 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Diffusion Model Predictions Through Dimensionality
Jan 29, 2026Recent advances in diffusion and flow matching models have highlighted a shift in the preferred prediction target -- moving from noise ($\varepsilon$) and velocity (v) to direct data (x) prediction -- particularly in high-dimensional settings. However, a formal explanation of why the optimal target depends on the specific properties of the data remains elusive. In this work, we provide a theoretical framework based on a generalized prediction formulation that accommodates arbitrary output targets, of which $\varepsilon$-, v-, and x-prediction are special cases. We derive the analytical relationship between data's geometry and the optimal prediction target, offering a rigorous justification for why x-prediction becomes superior when the ambient dimension significantly exceeds the data's intrinsic dimension. Furthermore, while our theory identifies dimensionality as the governing factor for the optimal prediction target, the intrinsic dimension of manifold-bound data is typically intractable to estimate in practice. To bridge this gap, we propose k-Diff, a framework that employs a data-driven approach to learn the optimal prediction parameter k directly from data, bypassing the need for explicit dimension estimation. Extensive experiments in both latent-space and pixel-space image generation demonstrate that k-Diff consistently outperforms fixed-target baselines across varying architectures and data scales, providing a principled and automated approach to enhancing generative performance.
LowDiff: Efficient Diffusion Sampling with Low-Resolution Condition
Sep 18, 2025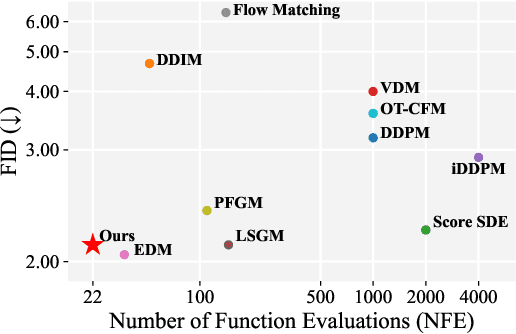
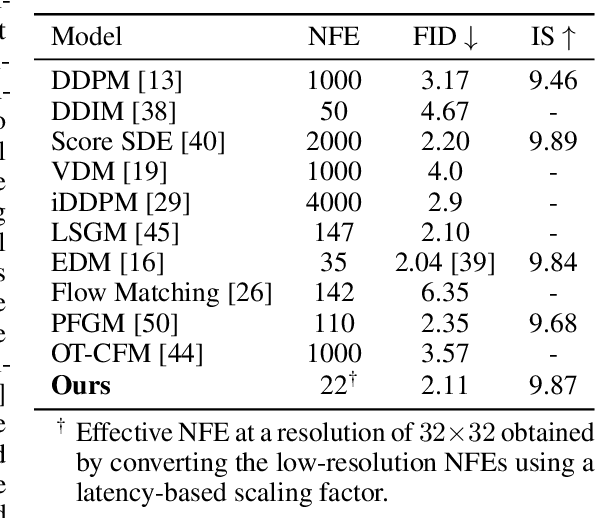
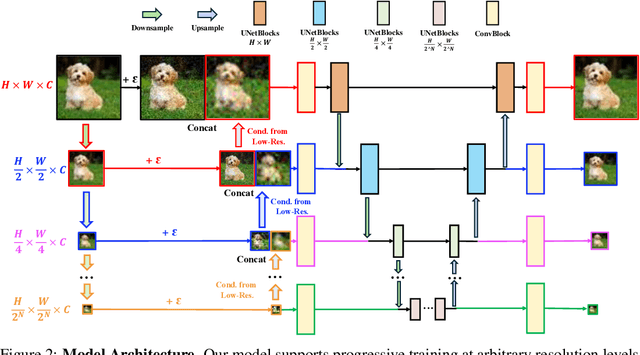
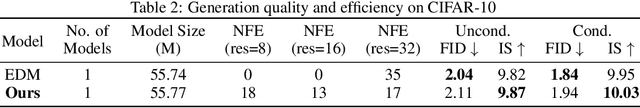
Diffusion models have achieved remarkable success in image generation but their practical application is often hindered by the slow sampling speed. Prior efforts of improving efficiency primarily focus on compressing models or reducing the total number of denoising steps, largely neglecting the possibility to leverage multiple input resolutions in the generation process. In this work, we propose LowDiff, a novel and efficient diffusion framework based on a cascaded approach by generating increasingly higher resolution outputs. Besides, LowDiff employs a unified model to progressively refine images from low resolution to the desired resolution. With the proposed architecture design and generation techniques, we achieve comparable or even superior performance with much fewer high-resolution sampling steps. LowDiff is applicable to diffusion models in both pixel space and latent space. Extensive experiments on both conditional and unconditional generation tasks across CIFAR-10, FFHQ and ImageNet demonstrate the effectiveness and generality of our method. Results show over 50% throughput improvement across all datasets and settings while maintaining comparable or better quality. On unconditional CIFAR-10, LowDiff achieves an FID of 2.11 and IS of 9.87, while on conditional CIFAR-10, an FID of 1.94 and IS of 10.03. On FFHQ 64x64, LowDiff achieves an FID of 2.43, and on ImageNet 256x256, LowDiff built on LightningDiT-B/1 produces high-quality samples with a FID of 4.00 and an IS of 195.06, together with substantial efficiency gains.
