 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApply Hierarchical-Chain-of-Generation to Complex Attributes Text-to-3D Generation
May 07, 2025Recent text-to-3D models can render high-quality assets, yet they still stumble on objects with complex attributes. The key obstacles are: (1) existing text-to-3D approaches typically lift text-to-image models to extract semantics via text encoders, while the text encoder exhibits limited comprehension ability for long descriptions, leading to deviated cross-attention focus, subsequently wrong attribute binding in generated results. (2) Occluded object parts demand a disciplined generation order and explicit part disentanglement. Though some works introduce manual efforts to alleviate the above issues, their quality is unstable and highly reliant on manual information. To tackle above problems, we propose a automated method Hierarchical-Chain-of-Generation (HCoG). It leverages a large language model to decompose the long description into blocks representing different object parts, and orders them from inside out according to occlusions, forming a hierarchical chain. Within each block we first coarsely create components, then precisely bind attributes via target-region localization and corresponding 3D Gaussian kernel optimization. Between blocks, we introduce Gaussian Extension and Label Elimination to seamlessly generate new parts by extending new Gaussian kernels, re-assigning semantic labels, and eliminating unnecessary kernels, ensuring that only relevant parts are added without disrupting previously optimized parts. Experiments confirm that HCoG yields structurally coherent, attribute-faithful 3D objects with complex attributes. The code is available at https://github.com/Wakals/GASCOL .
OpenHelix: A Short Survey, Empirical Analysis, and Open-Source Dual-System VLA Model for Robotic Manipulation
May 06, 2025



Dual-system VLA (Vision-Language-Action) architectures have become a hot topic in embodied intelligence research, but there is a lack of sufficient open-source work for further performance analysis and optimization. To address this problem, this paper will summarize and compare the structural designs of existing dual-system architectures, and conduct systematic empirical evaluations on the core design elements of existing dual-system architectures. Ultimately, it will provide a low-cost open-source model for further exploration. Of course, this project will continue to update with more experimental conclusions and open-source models with improved performance for everyone to choose from. Project page: https://openhelix-robot.github.io/.
3DWG: 3D Weakly Supervised Visual Grounding via Category and Instance-Level Alignment
May 03, 2025The 3D weakly-supervised visual grounding task aims to localize oriented 3D boxes in point clouds based on natural language descriptions without requiring annotations to guide model learning. This setting presents two primary challenges: category-level ambiguity and instance-level complexity. Category-level ambiguity arises from representing objects of fine-grained categories in a highly sparse point cloud format, making category distinction challenging. Instance-level complexity stems from multiple instances of the same category coexisting in a scene, leading to distractions during grounding. To address these challenges, we propose a novel weakly-supervised grounding approach that explicitly differentiates between categories and instances. In the category-level branch, we utilize extensive category knowledge from a pre-trained external detector to align object proposal features with sentence-level category features, thereby enhancing category awareness. In the instance-level branch, we utilize spatial relationship descriptions from language queries to refine object proposal features, ensuring clear differentiation among objects. These designs enable our model to accurately identify target-category objects while distinguishing instances within the same category. Compared to previous methods, our approach achieves state-of-the-art performance on three widely used benchmarks: Nr3D, Sr3D, and ScanRef.
PeSANet: Physics-encoded Spectral Attention Network for Simulating PDE-Governed Complex Systems
May 03, 2025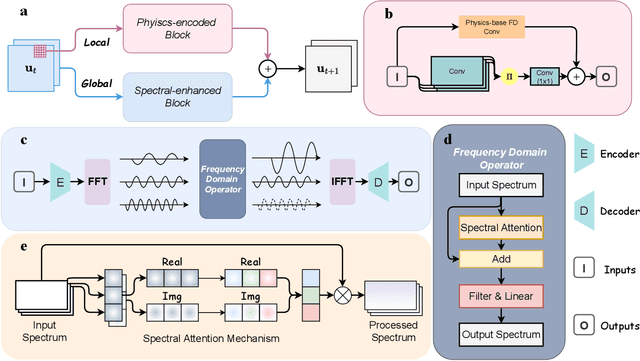

