNN: Neural Networks with Over-the-Air Convolution via Reconfigurable Intelligent Surfaces
Feb 07, 2022



Over-the-air analog computation allows offloading computation to the wireless environment through carefully constructed transmitted signals. In this paper, we design and implement the first-of-its-kind over-the-air convolution and demonstrate it for inference tasks in a convolutional neural network (CNN). We engineer the ambient wireless propagation environment through reconfigurable intelligent surfaces (RIS) to design such an architecture, which we call 'AirNN'. AirNN leverages the physics of wave reflection to represent a digital convolution, an essential part of a CNN architecture, in the analog domain. In contrast to classical communication, where the receiver must react to the channel-induced transformation, generally represented as finite impulse response (FIR) filter, AirNN proactively creates the signal reflections to emulate specific FIR filters through RIS. AirNN involves two steps: first, the weights of the neurons in the CNN are drawn from a finite set of channel impulse responses (CIR) that correspond to realizable FIR filters. Second, each CIR is engineered through RIS, and reflected signals combine at the receiver to determine the output of the convolution. This paper presents a proof-of-concept of AirNN by experimentally demonstrating over-the-air convolutions. We then validate the entire resulting CNN model accuracy via simulations for an example task of modulation classification.
VAQF: Fully Automatic Software-hardware Co-design Framework for Low-bit Vision Transformer
Jan 17, 2022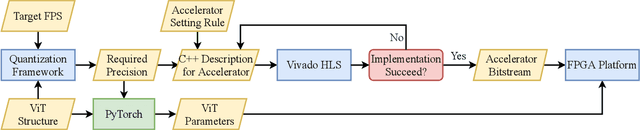
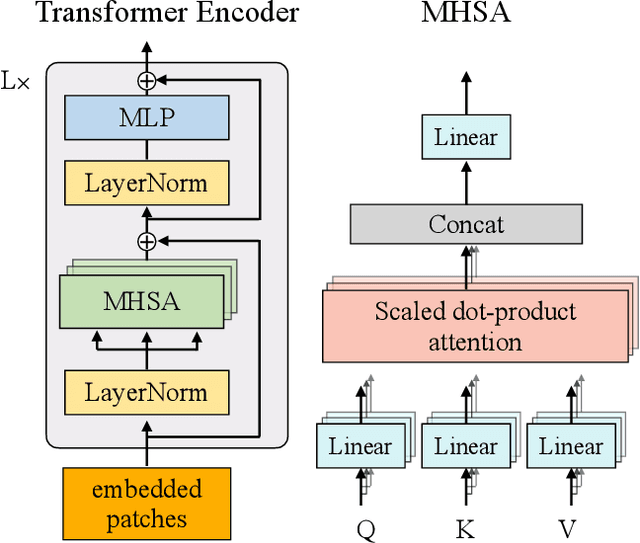
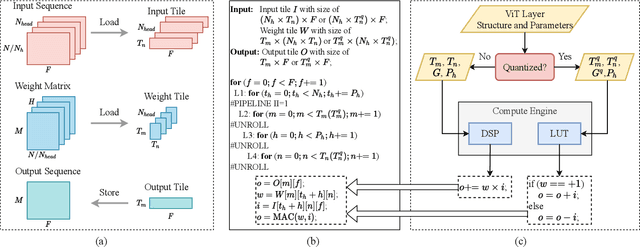
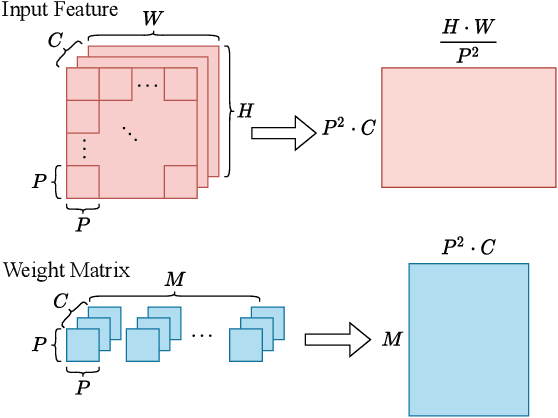
The transformer architectures with attention mechanisms have obtained success in Nature Language Processing (NLP), and Vision Transformers (ViTs) have recently extended the application domains to various vision tasks. While achieving high performance, ViTs suffer from large model size and high computation complexity that hinders the deployment of them on edge devices. To achieve high throughput on hardware and preserve the model accuracy simultaneously, we propose VAQF, a framework that builds inference accelerators on FPGA platforms for quantized ViTs with binary weights and low-precision activations. Given the model structure and the desired frame rate, VAQF will automatically output the required quantization precision for activations as well as the optimized parameter settings of the accelerator that fulfill the hardware requirements. The implementations are developed with Vivado High-Level Synthesis (HLS) on the Xilinx ZCU102 FPGA board, and the evaluation results with