E$^{2}$GAN: Efficient Training of Efficient GANs for Image-to-Image Translation
Jan 11, 2024



One highly promising direction for enabling flexible real-time on-device image editing is utilizing data distillation by leveraging large-scale text-to-image diffusion models, such as Stable Diffusion, to generate paired datasets used for training generative adversarial networks (GANs). This approach notably alleviates the stringent requirements typically imposed by high-end commercial GPUs for performing image editing with diffusion models. However, unlike text-to-image diffusion models, each distilled GAN is specialized for a specific image editing task, necessitating costly training efforts to obtain models for various concepts. In this work, we introduce and address a novel research direction: can the process of distilling GANs from diffusion models be made significantly more efficient? To achieve this goal, we propose a series of innovative techniques. First, we construct a base GAN model with generalized features, adaptable to different concepts through fine-tuning, eliminating the need for training from scratch. Second, we identify crucial layers within the base GAN model and employ Low-Rank Adaptation (LoRA) with a simple yet effective rank search process, rather than fine-tuning the entire base model. Third, we investigate the minimal amount of data necessary for fine-tuning, further reducing the overall training time. Extensive experiments show that we can efficiently empower GANs with the ability to perform real-time high-quality image editing on mobile devices with remarkable reduced training cost and storage for each concept.
SnapFusion: Text-to-Image Diffusion Model on Mobile Devices within Two Seconds
Jun 03, 2023Text-to-image diffusion models can create stunning images from natural language descriptions that rival the work of professional artists and photographers. However, these models are large, with complex network architectures and tens of denoising iterations, making them computationally expensive and slow to run. As a result, high-end GPUs and cloud-based inference are required to run diffusion models at scale. This is costly and has privacy implications, especially when user data is sent to a third party. To overcome these challenges, we present a generic approach that, for the first time, unlocks running text-to-image diffusion models on mobile devices in less than $2$ seconds. We achieve so by introducing efficient network architecture and improving step distillation. Specifically, we propose an efficient UNet by identifying the redundancy of the original model and reducing the computation of the image decoder via data distillation. Further, we enhance the step distillation by exploring training strategies and introducing regularization from classifier-free guidance. Our extensive experiments on MS-COCO show that our model with $8$ denoising steps achieves better FID and CLIP scores than Stable Diffusion v$1.5$ with $50$ steps. Our work democratizes content creation by bringing powerful text-to-image diffusion models to the hands of users.
