 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Should a Robot Think? Resource-Aware Reasoning via Reinforcement Learning for Embodied Robotic Decision-Making
Mar 17, 2026Embodied robotic systems increasingly rely on large language model (LLM)-based agents to support high-level reasoning, planning, and decision-making during interactions with the environment. However, invoking LLM reasoning introduces substantial computational latency and resource overhead, which can interrupt action execution and reduce system reliability. Excessive reasoning may delay actions, while insufficient reasoning often leads to incorrect decisions and task failures. This raises a fundamental question for embodied agents: when should the agent reason, and when should it act? In this work, we propose RARRL (Resource-Aware Reasoning via Reinforcement Learning), a hierarchical framework for resource-aware orchestration of embodied agents. Rather than learning low-level control policies, RARRL learns a high-level orchestration policy that operates at the agent's decision-making layer. This policy enables the agent to adaptively determine whether to invoke reasoning, which reasoning role to employ, and how much computational budget to allocate based on current observations, execution history, and remaining resources. Extensive experiments, including evaluations with empirical latency profiles derived from the ALFRED benchmark, show that RARRL consistently improves task success rates while reducing execution latency and enhancing robustness compared with fixed or heuristic reasoning strategies. These results demonstrate that adaptive reasoning control is essential for building reliable and efficient embodied robotic agents.
RCR-Router: Efficient Role-Aware Context Routing for Multi-Agent LLM Systems with Structured Memory
Aug 06, 2025Multi-agent large language model (LLM) systems have shown strong potential in complex reasoning and collaborative decision-making tasks. However, most existing coordination schemes rely on static or full-context routing strategies, which lead to excessive token consumption, redundant memory exposure, and limited adaptability across interaction rounds. We introduce RCR-Router, a modular and role-aware context routing framework designed to enable efficient, adaptive collaboration in multi-agent LLMs. To our knowledge, this is the first routing approach that dynamically selects semantically relevant memory subsets for each agent based on its role and task stage, while adhering to a strict token budget. A lightweight scoring policy guides memory selection, and agent outputs are iteratively integrated into a shared memory store to facilitate progressive context refinement. To better evaluate model behavior, we further propose an Answer Quality Score metric that captures LLM-generated explanations beyond standard QA accuracy. Experiments on three multi-hop QA benchmarks -- HotPotQA, MuSiQue, and 2WikiMultihop -- demonstrate that RCR-Router reduces token usage (up to 30%) while improving or maintaining answer quality. These results highlight the importance of structured memory routing and output-aware evaluation in advancing scalable multi-agent LLM systems.
Enabling Flexible Multi-LLM Integration for Scalable Knowledge Aggregation
May 28, 2025