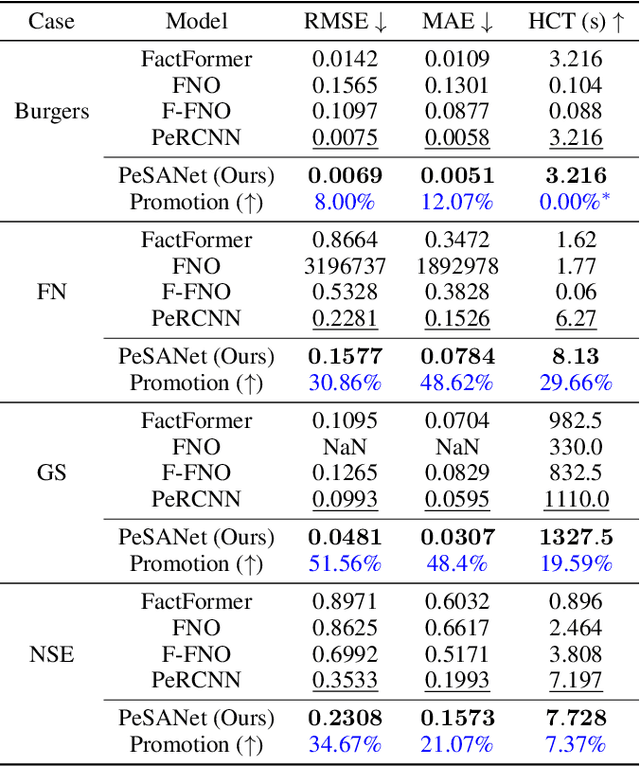
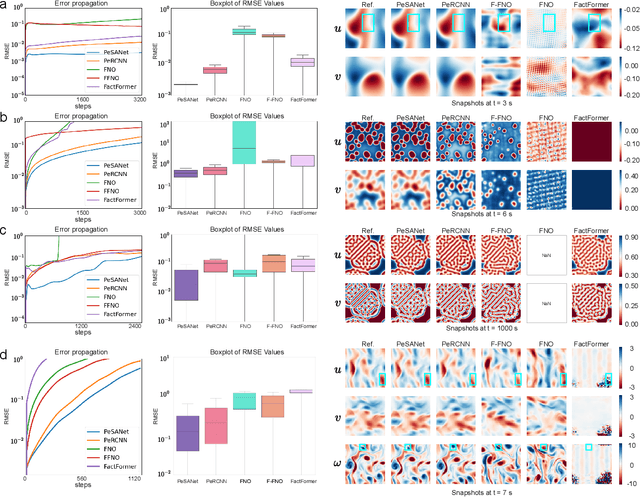
Accurately modeling and forecasting complex systems governed by partial differential equations (PDEs) is crucial in various scientific and engineering domains. However, traditional numerical methods struggle in real-world scenarios due to incomplete or unknown physical laws. Meanwhile, machine learning approaches often fail to generalize effectively when faced with scarce observational data and the challenge of capturing local and global features. To this end, we propose the Physics-encoded Spectral Attention Network (PeSANet), which integrates local and global information to forecast complex systems with limited data and incomplete physical priors. The model consists of two key components: a physics-encoded block that uses hard constraints to approximate local differential operators from limited data, and a spectral-enhanced block that captures long-range global dependencies in the frequency domain. Specifically, we introduce a novel spectral attention mechanism to model inter-spectrum relationships and learn long-range spatial features. Experimental results demonstrate that PeSANet outperforms existing methods across all metrics, particularly in long-term forecasting accuracy, providing a promising solution for simulating complex systems with limited data and incomplete physics.
Edge-Cloud Collaborative Computing on Distributed Intelligence and Model Optimization: A Survey
May 03, 2025



Edge-cloud collaborative computing (ECCC) has emerged as a pivotal paradigm for addressing the computational demands of modern intelligent applications, integrating cloud resources with edge devices to enable efficient, low-latency processing. Recent advancements in AI, particularly deep learning and large language models (LLMs), have dramatically enhanced the capabilities of these distributed systems, yet introduce significant challenges in model deployment and resource management. In this survey, we comprehensive examine the intersection of distributed intelligence and model optimization within edge-cloud environments, providing a structured tutorial on fundamental architectures, enabling technologies, and emerging applications. Additionally, we systematically analyze model optimization approaches, including compression, adaptation, and neural architecture search, alongside AI-driven resource management strategies that balance performance, energy efficiency, and latency requirements. We further explore critical aspects of privacy protection and security enhancement within ECCC systems and examines practical deployments through diverse applications, spanning autonomous driving, healthcare, and industrial automation. Performance analysis and benchmarking techniques are also thoroughly explored to establish evaluation standards for these complex systems. Furthermore, the review identifies critical research directions including LLMs deployment, 6G integration, neuromorphic computing, and quantum computing, offering a roadmap for addressing persistent challenges in heterogeneity management, real-time processing, and scalability. By bridging theoretical advancements and practical deployments, this survey offers researchers and practitioners a holistic perspective on leveraging AI to optimize distributed computing environments, fostering innovation in next-generation intelligent systems.
Machine Learning for Physical Simulation Challenge Results and Retrospective Analysis: Power Grid Use Case
May 02, 2025