PIM-QAT: Neural Network Quantization for Processing-In-Memory (PIM) Systems
Sep 18, 2022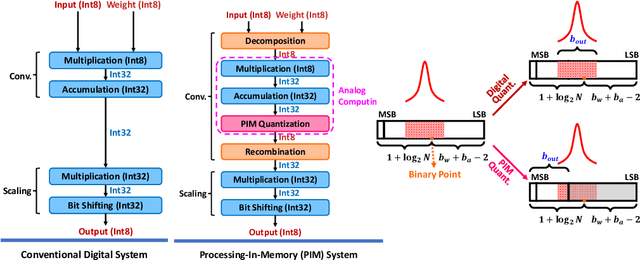

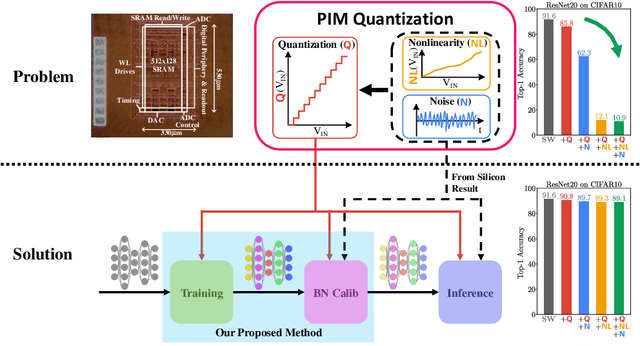

Processing-in-memory (PIM), an increasingly studied neuromorphic hardware, promises orders of energy and throughput improvements for deep learning inference. Leveraging the massively parallel and efficient analog computing inside memories, PIM circumvents the bottlenecks of data movements in conventional digital hardware. However, an extra quantization step (i.e. PIM quantization), typically with limited resolution due to hardware constraints, is required to convert the analog computing results into digital domain. Meanwhile, non-ideal effects extensively exist in PIM quantization because of the imperfect analog-to-digital interface, which further compromises the inference accuracy. In this paper, we propose a method for training quantized networks to incorporate PIM quantization, which is ubiquitous to all PIM systems. Specifically, we propose a PIM quantization aware training (PIM-QAT) algorithm, and introduce rescaling techniques during backward and forward propagation by analyzing the training dynamics to facilitate training convergence. We also propose two techniques, namely batch normalization (BN) calibration and adjusted precision training, to suppress the adverse effects of non-ideal linearity and stochastic thermal noise involved in real PIM chips. Our method is validated on three mainstream PIM decomposition schemes, and physically on a prototype chip. Comparing with directly deploying conventionally trained quantized model on PIM systems, which does not take into account this extra quantization step and thus fails, our method provides significant improvement. It also achieves comparable inference accuracy on PIM systems as that of conventionally quantized models on digital hardware, across CIFAR10 and CIFAR100 datasets using various network depths for the most popular network topology.