the DeiT-base model indicate that a frame rate requirement of 24 frames per second (FPS) is satisfied with 8-bit activation quantization, and a target of 30 FPS is met with 6-bit activation quantization. To the best of our knowledge, this is the first time quantization has been incorporated into ViT acceleration on FPGAs with the help of a fully automatic framework to guide the quantization strategy on the software side and the accelerator implementations on the hardware side given the target frame rate. Very small compilation time cost is incurred compared with quantization training, and the generated accelerators show the capability of achieving real-time execution for state-of-the-art ViT models on FPGAs.
SPViT: Enabling Faster Vision Transformers via Soft Token Pruning
Dec 27, 2021

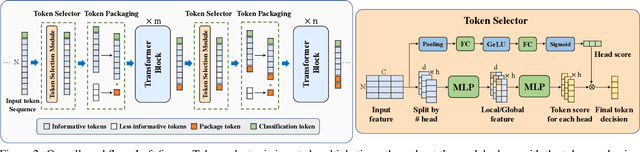
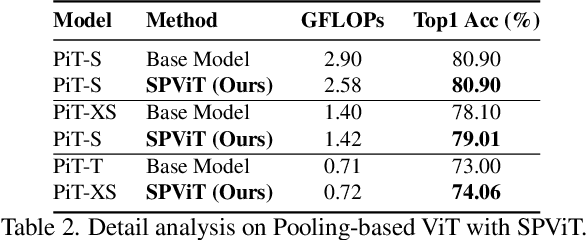
Recently, Vision Transformer (ViT) has continuously established new milestones in the computer vision field, while the high computation and memory cost makes its propagation in industrial production difficult. Pruning, a traditional model compression paradigm for hardware efficiency, has been widely applied in various DNN structures. Nevertheless, it stays ambiguous on how to perform exclusive pruning on the ViT structure. Considering three key points: the structural characteristics, the internal data pattern of ViTs, and the related edge device deployment, we leverage the input token sparsity and propose a computation-aware soft pruning framework, which can be set up on vanilla Transformers of both flatten and CNN-type structures, such as Pooling-based ViT (PiT). More concretely, we design a dynamic attention-based multi-head token selector, which is a lightweight module for adaptive instance-wise token selection. We further introduce a soft pruning technique, which integrates the less informative tokens generated by the selector module into a package token that will participate in subsequent calculations rather than being completely discarded. Our framework is bound to the trade-off between accuracy and computation constraints of specific edge devices through our proposed computation-aware training strategy. Experimental results show that our framework significantly reduces the computation cost of ViTs while maintaining comparable performance on image classification. Moreover, our framework can guarantee the identified model to meet resource specifications of mobile devices and FPGA, and even achieve the real-time execution of DeiT-T on mobile platforms. For example, our method reduces the latency of DeiT-T to 26 ms (26%$\sim $41% superior to existing works) on the mobile device with 0.25%$\sim $4% higher top-1 accuracy on ImageNet. Our code will be released soon.