Large language models (LLMs) have shown remarkable promise but remain challenging to continually improve through traditional finetuning, particularly when integrating capabilities from other specialized LLMs. Popular methods like ensemble and weight merging require substantial memory and struggle to adapt to changing data environments. Recent efforts have transferred knowledge from multiple LLMs into a single target model; however, they suffer from interference and degraded performance among tasks, largely due to limited flexibility in candidate selection and training pipelines. To address these issues, we propose a framework that adaptively selects and aggregates knowledge from diverse LLMs to build a single, stronger model, avoiding the high memory overhead of ensemble and inflexible weight merging. Specifically, we design an adaptive selection network that identifies the most relevant source LLMs based on their scores, thereby reducing knowledge interference. We further propose a dynamic weighted fusion strategy that accounts for the inherent strengths of candidate LLMs, along with a feedback-driven loss function that prevents the selector from converging on a single subset of sources. Experimental results demonstrate that our method can enable a more stable and scalable knowledge aggregation process while reducing knowledge interference by up to 50% compared to existing approaches. Code is avaliable at https://github.com/ZLKong/LLM_Integration
Structured Agent Distillation for Large Language Model
May 20, 2025
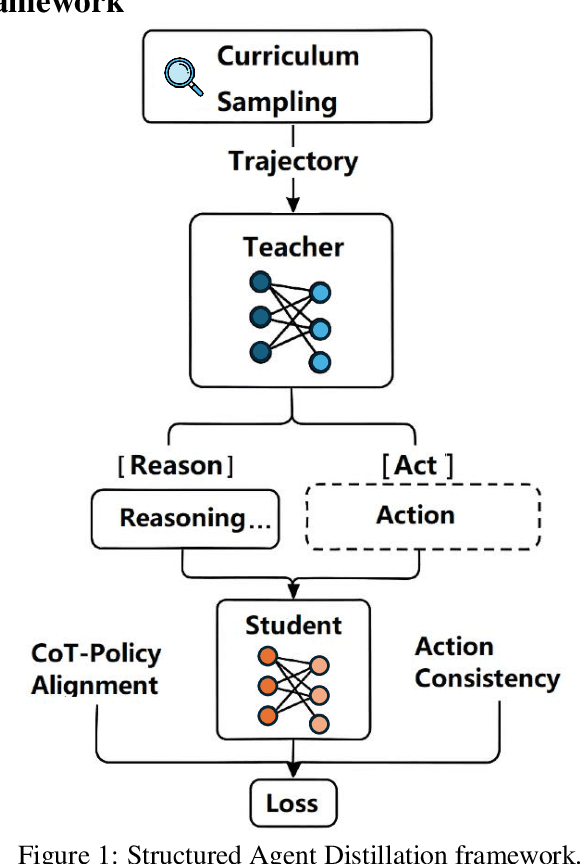

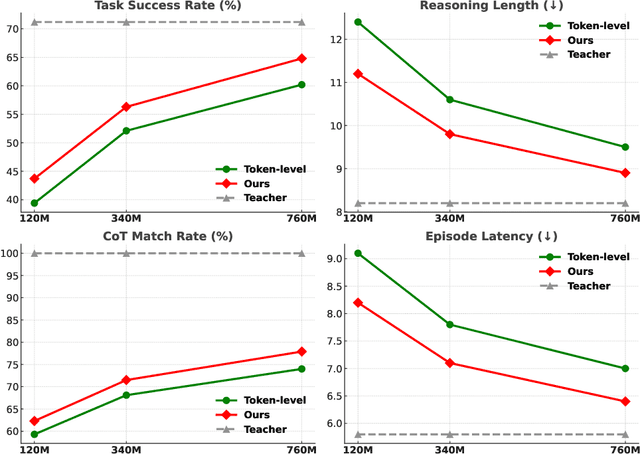
Large language models (LLMs) exhibit strong capabilities as decision-making agents by interleaving reasoning and actions, as seen in ReAct-style frameworks. Yet, their practical deployment is constrained by high inference costs and large model sizes. We propose Structured Agent Distillation, a framework that compresses large LLM-based agents into smaller student models while preserving both reasoning fidelity and action consistency. Unlike standard token-level distillation, our method segments trajectories into {[REASON]} and {[ACT]} spans, applying segment-specific losses to align each component with the teacher's behavior. This structure-aware supervision enables compact agents to better replicate the teacher's decision process. Experiments on ALFWorld, HotPotQA-ReAct, and WebShop show that our approach consistently outperforms token-level and imitation learning baselines, achieving significant compression with minimal performance drop. Scaling and ablation results further highlight the importance of span-level alignment for efficient and deployable agents.
RoRA: Efficient Fine-Tuning of LLM with Reliability Optimization for Rank Adaptation
Jan 08, 2025



