 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Multimodal Contextualized Plan Prediction for Embodied Task Completion
May 10, 2023Task planning is an important component of traditional robotics systems enabling robots to compose fine grained skills to perform more complex tasks. Recent work building systems for translating natural language to executable actions for task completion in simulated embodied agents is focused on directly predicting low level action sequences that would be expected to be directly executable by a physical robot. In this work, we instead focus on predicting a higher level plan representation for one such embodied task completion dataset - TEACh, under the assumption that techniques for high-level plan prediction from natural language are expected to be more transferable to physical robot systems. We demonstrate that better plans can be predicted using multimodal context, and that plan prediction and plan execution modules are likely dependent on each other and hence it may not be ideal to fully decouple them. Further, we benchmark execution of oracle plans to quantify the scope for improvement in plan prediction models.
DialGuide: Aligning Dialogue Model Behavior with Developer Guidelines
Dec 20, 2022



Dialogue models are able to generate coherent and fluent responses, but they can still be challenging to control and may produce non-engaging, unsafe results. This unpredictability diminishes user trust and can hinder the use of the models in the real world. To address this, we introduce DialGuide, a novel framework for controlling dialogue model behavior using natural language rules, or guidelines. These guidelines provide information about the context they are applicable to and what should be included in the response, allowing the models to generate responses that are more closely aligned with the developer's expectations and intent. We evaluate DialGuide on three tasks in open-domain dialogue response generation: guideline selection, response generation, and response entailment verification. Our dataset contains 10,737 positive and 15,467 negative dialogue context-response-guideline triplets across two domains - chit-chat and safety. We provide baseline models for the tasks and benchmark their performance. We also demonstrate that DialGuide is effective in the dialogue safety domain, producing safe and engaging responses that follow developer guidelines.
Dialog Acts for Task-Driven Embodied Agents
Sep 26, 2022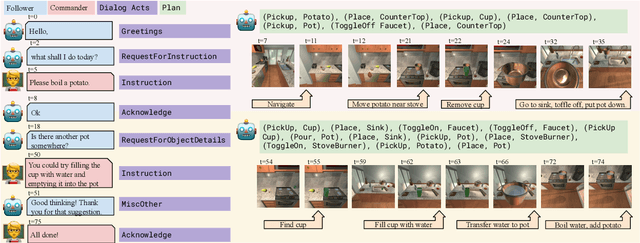
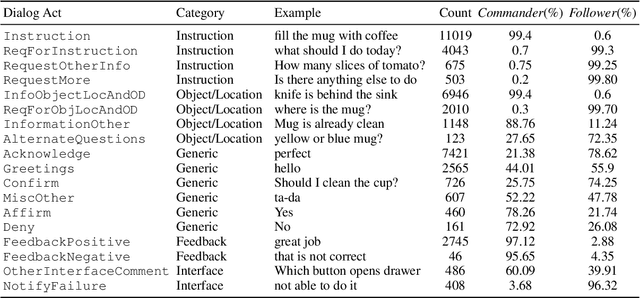

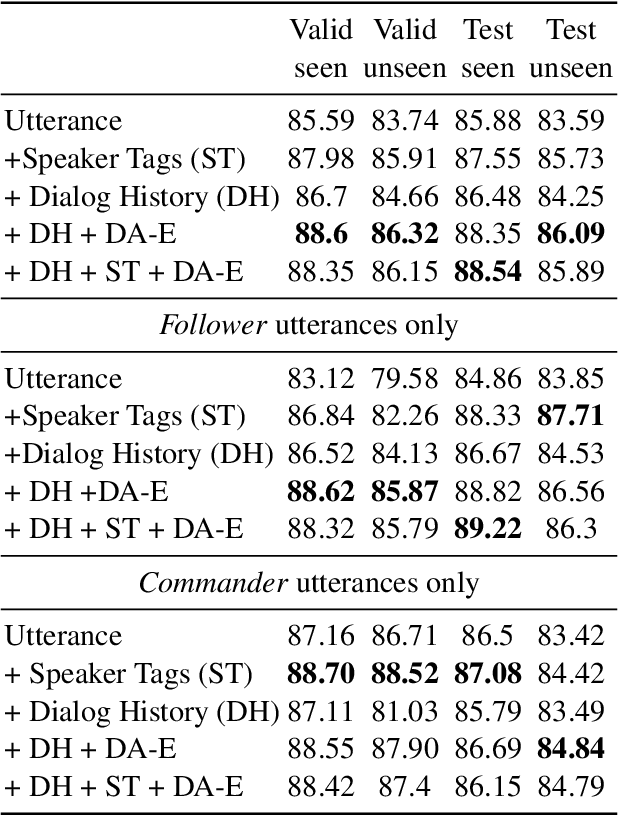
Embodied agents need to be able to interact in natural language understanding task descriptions and asking appropriate follow up questions to obtain necessary information to be effective at successfully accomplishing tasks for a wide range of users. In this work, we propose a set of dialog acts for modelling such dialogs and annotate the TEACh dataset that includes over 3,000 situated, task oriented conversations (consisting of 39.5k utterances in total) with dialog acts. TEACh-DA is one of the first large scale dataset of dialog act annotations for embodied task completion. Furthermore, we demonstrate the use of this annotated dataset in training models for tagging the dialog acts of a given utterance, predicting the dialog act of the next response given a dialog history, and use the dialog acts to guide agent's non-dialog behaviour. In particular, our experiments on the TEACh Execution from Dialog History task where the model predicts the sequence of low level actions to be executed in the environment for embodied task completion, demonstrate that dialog acts can improve end task success rate by up to 2 points compared to the system without dialog acts.
