 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGROUNDHOG: Grounding Large Language Models to Holistic Segmentation
Feb 26, 2024



Most multimodal large language models (MLLMs) learn language-to-object grounding through causal language modeling where grounded objects are captured by bounding boxes as sequences of location tokens. This paradigm lacks pixel-level representations that are important for fine-grained visual understanding and diagnosis. In this work, we introduce GROUNDHOG, an MLLM developed by grounding Large Language Models to holistic segmentation. GROUNDHOG incorporates a masked feature extractor and converts extracted features into visual entity tokens for the MLLM backbone, which then connects groundable phrases to unified grounding masks by retrieving and merging the entity masks. To train GROUNDHOG, we carefully curated M3G2, a grounded visual instruction tuning dataset with Multi-Modal Multi-Grained Grounding, by harvesting a collection of segmentation-grounded datasets with rich annotations. Our experimental results show that GROUNDHOG achieves superior performance on various language grounding tasks without task-specific fine-tuning, and significantly reduces object hallucination. GROUNDHOG also demonstrates better grounding towards complex forms of visual input and provides easy-to-understand diagnosis in failure cases.
Mastering Robot Manipulation with Multimodal Prompts through Pretraining and Multi-task Fine-tuning
Oct 14, 2023



Prompt-based learning has been demonstrated as a compelling paradigm contributing to large language models' tremendous success (LLMs). Inspired by their success in language tasks, existing research has leveraged LLMs in embodied instruction following and task planning. However, not much attention has been paid to embodied tasks with multimodal prompts, combining vision signals with text descriptions. This type of task poses a major challenge to robots' capability to understand the interconnection and complementarity between vision and language signals. In this work, we introduce an effective framework that learns a policy to perform robot manipulation with multimodal prompts from multi-task expert trajectories. Our methods consist of a two-stage training pipeline that performs inverse dynamics pretraining and multi-task finetuning. To facilitate multimodal understanding, we design our multimodal prompt encoder by augmenting a pretrained LM with a residual connection to the visual input and model the dependencies among action dimensions. Empirically, we evaluate the efficacy of our method on the VIMA-BENCH and establish a new state-of-the-art (10% improvement in success rate). Moreover, we demonstrate that our model exhibits remarkable in-context learning ability.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
Exploiting Generalization in Offline Reinforcement Learning via Unseen State Augmentations
Aug 07, 2023



Offline reinforcement learning (RL) methods strike a balance between exploration and exploitation by conservative value estimation -- penalizing values of unseen states and actions. Model-free methods penalize values at all unseen actions, while model-based methods are able to further exploit unseen states via model rollouts. However, such methods are handicapped in their ability to find unseen states far away from the available offline data due to two factors -- (a) very short rollout horizons in models due to cascading model errors, and (b) model rollouts originating solely from states observed in offline data. We relax the second assumption and present a novel unseen state augmentation strategy to allow exploitation of unseen states where the learned model and value estimates generalize. Our strategy finds unseen states by value-informed perturbations of seen states followed by filtering out states with epistemic uncertainty estimates too high (high error) or too low (too similar to seen data). We observe improved performance in several offline RL tasks and find that our augmentation strategy consistently leads to overall lower average dataset Q-value estimates i.e. more conservative Q-value estimates than a baseline.
LEMMA: Learning Language-Conditioned Multi-Robot Manipulation
Aug 02, 2023



Complex manipulation tasks often require robots with complementary capabilities to collaborate. We introduce a benchmark for LanguagE-Conditioned Multi-robot MAnipulation (LEMMA) focused on task allocation and long-horizon object manipulation based on human language instructions in a tabletop setting. LEMMA features 8 types of procedurally generated tasks with varying degree of complexity, some of which require the robots to use tools and pass tools to each other. For each task, we provide 800 expert demonstrations and human instructions for training and evaluations. LEMMA poses greater challenges compared to existing benchmarks, as it requires the system to identify each manipulator's limitations and assign sub-tasks accordingly while also handling strong temporal dependencies in each task. To address these challenges, we propose a modular hierarchical planning approach as a baseline. Our results highlight the potential of LEMMA for developing future language-conditioned multi-robot systems.
Alexa Arena: A User-Centric Interactive Platform for Embodied AI
Mar 02, 2023