F8Net: Fixed-Point 8-bit Only Multiplication for Network Quantization
Feb 10, 2022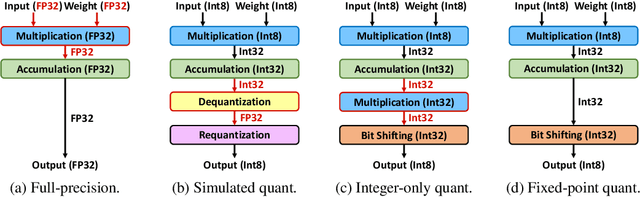
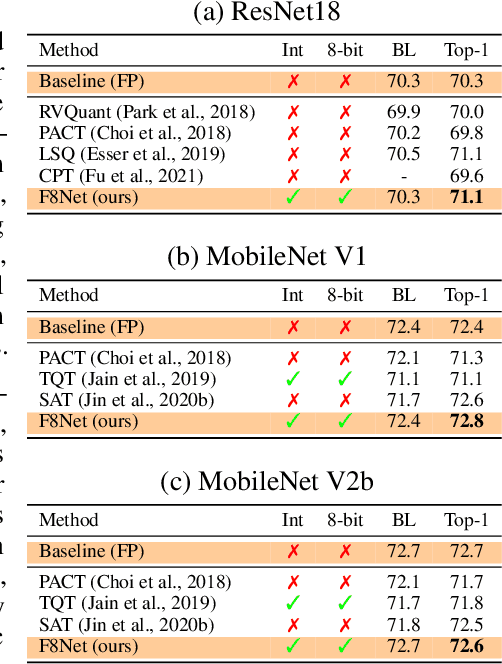
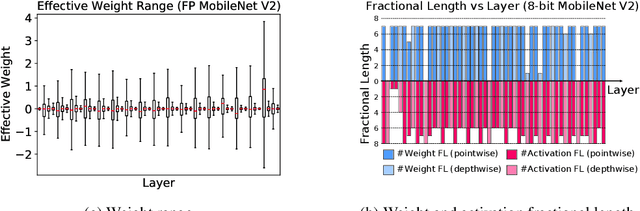
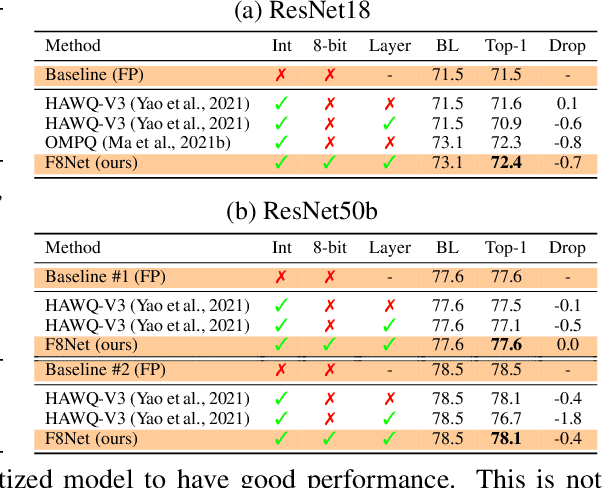
Neural network quantization is a promising compression technique to reduce memory footprint and save energy consumption, potentially leading to real-time inference. However, there is a performance gap between quantized and full-precision models. To reduce it, existing quantization approaches require high-precision INT32 or full-precision multiplication during inference for scaling or dequantization. This introduces a noticeable cost in terms of memory, speed, and required energy. To tackle these issues, we present F8Net, a novel quantization framework consisting of only fixed-point 8-bit multiplication. To derive our method, we first discuss the advantages of fixed-point multiplication with different formats of fixed-point numbers and study the statistical behavior of the associated fixed-point numbers. Second, based on the statistical and algorithmic analysis, we apply different fixed-point formats for weights and activations of different layers. We introduce a novel algorithm to automatically determine the right format for each layer during training. Third, we analyze a previous quantization algorithm -- parameterized clipping activation (PACT) -- and reformulate it using fixed-point arithmetic. Finally, we unify the recently proposed method for quantization fine-tuning and our fixed-point approach to show the potential of our method. We verify F8Net on ImageNet for MobileNet V1/V2 and ResNet18/50. Our approach achieves comparable and better performance, when compared not only to existing quantization techniques with INT32 multiplication or floating-point arithmetic, but also to the full-precision counterparts, achieving state-of-the-art performance.