Compact Multi-level Sparse Neural Networks with Input Independent Dynamic Rerouting
Dec 21, 2021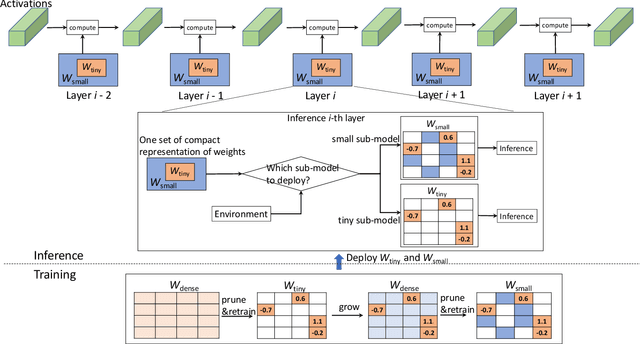

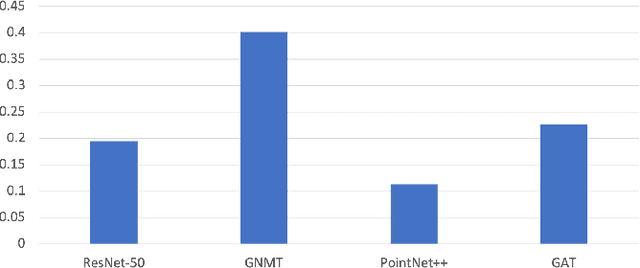
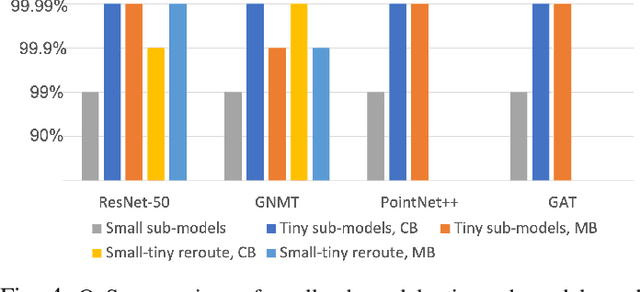
Deep neural networks (DNNs) have shown to provide superb performance in many real life applications, but their large computation cost and storage requirement have prevented them from being deployed to many edge and internet-of-things (IoT) devices. Sparse deep neural networks, whose majority weight parameters are zeros, can substantially reduce the computation complexity and memory consumption of the models. In real-use scenarios, devices may suffer from large fluctuations of the available computation and memory resources under different environment, and the quality of service (QoS) is difficult to maintain due to the long tail inferences with large latency. Facing the real-life challenges, we propose to train a sparse model that supports multiple sparse levels. That is, a hierarchical structure of weights are satisfied such that the locations and the values of the non-zero parameters of the more-sparse sub-model area subset of the less-sparse sub-model. In this way, one can dynamically select the appropriate sparsity level during inference, while the storage cost is capped by the least sparse sub-model. We have verified our methodologies on a variety of DNN models and tasks, including the ResNet-50, PointNet++, GNMT, and graph attention networks. We obtain sparse sub-models with an average of 13.38% weights and 14.97% FLOPs, while the accuracies are as good as their dense counterparts. More-sparse sub-models with 5.38% weights and 4.47% of FLOPs, which are subsets of the less-sparse ones, can be obtained with only 3.25% relative accuracy loss.