TEACh: Task-driven Embodied Agents that Chat
Oct 15, 2021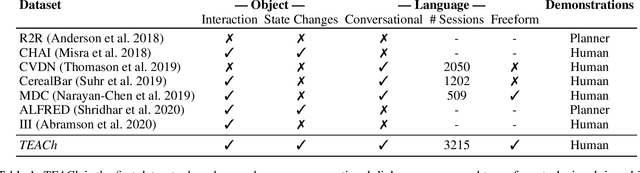
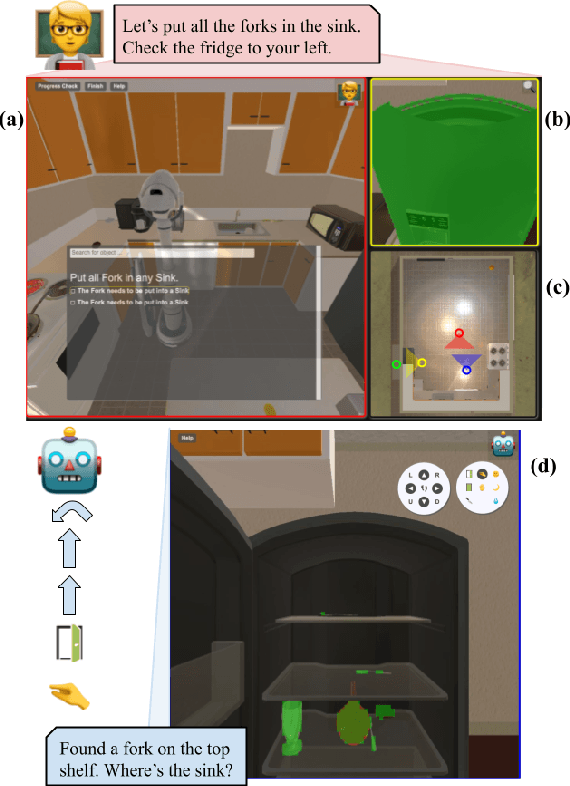
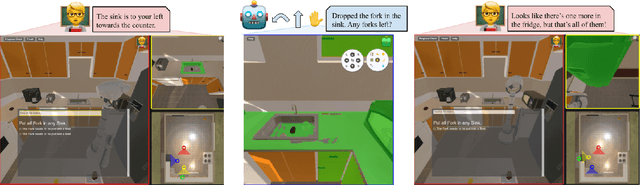
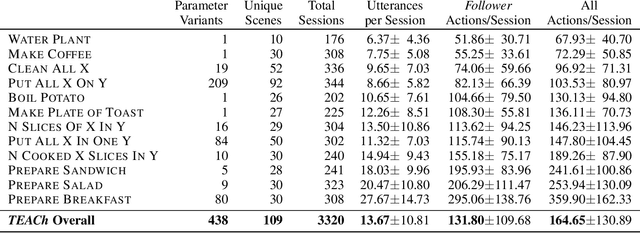
Robots operating in human spaces must be able to engage in natural language interaction with people, both understanding and executing instructions, and using conversation to resolve ambiguity and recover from mistakes. To study this, we introduce TEACh, a dataset of over 3,000 human--human, interactive dialogues to complete household tasks in simulation. A Commander with access to oracle information about a task communicates in natural language with a Follower. The Follower navigates through and interacts with the environment to complete tasks varying in complexity from "Make Coffee" to "Prepare Breakfast", asking questions and getting additional information from the Commander. We propose three benchmarks using TEACh to study embodied intelligence challenges, and we evaluate initial models' abilities in dialogue understanding, language grounding, and task execution.