MEST: Accurate and Fast Memory-Economic Sparse Training Framework on the Edge
Oct 26, 2021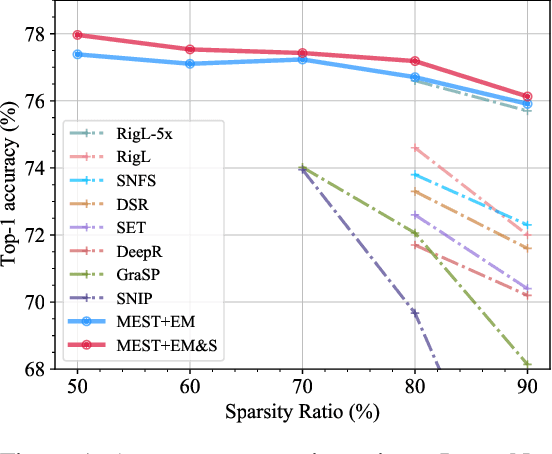
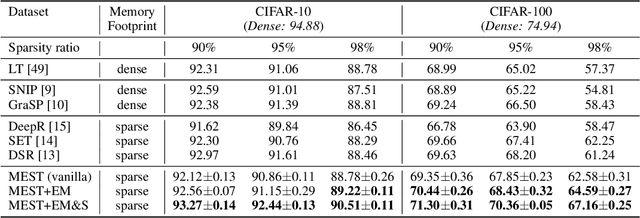
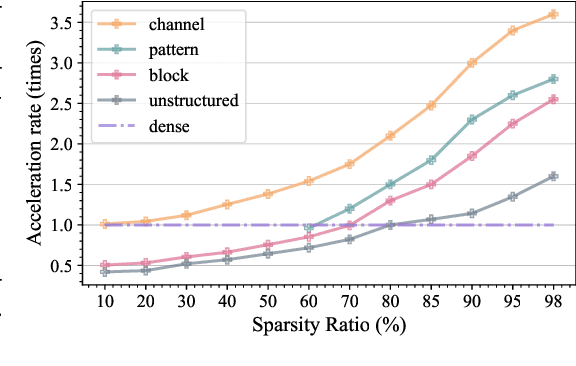
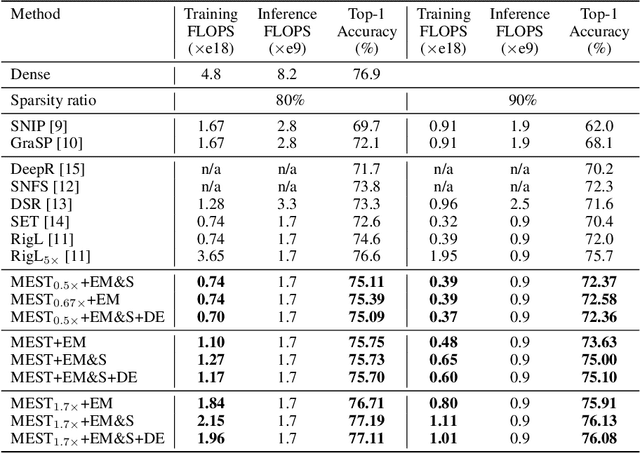
Recently, a new trend of exploring sparsity for accelerating neural network training has emerged, embracing the paradigm of training on the edge. This paper proposes a novel Memory-Economic Sparse Training (MEST) framework targeting for accurate and fast execution on edge devices. The proposed MEST framework consists of enhancements by Elastic Mutation (EM) and Soft Memory Bound (&S) that ensure superior accuracy at high sparsity ratios. Different from the existing works for sparse training, this current work reveals the importance of sparsity schemes on the performance of sparse training in terms of accuracy as well as training speed on real edge devices. On top of that, the paper proposes to employ data efficiency for further acceleration of sparse training. Our results suggest that unforgettable examples can be identified in-situ even during the dynamic exploration of sparsity masks in the sparse training process, and therefore can be removed for further training speedup on edge devices. Comparing with state-of-the-art (SOTA) works on accuracy, our MEST increases Top-1 accuracy significantly on ImageNet when using the same unstructured sparsity scheme. Systematical evaluation on accuracy, training speed, and memory footprint are conducted, where the proposed MEST framework consistently outperforms representative SOTA works. A reviewer strongly against our work based on his false assumptions and misunderstandings. On top of the previous submission, we employ data efficiency for further acceleration of sparse training. And we explore the impact of model sparsity, sparsity schemes, and sparse training algorithms on the number of removable training examples. Our codes are publicly available at: https://github.com/boone891214/MEST.
