 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Muon Beyond Pretraining: Spectral Failures and High-Pass Remedies for VLA and RLVR
May 19, 2026Muon is a matrix-aware optimizer that leverages Newton-Schulz (NS) iterations to enforce spectral gradient orthogonalization by driving all singular values of the momentum matrix toward 1. While this uniform spectral whitening enhances exploration and outperforms AdamW in LLM pretraining, we show it could lead to fundamental limitations beyond pretraining in two regimes: (i) cross-modality vision-language-action (VLA) training, where inherently low-rank action-module gradients cause amplification of noisy tail directions, and (ii) reinforcement learning with verifiable rewards (RLVR), where low-SNR gradients and the need to preserve per-head specialization from prior training make whitening unstable. To address these challenges, we propose Pion, a drop-in replacement for Muon that preserves its computational efficiency while replacing uniform spectral whitening with a two-stage Promotion+Suppression mechanism, which we call the high-pass NS iteration. This design induces a sharp spectral high-pass effect, anchoring dominant singular values at 1 while suppressing noisy tail components toward 0, with controllable filter strength. To preserve pretrained per-head heterogeneity, Pion also supports a per-head mode that applies updates independently across attention heads via a simple reshape, at no extra cost. In VLA training on LIBERO and LIBERO-Plus, Pion consistently outperforms both baselines across l_1-regression (VLA-Adapter) and flow-matching (VLANeXt) architectures, e.g., reaching 100% success rate on LIBERO Object after 1,500 training steps with VLA-Adapter, vs. 97.0% for Muon and only 32.2% for AdamW. The advantage of Pion further extends to a real Franka Research 3 robot with a pi_0.5 backbone under the DROID setup on three grasp-and-place tasks. In RLVR post-training on Qwen3-1.7B/4B with GRPO and GMPO, Pion also outperforms AdamW on MATH and GSM8K while Muon collapses to zero.
Visual prompting reimagined: The power of the Activation Prompts
Apr 07, 2026Visual prompting (VP) has emerged as a popular method to repurpose pretrained vision models for adaptation to downstream tasks. Unlike conventional model fine-tuning techniques, VP introduces a universal perturbation directly into the input data to facilitate task-specific fine-tuning rather than modifying model parameters. However, there exists a noticeable performance gap between VP and conventional fine-tuning methods, highlighting an unexplored realm in theory and practice to understand and advance the input-level VP to reduce its current performance gap. Towards this end, we introduce a generalized concept, termed activation prompt (AP), which extends the scope of the input-level VP by enabling universal perturbations to be applied to activation maps within the intermediate layers of the model. By using AP to revisit the problem of VP and employing it as an analytical tool, we demonstrate the intrinsic limitations of VP in both performance and efficiency, revealing why input-level prompting may lack effectiveness compared to AP, which exhibits a model-dependent layer preference. We show that AP is closely related to normalization tuning in convolutional neural networks and vision transformers, although each model type has distinct layer preferences for prompting. We also theoretically elucidate the rationale behind such a preference by analyzing global features across layers. Through extensive experiments across 29 datasets and various model architectures, we provide a comprehensive performance analysis of AP, comparing it with VP and parameter-efficient fine-tuning baselines. Our results demonstrate AP's superiority in both accuracy and efficiency, considering factors such as time, parameters, memory usage, and throughput.
Subspace Control: Turning Constrained Model Steering into Controllable Spectral Optimization
Apr 05, 2026Foundation models, such as large language models (LLMs), are powerful but often require customization before deployment to satisfy practical constraints such as safety, privacy, and task-specific requirements, leading to "constrained" optimization problems for model steering and adaptation. However, solving such problems remains largely underexplored and is particularly challenging due to interference between the primary objective and constraint objectives during optimization. In this paper, we propose a subspace control framework for constrained model training. Specifically, (i) we first analyze, from a model merging perspective, how spectral cross-task interference arises and show that it can be resolved via a one-shot solution that orthogonalizes the merged subspace; (ii) we establish a connection between this solution and gradient orthogonalization in the spectral optimizer Muon; and (iii) building on these insights, we introduce SIFT (spectral interference-free training), which leverages a localization scheme to selectively intervene during optimization, enabling controllable updates that mitigate objective-constraint conflicts. We evaluate SIFT across four representative applications: (a) machine unlearning, (b) safety alignment, (c) text-to-speech adaptation, and (d) hallucination mitigation. Compared to both control-based and control-free baselines, SIFT consistently achieves substantial and robust performance improvements across all tasks. Code is available at https://github.com/OPTML-Group/SIFT.