Automatic Mapping of the Best-Suited DNN Pruning Schemes for Real-Time Mobile Acceleration
Nov 22, 2021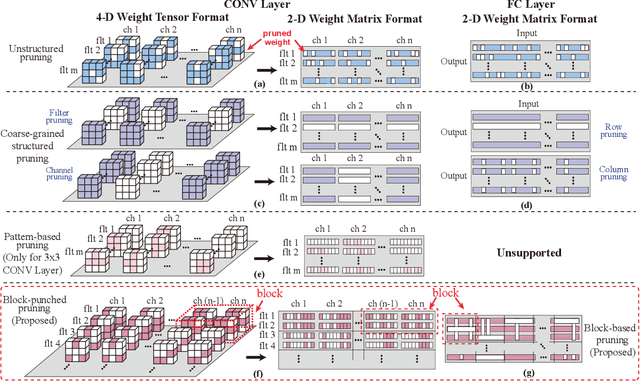

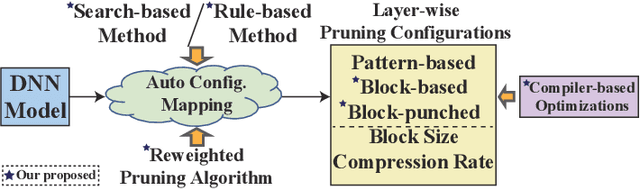
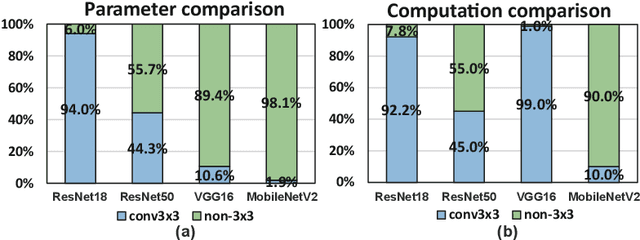
Weight pruning is an effective model compression technique to tackle the challenges of achieving real-time deep neural network (DNN) inference on mobile devices. However, prior pruning schemes have limited application scenarios due to accuracy degradation, difficulty in leveraging hardware acceleration, and/or restriction on certain types of DNN layers. In this paper, we propose a general, fine-grained structured pruning scheme and corresponding compiler optimizations that are applicable to any type of DNN layer while achieving high accuracy and hardware inference performance. With the flexibility of applying different pruning schemes to different layers enabled by our compiler optimizations, we further probe into the new problem of determining the best-suited pruning scheme considering the different acceleration and accuracy performance of various pruning schemes. Two pruning scheme mapping methods, one is search-based and the other is rule-based, are proposed to automatically derive the best-suited pruning regularity and block size for each layer of any given DNN. Experimental results demonstrate that our pruning scheme mapping methods, together with the general fine-grained structured pruning scheme, outperform the state-of-the-art DNN optimization framework with up to 2.48$\times$ and 1.73$\times$ DNN inference acceleration on CIFAR-10 and ImageNet dataset without accuracy loss.
ScaleCert: Scalable Certified Defense against Adversarial Patches with Sparse Superficial Layers
Nov 04, 2021
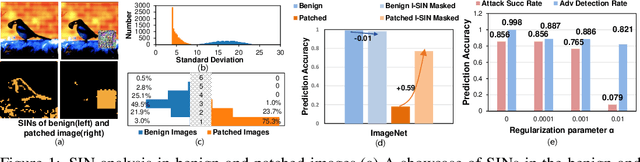
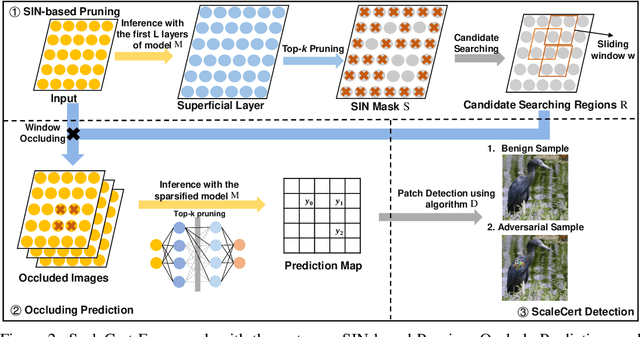
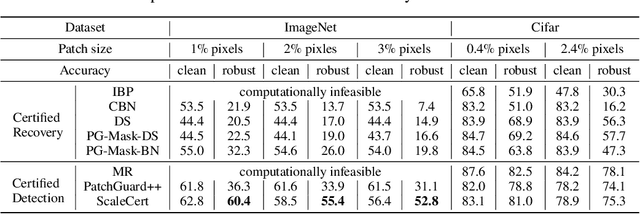
Adversarial patch attacks that craft the pixels in a confined region of the input images show their powerful attack effectiveness in physical environments even with noises or deformations. Existing certified defenses towards adversarial patch attacks work well on small images like MNIST and CIFAR-10 datasets, but achieve very poor certified accuracy on higher-resolution images like ImageNet. It is urgent to design both robust and effective defenses against such a practical and harmful attack in industry-level larger images. In this work, we propose the certified defense methodology that achieves high provable robustness for high-resolution images and largely improves the practicality for real adoption of the certified defense. The basic insight of our work is that the adversarial patch intends to leverage localized superficial important neurons (SIN) to manipulate the prediction results. Hence, we leverage the SIN-based DNN compression techniques to significantly improve the certified accuracy, by reducing the adversarial region searching overhead and filtering the prediction noises. Our experimental results show that the certified accuracy is increased from 36.3% (the state-of-the-art certified detection) to 60.4% on the ImageNet dataset, largely pushing the certified defenses for practical use.