CAP-RAM: A Charge-Domain In-Memory Computing 6T-SRAM for Accurate and Precision-Programmable CNN Inference
Jul 06, 2021

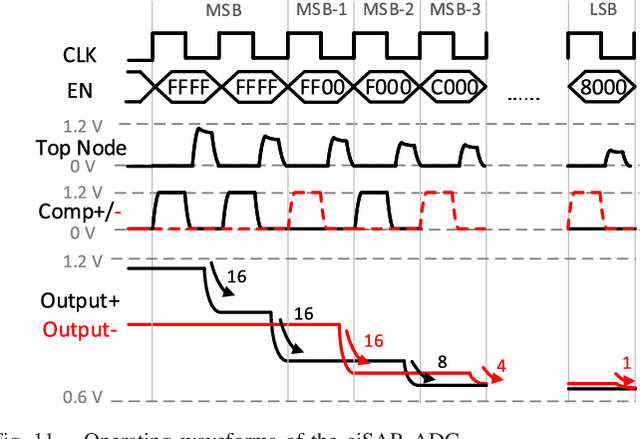
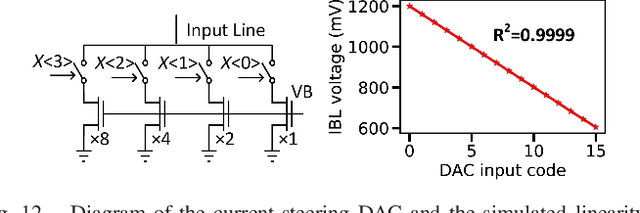
A compact, accurate, and bitwidth-programmable in-memory computing (IMC) static random-access memory (SRAM) macro, named CAP-RAM, is presented for energy-efficient convolutional neural network (CNN) inference. It leverages a novel charge-domain multiply-and-accumulate (MAC) mechanism and circuitry to achieve superior linearity under process variations compared to conventional IMC designs. The adopted semi-parallel architecture efficiently stores filters from multiple CNN layers by sharing eight standard 6T SRAM cells with one charge-domain MAC circuit. Moreover, up to six levels of bit-width of weights with two encoding schemes and eight levels of input activations are supported. A 7-bit charge-injection SAR (ciSAR) analog-to-digital converter (ADC) getting rid of sample and hold (S&H) and input/reference buffers further improves the overall energy efficiency and throughput. A 65-nm prototype validates the excellent linearity and computing accuracy of CAP-RAM. A single 512x128 macro stores a complete pruned and quantized CNN model to achieve 98.8% inference accuracy on the MNIST data set and 89.0% on the CIFAR-10 data set, with a 573.4-giga operations per second (GOPS) peak throughput and a 49.4-tera operations per second (TOPS)/W energy efficiency.