Evaluation of In-Person Counseling Strategies To Develop Physical Activity Chatbot for Women
Jul 22, 2021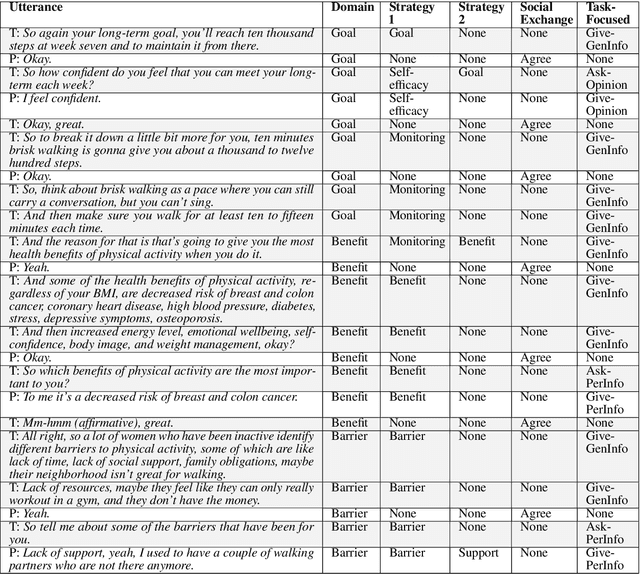
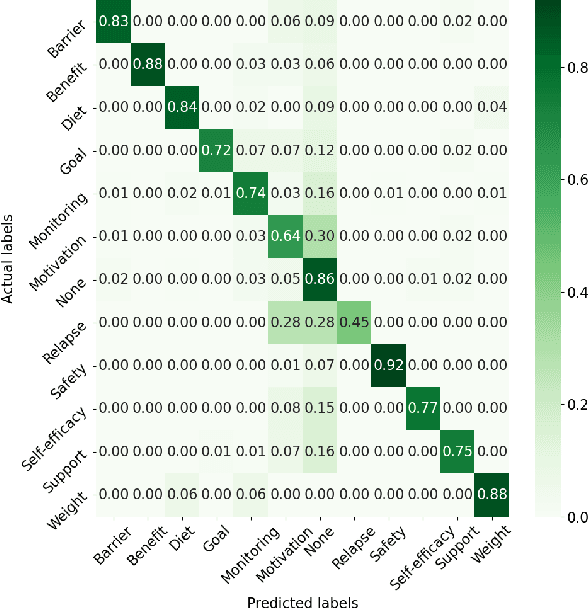

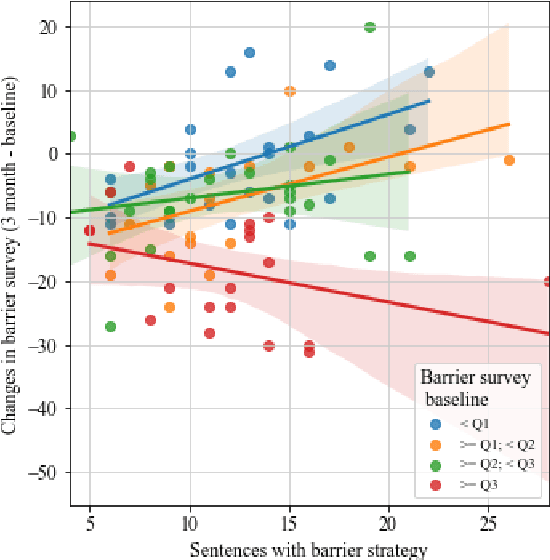
Artificial intelligence chatbots are the vanguard in technology-based intervention to change people's behavior. To develop intervention chatbots, the first step is to understand natural language conversation strategies in human conversation. This work introduces an intervention conversation dataset collected from a real-world physical activity intervention program for women. We designed comprehensive annotation schemes in four dimensions (domain, strategy, social exchange, and task-focused exchange) and annotated a subset of dialogs. We built a strategy classifier with context information to detect strategies from both trainers and participants based on the annotation. To understand how human intervention induces effective behavior changes, we analyzed the relationships between the intervention strategies and the participants' changes in the barrier and social support for physical activity. We also analyzed how participant's baseline weight correlates to the amount of occurrence of the corresponding strategy. This work lays the foundation for developing a personalized physical activity intervention bot. The dataset and code are available at https://github.com/KaihuiLiang/physical-activity-counseling