ILMPQ : An Intra-Layer Multi-Precision Deep Neural Network Quantization framework for FPGA
Oct 30, 2021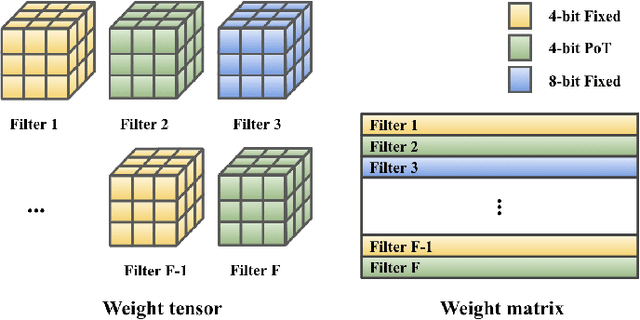
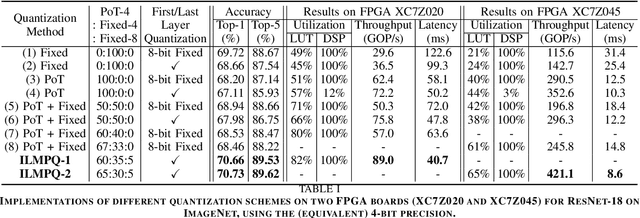
This work targets the commonly used FPGA (field-programmable gate array) devices as the hardware platform for DNN edge computing. We focus on DNN quantization as the main model compression technique. The novelty of this work is: We use a quantization method that supports multiple precisions along the intra-layer dimension, while the existing quantization methods apply multi-precision quantization along the inter-layer dimension. The intra-layer multi-precision method can uniform the hardware configurations for different layers to reduce computation overhead and at the same time preserve the model accuracy as the inter-layer approach. Our proposed ILMPQ DNN quantization framework achieves 70.73 Top1 accuracy in ResNet-18 on the ImageNet dataset. We also validate the proposed MSP framework on two FPGA devices i.e., Xilinx XC7Z020 and XC7Z045. We achieve 3.65x speedup in end-to-end inference time on the ImageNet, compared with the fixed-point quantization method.