* This work has been accepted by IEEE Journal of Solid-State Circuits (JSSC 2021)
Teachers Do More Than Teach: Compressing Image-to-Image Models
Mar 05, 2021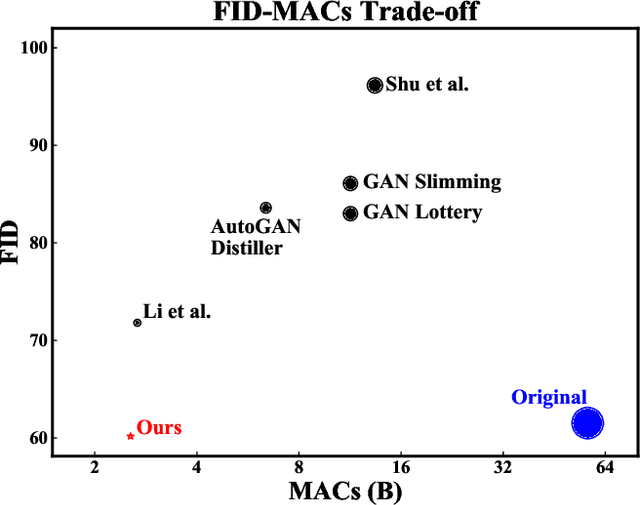
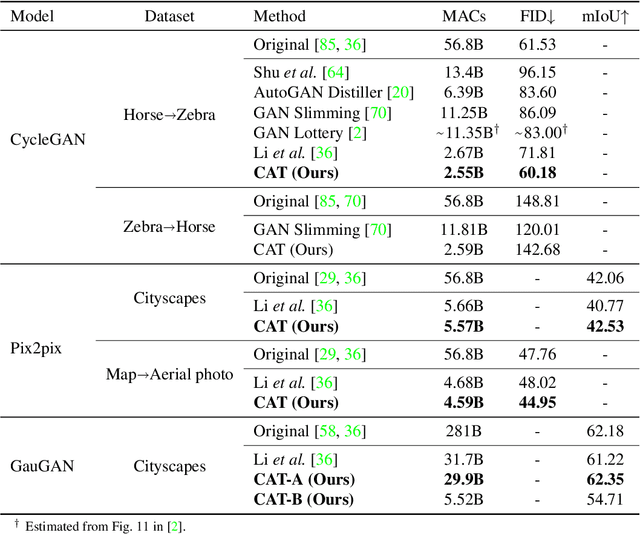
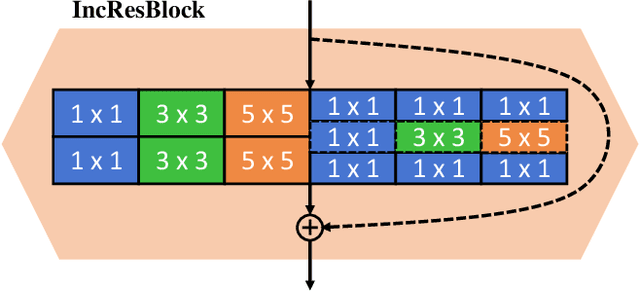
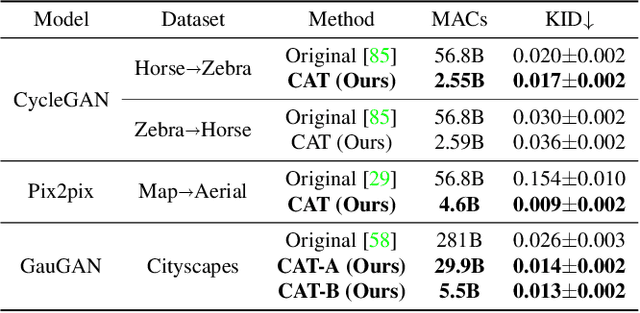
Generative Adversarial Networks (GANs) have achieved huge success in generating high-fidelity images, however, they suffer from low efficiency due to tremendous computational cost and bulky memory usage. Recent efforts on compression GANs show noticeable progress in obtaining smaller generators by sacrificing image quality or involving a time-consuming searching process. In this work, we aim to address these issues by introducing a teacher network that provides a search space in which efficient network architectures can be found, in addition to performing knowledge distillation. First, we revisit the search space of generative models, introducing an inception-based residual block into generators. Second, to achieve target computation cost, we propose a one-step pruning algorithm that searches a student architecture from the teacher model and substantially reduces searching cost. It requires no l1 sparsity regularization and its associated hyper-parameters, simplifying the training procedure. Finally, we propose to distill knowledge through maximizing feature similarity between teacher and student via an index named Global Kernel Alignment (GKA). Our compressed networks achieve similar or even better image fidelity (FID, mIoU) than the original models with much-reduced computational cost, e.g., MACs. Code will be released at https://github.com/snap-research/CAT.