We introduce Alexa Arena, a user-centric simulation platform for Embodied AI (EAI) research. Alexa Arena provides a variety of multi-room layouts and interactable objects, for the creation of human-robot interaction (HRI) missions. With user-friendly graphics and control mechanisms, Alexa Arena supports the development of gamified robotic tasks readily accessible to general human users, thus opening a new venue for high-efficiency HRI data collection and EAI system evaluation. Along with the platform, we introduce a dialog-enabled instruction-following benchmark and provide baseline results for it. We make Alexa Arena publicly available to facilitate research in building generalizable and assistive embodied agents.
Language-Informed Transfer Learning for Embodied Household Activities
Jan 12, 2023



For service robots to become general-purpose in everyday household environments, they need not only a large library of primitive skills, but also the ability to quickly learn novel tasks specified by users. Fine-tuning neural networks on a variety of downstream tasks has been successful in many vision and language domains, but research is still limited on transfer learning between diverse long-horizon tasks. We propose that, compared to reinforcement learning for a new household activity from scratch, home robots can benefit from transferring the value and policy networks trained for similar tasks. We evaluate this idea in the BEHAVIOR simulation benchmark which includes a large number of household activities and a set of action primitives. For easy mapping between state spaces of different tasks, we provide a text-based representation and leverage language models to produce a common embedding space. The results show that the selection of similar source activities can be informed by the semantic similarity of state and goal descriptions with the target task. We further analyze the results and discuss ways to overcome the problem of catastrophic forgetting.
OpenD: A Benchmark for Language-Driven Door and Drawer Opening
Dec 10, 2022



We introduce OPEND, a benchmark for learning how to use a hand to open cabinet doors or drawers in a photo-realistic and physics-reliable simulation environment driven by language instruction. To solve the task, we propose a multi-step planner composed of a deep neural network and rule-base controllers. The network is utilized to capture spatial relationships from images and understand semantic meaning from language instructions. Controllers efficiently execute the plan based on the spatial and semantic understanding. We evaluate our system by measuring its zero-shot performance in test data set. Experimental results demonstrate the effectiveness of decision planning by our multi-step planner for different hands, while suggesting that there is significant room for developing better models to address the challenge brought by language understanding, spatial reasoning, and long-term manipulation. We will release OPEND and host challenges to promote future research in this area.
CH-MARL: A Multimodal Benchmark for Cooperative, Heterogeneous Multi-Agent Reinforcement Learning
Aug 26, 2022
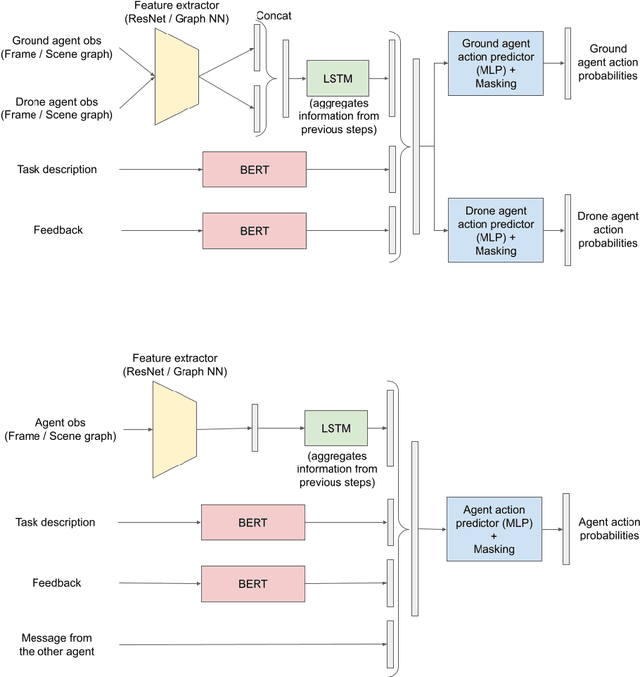