RMSMP: A Novel Deep Neural Network Quantization Framework with Row-wise Mixed Schemes and Multiple Precisions
Oct 30, 2021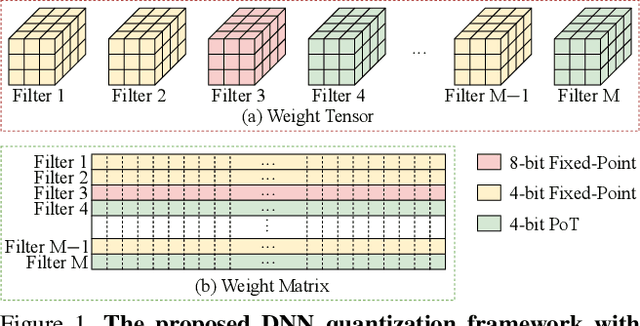
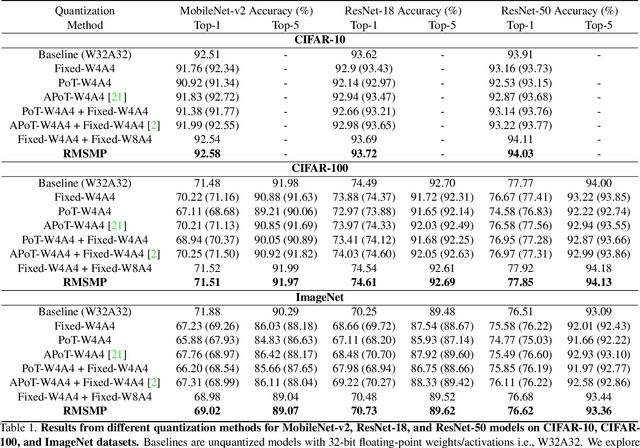
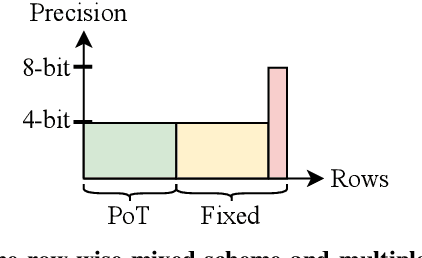
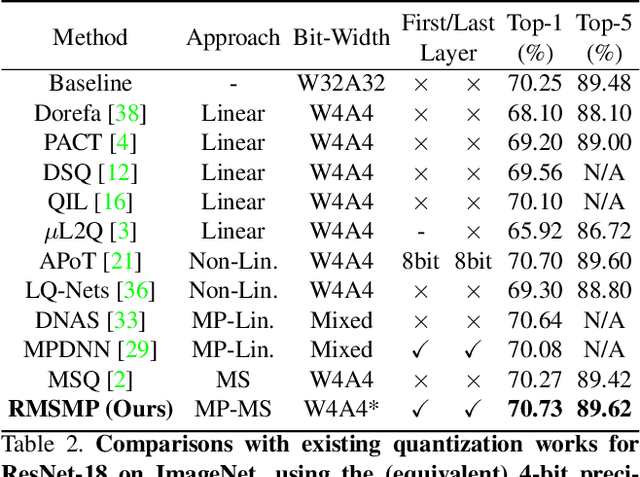
This work proposes a novel Deep Neural Network (DNN) quantization framework, namely RMSMP, with a Row-wise Mixed-Scheme and Multi-Precision approach. Specifically, this is the first effort to assign mixed quantization schemes and multiple precisions within layers -- among rows of the DNN weight matrix, for simplified operations in hardware inference, while preserving accuracy. Furthermore, this paper makes a different observation from the prior work that the quantization error does not necessarily exhibit the layer-wise sensitivity, and actually can be mitigated as long as a certain portion of the weights in every layer are in higher precisions. This observation enables layer-wise uniformality in the hardware implementation towards guaranteed inference acceleration, while still enjoying row-wise flexibility of mixed schemes and multiple precisions to boost accuracy. The candidates of schemes and precisions are derived practically and effectively with a highly hardware-informative strategy to reduce the problem search space. With the offline determined ratio of different quantization schemes and precisions for all the layers, the RMSMP quantization algorithm uses the Hessian and variance-based method to effectively assign schemes and precisions for each row. The proposed RMSMP is tested for the image classification and natural language processing (BERT) applications and achieves the best accuracy performance among state-of-the-arts under the same equivalent precisions. The RMSMP is implemented on FPGA devices, achieving 3.65x speedup in the end-to-end inference time for ResNet-18 on ImageNet, compared with the 4-bit Fixed-point baseline.