Lottery Ticket Implies Accuracy Degradation, Is It a Desirable Phenomenon?
Feb 19, 2021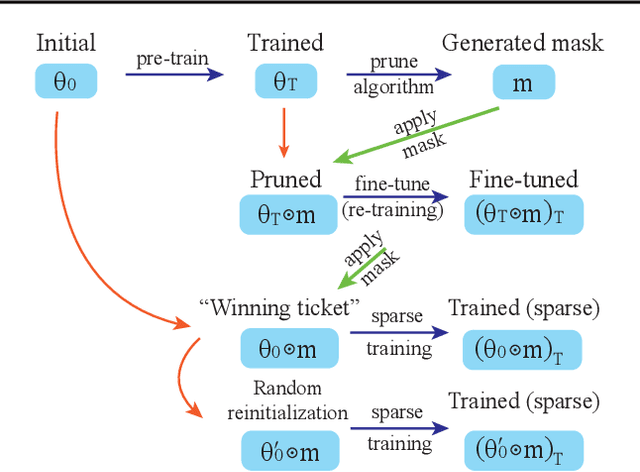
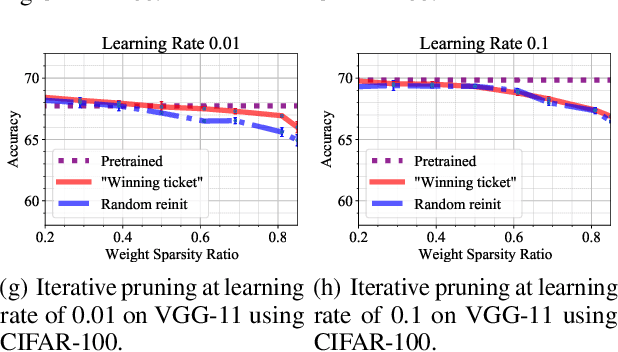
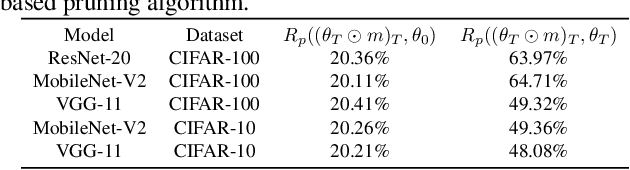
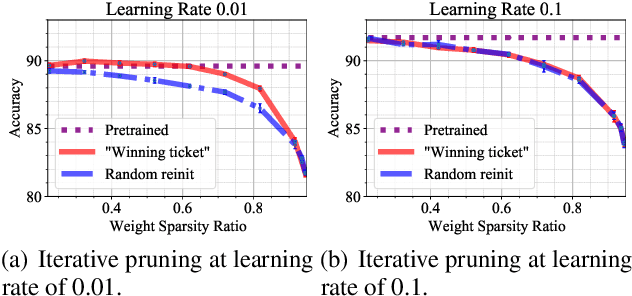
In deep model compression, the recent finding "Lottery Ticket Hypothesis" (LTH) (Frankle & Carbin, 2018) pointed out that there could exist a winning ticket (i.e., a properly pruned sub-network together with original weight initialization) that can achieve competitive performance than the original dense network. However, it is not easy to observe such winning property in many scenarios, where for example, a relatively large learning rate is used even if it benefits training the original dense model. In this work, we investigate the underlying condition and rationale behind the winning property, and find that the underlying reason is largely attributed to the correlation between initialized weights and final-trained weights when the learning rate is not sufficiently large. Thus, the existence of winning property is correlated with an insufficient DNN pretraining, and is unlikely to occur for a well-trained DNN. To overcome this limitation, we propose the "pruning & fine-tuning" method that consistently outperforms lottery ticket sparse training under the same pruning algorithm and the same total training epochs. Extensive experiments over multiple deep models (VGG, ResNet, MobileNet-v2) on different datasets have been conducted to justify our proposals.