We propose a multimodal (vision-and-language) benchmark for cooperative and heterogeneous multi-agent learning. We introduce a benchmark multimodal dataset with tasks involving collaboration between multiple simulated heterogeneous robots in a rich multi-room home environment. We provide an integrated learning framework, multimodal implementations of state-of-the-art multi-agent reinforcement learning techniques, and a consistent evaluation protocol. Our experiments investigate the impact of different modalities on multi-agent learning performance. We also introduce a simple message passing method between agents. The results suggest that multimodality introduces unique challenges for cooperative multi-agent learning and there is significant room for advancing multi-agent reinforcement learning methods in such settings.
Towards Large-Scale Interpretable Knowledge Graph Reasoning for Dialogue Systems
Mar 20, 2022
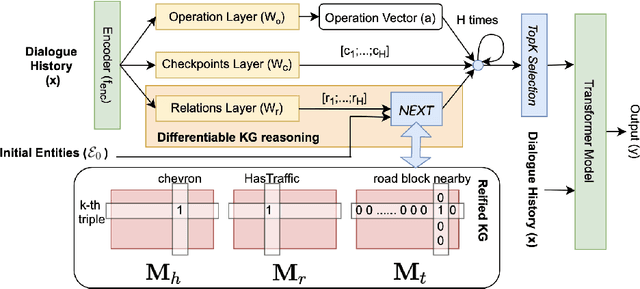
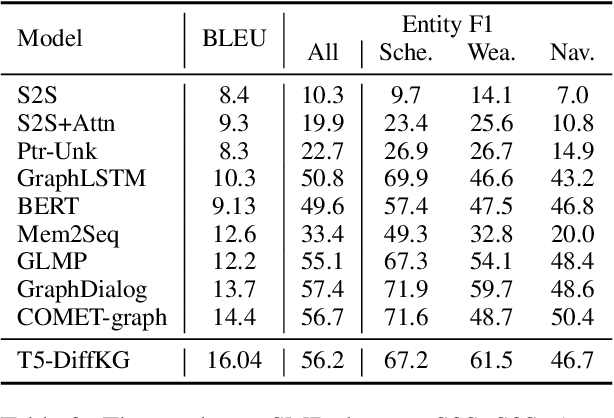
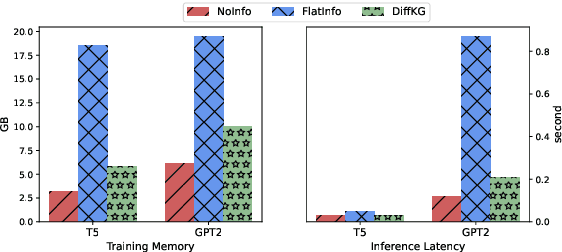
Users interacting with voice assistants today need to phrase their requests in a very specific manner to elicit an appropriate response. This limits the user experience, and is partly due to the lack of reasoning capabilities of dialogue platforms and the hand-crafted rules that require extensive labor. One possible way to improve user experience and relieve the manual efforts of designers is to build an end-to-end dialogue system that can do reasoning itself while perceiving user's utterances. In this work, we propose a novel method to incorporate the knowledge reasoning capability into dialogue systems in a more scalable and generalizable manner. Our proposed method allows a single transformer model to directly walk on a large-scale knowledge graph to generate responses. To the best of our knowledge, this is the first work to have transformer models generate responses by reasoning over differentiable knowledge graphs. We investigate the reasoning abilities of the proposed method on both task-oriented and domain-specific chit-chat dialogues. Empirical results show that this method can effectively and efficiently incorporate a knowledge graph into a dialogue system with fully-interpretable reasoning paths.