This paper addresses the growing computational challenges of power grid simulations, particularly with the increasing integration of renewable energy sources like wind and solar. As grid operators must analyze significantly more scenarios in near real-time to prevent failures and ensure stability, traditional physical-based simulations become computationally impractical. To tackle this, a competition was organized to develop AI-driven methods that accelerate power flow simulations by at least an order of magnitude while maintaining operational reliability. This competition utilized a regional-scale grid model with a 30\% renewable energy mix, mirroring the anticipated near-future composition of the French power grid. A key contribution of this work is through the use of LIPS (Learning Industrial Physical Systems), a benchmarking framework that evaluates solutions based on four critical dimensions: machine learning performance, physical compliance, industrial readiness, and generalization to out-of-distribution scenarios. The paper provides a comprehensive overview of the Machine Learning for Physical Simulation (ML4PhySim) competition, detailing the benchmark suite, analyzing top-performing solutions that outperformed traditional simulation methods, and sharing key organizational insights and best practices for running large-scale AI competitions. Given the promising results achieved, the study aims to inspire further research into more efficient, scalable, and sustainable power network simulation methodologies.
A Vision for Auto Research with LLM Agents
Apr 26, 2025This paper introduces Agent-Based Auto Research, a structured multi-agent framework designed to automate, coordinate, and optimize the full lifecycle of scientific research. Leveraging the capabilities of large language models (LLMs) and modular agent collaboration, the system spans all major research phases, including literature review, ideation, methodology planning, experimentation, paper writing, peer review response, and dissemination. By addressing issues such as fragmented workflows, uneven methodological expertise, and cognitive overload, the framework offers a systematic and scalable approach to scientific inquiry. Preliminary explorations demonstrate the feasibility and potential of Auto Research as a promising paradigm for self-improving, AI-driven research processes.
Ustnlp16 at SemEval-2025 Task 9: Improving Model Performance through Imbalance Handling and Focal Loss
Apr 24, 2025



Classification tasks often suffer from imbal- anced data distribution, which presents chal- lenges in food hazard detection due to severe class imbalances, short and unstructured text, and overlapping semantic categories. In this paper, we present our system for SemEval- 2025 Task 9: Food Hazard Detection, which ad- dresses these issues by applying data augmenta- tion techniques to improve classification perfor- mance. We utilize transformer-based models, BERT and RoBERTa, as backbone classifiers and explore various data balancing strategies, including random oversampling, Easy Data Augmentation (EDA), and focal loss. Our ex- periments show that EDA effectively mitigates class imbalance, leading to significant improve- ments in accuracy and F1 scores. Furthermore, combining focal loss with oversampling and EDA further enhances model robustness, par- ticularly for hard-to-classify examples. These findings contribute to the development of more effective NLP-based classification models for food hazard detection.
Towards Harnessing the Collaborative Power of Large and Small Models for Domain Tasks
Apr 24, 2025Large language models (LLMs) have demonstrated remarkable capabilities, but they require vast amounts of data and computational resources. In contrast, smaller models (SMs), while less powerful, can be more efficient and tailored to specific domains. In this position paper, we argue that taking a collaborative approach, where large and small models work synergistically, can accelerate the adaptation of LLMs to private domains and unlock new potential in AI. We explore various strategies for model collaboration and identify potential challenges and opportunities. Building upon this, we advocate for industry-driven research that prioritizes multi-objective benchmarks on real-world private datasets and applications.
Skywork R1V2: Multimodal Hybrid Reinforcement Learning for Reasoning
Apr 23, 2025We present Skywork R1V2, a next-generation multimodal reasoning model and a major leap forward from its predecessor, Skywork R1V. At its core, R1V2 introduces a hybrid reinforcement learning paradigm that harmonizes reward-model guidance with rule-based strategies, thereby addressing the long-standing challenge of balancing sophisticated reasoning capabilities with broad generalization. To further enhance training efficiency, we propose the Selective Sample Buffer (SSB) mechanism, which effectively counters the ``Vanishing Advantages'' dilemma inherent in Group Relative Policy Optimization (GRPO) by prioritizing high-value samples throughout the optimization process. Notably, we observe that excessive reinforcement signals can induce visual hallucinations--a phenomenon we systematically monitor and mitigate through calibrated reward thresholds throughout the training process. Empirical results affirm the exceptional capability of R1V2, with benchmark-leading performances such as 62.6 on OlympiadBench, 79.0 on AIME2024, 63.6 on LiveCodeBench, and 74.0 on MMMU. These results underscore R1V2's superiority over existing open-source models and demonstrate significant progress in closing the performance gap with premier proprietary systems, including Gemini 2.5 and OpenAI o4-mini. The Skywork R1V2 model weights have been publicly released to promote openness and reproducibility https://huggingface.co/Skywork/Skywork-R1V2-38B.