Attention Smoothing Is All You Need For Unlearning
Mar 01, 2026Large Language Models are prone to memorizing sensitive, copyrighted, or hazardous content, posing significant privacy and legal concerns. Retraining from scratch is computationally infeasible, whereas current unlearning methods exhibit unstable trade-offs between forgetting and utility, frequently producing incoherent outputs on forget prompts and failing to generalize due to the persistence of lexical-level and semantic-level associations in attention. We propose Attention Smoothing Unlearning (ASU), a principled framework that casts unlearning as self-distillation from a forget-teacher derived from the model's own attention. By increasing the softmax temperature, ASU flattens attention distributions and directly suppresses the lexical-level and semantic-level associations responsible for reconstructing memorized knowledge. This results in a bounded optimization objective that erases factual information yet maintains coherence in responses to forget prompts. Empirical evaluation on TOFU, MUSE, and WMDP, along with real-world and continual unlearning scenarios across question answering and text completion, demonstrates that ASU outperforms the baselines for most unlearning scenarios, delivering robust unlearning with minimal loss of model utility.
Powering Up Zeroth-Order Training via Subspace Gradient Orthogonalization
Feb 19, 2026Zeroth-order (ZO) optimization provides a gradient-free alternative to first-order (FO) methods by estimating gradients via finite differences of function evaluations, and has recently emerged as a memory-efficient paradigm for fine-tuning large-scale models by avoiding backpropagation. However, ZO optimization has a fundamental tension between accuracy and query efficiency. In this work, we show that ZO optimization can be substantially improved by unifying two complementary principles: (i) a projection-based subspace view that reduces gradient estimation variance by exploiting the intrinsic low-rank structure of model updates, and (ii) Muon-style spectral optimization that applies gradient orthogonalization to extract informative spectral structure from noisy ZO gradients. These findings form a unified framework of subspace gradient orthogonalization, which we instantiate in a new method, ZO-Muon, admitting a natural interpretation as a low-rank Muon optimizer in the ZO setting. Extensive experiments on large language models (LLMs) and vision transformers (ViTs) demonstrate that ZO-Muon significantly accelerates convergence and achieves a win-win improvement in accuracy and query/runtime efficiency. Notably, compared to the popular MeZO baseline, ZO-Muon requires only 24.7% of the queries to reach the same SST-2 performance for LLM fine-tuning, and improves accuracy by 25.1% on ViT-B fine-tuning on CIFAR-100.
TEON: Tensorized Orthonormalization Beyond Layer-Wise Muon for Large Language Model Pre-Training
Jan 30, 2026The Muon optimizer has demonstrated strong empirical performance in pre-training large language models by performing matrix-level gradient (or momentum) orthogonalization in each layer independently. In this work, we propose TEON, a principled generalization of Muon that extends orthogonalization beyond individual layers by modeling the gradients of a neural network as a structured higher-order tensor. We present TEON's improved convergence guarantee over layer-wise Muon, and further develop a practical instantiation of TEON based on the theoretical analysis with corresponding ablation. We evaluate our approach on two widely adopted architectures: GPT-style models, ranging from 130M to 774M parameters, and LLaMA-style models, ranging from 60M to 1B parameters. Experimental results show that TEON consistently improves training and validation perplexity across model scales and exhibits strong robustness under various approximate SVD schemes.
Leak@$k$: Unlearning Does Not Make LLMs Forget Under Probabilistic Decoding
Nov 07, 2025Unlearning in large language models (LLMs) is critical for regulatory compliance and for building ethical generative AI systems that avoid producing private, toxic, illegal, or copyrighted content. Despite rapid progress, in this work we show that \textit{almost all} existing unlearning methods fail to achieve true forgetting in practice. Specifically, while evaluations of these `unlearned' models under deterministic (greedy) decoding often suggest successful knowledge removal using standard benchmarks (as has been done in the literature), we show that sensitive information reliably resurfaces when models are sampled with standard probabilistic decoding. To rigorously capture this vulnerability, we introduce \texttt{leak@$k$}, a new meta-evaluation metric that quantifies the likelihood of forgotten knowledge reappearing when generating $k$ samples from the model under realistic decoding strategies. Using three widely adopted benchmarks, TOFU, MUSE, and WMDP, we conduct the first large-scale, systematic study of unlearning reliability using our newly defined \texttt{leak@$k$} metric. Our findings demonstrate that knowledge leakage persists across methods and tasks, underscoring that current state-of-the-art unlearning techniques provide only limited forgetting and highlighting the urgent need for more robust approaches to LLM unlearning.