Fine-tuning helps large language models (LLM) recover degraded information and enhance task performance.Although Low-Rank Adaptation (LoRA) is widely used and effective for fine-tuning, we have observed that its scaling factor can limit or even reduce performance as the rank size increases. To address this issue, we propose RoRA (Rank-adaptive Reliability Optimization), a simple yet effective method for optimizing LoRA's scaling factor. By replacing $\alpha/r$ with $\alpha/\sqrt{r}$, RoRA ensures improved performance as rank size increases. Moreover, RoRA enhances low-rank adaptation in fine-tuning uncompressed models and excels in the more challenging task of accuracy recovery when fine-tuning pruned models. Extensive experiments demonstrate the effectiveness of RoRA in fine-tuning both uncompressed and pruned models. RoRA surpasses the state-of-the-art (SOTA) in average accuracy and robustness on LLaMA-7B/13B, LLaMA2-7B, and LLaMA3-8B, specifically outperforming LoRA and DoRA by 6.5% and 2.9% on LLaMA-7B, respectively. In pruned model fine-tuning, RoRA shows significant advantages; for SHEARED-LLAMA-1.3, a LLaMA-7B with 81.4% pruning, RoRA achieves 5.7% higher average accuracy than LoRA and 3.9% higher than DoRA.
Quasar-ViT: Hardware-Oriented Quantization-Aware Architecture Search for Vision Transformers
Jul 25, 2024



Vision transformers (ViTs) have demonstrated their superior accuracy for computer vision tasks compared to convolutional neural networks (CNNs). However, ViT models are often computation-intensive for efficient deployment on resource-limited edge devices. This work proposes Quasar-ViT, a hardware-oriented quantization-aware architecture search framework for ViTs, to design efficient ViT models for hardware implementation while preserving the accuracy. First, Quasar-ViT trains a supernet using our row-wise flexible mixed-precision quantization scheme, mixed-precision weight entanglement, and supernet layer scaling techniques. Then, it applies an efficient hardware-oriented search algorithm, integrated with hardware latency and resource modeling, to determine a series of optimal subnets from supernet under different inference latency targets. Finally, we propose a series of model-adaptive designs on the FPGA platform to support the architecture search and mitigate the gap between the theoretical computation reduction and the practical inference speedup. Our searched models achieve 101.5, 159.6, and 251.6 frames-per-second (FPS) inference speed on the AMD/Xilinx ZCU102 FPGA with 80.4%, 78.6%, and 74.9% top-1 accuracy, respectively, for the ImageNet dataset, consistently outperforming prior works.
EdgeQAT: Entropy and Distribution Guided Quantization-Aware Training for the Acceleration of Lightweight LLMs on the Edge
Feb 16, 2024



Despite the remarkable strides of Large Language Models (LLMs) in various fields, the wide applications of LLMs on edge devices are limited due to their massive parameters and computations. To address this, quantization is commonly adopted to generate lightweight LLMs with efficient computations and fast inference. However, Post-Training Quantization (PTQ) methods dramatically degrade in quality when quantizing weights, activations, and KV cache together to below 8 bits. Besides, many Quantization-Aware Training (QAT) works quantize model weights, leaving the activations untouched, which do not fully exploit the potential of quantization for inference acceleration on the edge. In this paper, we propose EdgeQAT, the Entropy and Distribution Guided QAT for the optimization of lightweight LLMs to achieve inference acceleration on Edge devices. We first identify that the performance drop of quantization primarily stems from the information distortion in quantized attention maps, demonstrated by the different distributions in quantized query and key of the self-attention mechanism. Then, the entropy and distribution guided QAT is proposed to mitigate the information distortion. Moreover, we design a token importance-aware adaptive method to dynamically quantize the tokens with different bit widths for further optimization and acceleration. Our extensive experiments verify the substantial improvements with our framework across various datasets. Furthermore, we achieve an on-device speedup of up to 2.37x compared with its FP16 counterparts across multiple edge devices, signaling a groundbreaking advancement.
Agile-Quant: Activation-Guided Quantization for Faster Inference of LLMs on the Edge
Dec 09, 2023