Downgrade to Upgrade: Optimizer Simplification Enhances Robustness in LLM Unlearning
Oct 02, 2025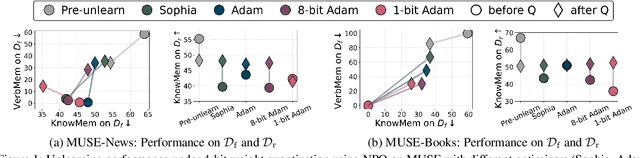
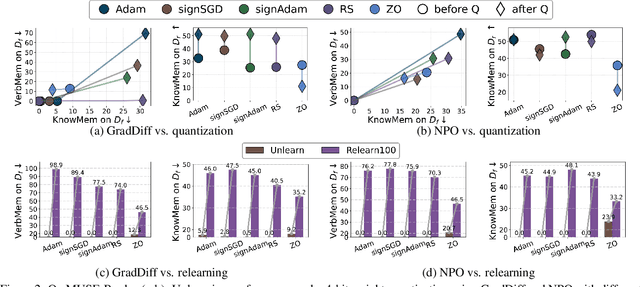

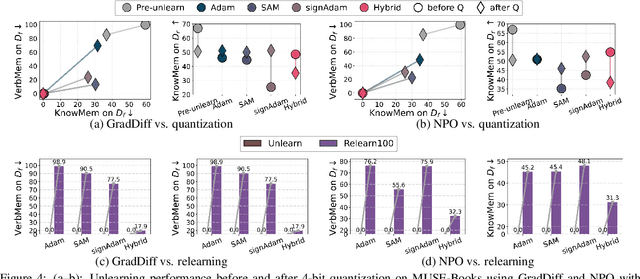
Large language model (LLM) unlearning aims to surgically remove the influence of undesired data or knowledge from an existing model while preserving its utility on unrelated tasks. This paradigm has shown promise in addressing privacy and safety concerns. However, recent findings reveal that unlearning effects are often fragile: post-unlearning manipulations such as weight quantization or fine-tuning can quickly neutralize the intended forgetting. Prior efforts to improve robustness primarily reformulate unlearning objectives by explicitly assuming the role of vulnerability sources. In this work, we take a different perspective by investigating the role of the optimizer, independent of unlearning objectives and formulations, in shaping unlearning robustness. We show that the 'grade' of the optimizer, defined by the level of information it exploits, ranging from zeroth-order (gradient-free) to first-order (gradient-based) to second-order (Hessian-based), is tightly linked to the resilience of unlearning. Surprisingly, we find that downgrading the optimizer, such as using zeroth-order methods or compressed-gradient variants (e.g., gradient sign-based optimizers), often leads to stronger robustness. While these optimizers produce noisier and less precise updates, they encourage convergence to harder-to-disturb basins in the loss landscape, thereby resisting post-training perturbations. By connecting zeroth-order methods with randomized smoothing, we further highlight their natural advantage for robust unlearning. Motivated by these insights, we propose a hybrid optimizer that combines first-order and zeroth-order updates, preserving unlearning efficacy while enhancing robustness. Extensive experiments on the MUSE and WMDP benchmarks, across multiple LLM unlearning algorithms, validate that our approach achieves more resilient forgetting without sacrificing unlearning quality.
Reasoning Model Unlearning: Forgetting Traces, Not Just Answers, While Preserving Reasoning Skills
Jun 15, 2025Recent advances in large reasoning models (LRMs) have enabled strong chain-of-thought (CoT) generation through test-time computation. While these multi-step reasoning capabilities represent a major milestone in language model performance, they also introduce new safety risks. In this work, we present the first systematic study to revisit the problem of machine unlearning in the context of LRMs. Machine unlearning refers to the process of removing the influence of sensitive, harmful, or undesired data or knowledge from a trained model without full retraining. We show that conventional unlearning algorithms, originally designed for non-reasoning models, are inadequate for LRMs. In particular, even when final answers are successfully erased, sensitive information often persists within the intermediate reasoning steps, i.e., CoT trajectories. To address this challenge, we extend conventional unlearning and propose Reasoning-aware Representation Misdirection for Unlearning ($R^2MU$), a novel method that effectively suppresses sensitive reasoning traces and prevents the generation of associated final answers, while preserving the model's reasoning ability. Our experiments demonstrate that $R^2MU$ significantly reduces sensitive information leakage within reasoning traces and achieves strong performance across both safety and reasoning benchmarks, evaluated on state-of-the-art models such as DeepSeek-R1-Distill-LLaMA-8B and DeepSeek-R1-Distill-Qwen-14B.
BLUR: A Bi-Level Optimization Approach for LLM Unlearning
Jun 09, 2025Enabling large language models (LLMs) to unlearn knowledge and capabilities acquired during training has proven vital for ensuring compliance with data regulations and promoting ethical practices in generative AI. Although there are growing interests in developing various unlearning algorithms, it remains unclear how to best formulate the unlearning problem. The most popular formulation uses a weighted sum of forget and retain loss, but it often leads to performance degradation due to the inherent trade-off between forget and retain losses. In this work, we argue that it is important to model the hierarchical structure of the unlearning problem, where the forget problem (which \textit{unlearns} certain knowledge and/or capabilities) takes priority over the retain problem (which preserves model utility). This hierarchical structure naturally leads to a bi-level optimization formulation where the lower-level objective focuses on minimizing the forget loss, while the upper-level objective aims to maintain the model's utility. Based on this new formulation, we propose a novel algorithm, termed Bi-Level UnleaRning (\texttt{BLUR}), which not only possesses strong theoretical guarantees but more importantly, delivers superior performance. In particular, our extensive experiments demonstrate that \texttt{BLUR} consistently outperforms all the state-of-the-art algorithms across various unlearning tasks, models, and metrics. Codes are available at https://github.com/OptimAI-Lab/BLURLLMUnlearning.