Large Language Models (LLMs) stand out for their impressive performance in intricate language modeling tasks. However, their demanding computational and memory needs pose obstacles for broad use on edge devices. Quantization is then introduced to boost LLMs' on-device efficiency. Recent works show that 8-bit or lower weight quantization is feasible with minimal impact on end-to-end task performance, while the activation is still not quantized. On the other hand, mainstream commodity edge devices still struggle to execute these sub-8-bit quantized networks effectively. In this paper, we propose Agile-Quant, an activation-guided quantization framework for popular Large Language Models (LLMs), and implement an end-to-end accelerator on multiple edge devices for faster inference. Considering the hardware profiling and activation analysis, we first introduce a basic activation quantization strategy to balance the trade-off of task performance and real inference speed. Then we leverage the activation-aware token pruning technique to reduce the outliers and the adverse impact on attentivity. Ultimately, we utilize the SIMD-based 4-bit multiplier and our efficient TRIP matrix multiplication to implement the accelerator for LLMs on the edge. We apply our framework on different scales of LLMs including LLaMA, OPT, and BLOOM with 4-bit or 8-bit for the activation and 4-bit for the weight quantization. Experiments show that Agile-Quant achieves simultaneous quantization of model weights and activations while maintaining task performance comparable to existing weight-only quantization methods. Moreover, in the 8- and 4-bit scenario, Agile-Quant achieves an on-device speedup of up to 2.55x compared to its FP16 counterparts across multiple edge devices, marking a pioneering advancement in this domain.
SupeRBNN: Randomized Binary Neural Network Using Adiabatic Superconductor Josephson Devices
Sep 21, 2023



Adiabatic Quantum-Flux-Parametron (AQFP) is a superconducting logic with extremely high energy efficiency. By employing the distinct polarity of current to denote logic `0' and `1', AQFP devices serve as excellent carriers for binary neural network (BNN) computations. Although recent research has made initial strides toward developing an AQFP-based BNN accelerator, several critical challenges remain, preventing the design from being a comprehensive solution. In this paper, we propose SupeRBNN, an AQFP-based randomized BNN acceleration framework that leverages software-hardware co-optimization to eventually make the AQFP devices a feasible solution for BNN acceleration. Specifically, we investigate the randomized behavior of the AQFP devices and analyze the impact of crossbar size on current attenuation, subsequently formulating the current amplitude into the values suitable for use in BNN computation. To tackle the accumulation problem and improve overall hardware performance, we propose a stochastic computing-based accumulation module and a clocking scheme adjustment-based circuit optimization method. We validate our SupeRBNN framework across various datasets and network architectures, comparing it with implementations based on different technologies, including CMOS, ReRAM, and superconducting RSFQ/ERSFQ. Experimental results demonstrate that our design achieves an energy efficiency of approximately 7.8x10^4 times higher than that of the ReRAM-based BNN framework while maintaining a similar level of model accuracy. Furthermore, when compared with superconductor-based counterparts, our framework demonstrates at least two orders of magnitude higher energy efficiency.
Peeling the Onion: Hierarchical Reduction of Data Redundancy for Efficient Vision Transformer Training
Nov 19, 2022



Vision transformers (ViTs) have recently obtained success in many applications, but their intensive computation and heavy memory usage at both training and inference time limit their generalization. Previous compression algorithms usually start from the pre-trained dense models and only focus on efficient inference, while time-consuming training is still unavoidable. In contrast, this paper points out that the million-scale training data is redundant, which is the fundamental reason for the tedious training. To address the issue, this paper aims to introduce sparsity into data and proposes an end-to-end efficient training framework from three sparse perspectives, dubbed Tri-Level E-ViT. Specifically, we leverage a hierarchical data redundancy reduction scheme, by exploring the sparsity under three levels: number of training examples in the dataset, number of patches (tokens) in each example, and number of connections between tokens that lie in attention weights. With extensive experiments, we demonstrate that our proposed technique can noticeably accelerate training for various ViT architectures while maintaining accuracy. Remarkably, under certain ratios, we are able to improve the ViT accuracy rather than compromising it. For example, we can achieve 15.2% speedup with 72.6% (+0.4) Top-1 accuracy on Deit-T, and 15.7% speedup with 79.9% (+0.1) Top-1 accuracy on Deit-S. This proves the existence of data redundancy in ViT.