 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePheromone-Focused Ant Colony Optimization algorithm for path planning
Jan 12, 2026Ant Colony Optimization (ACO) is a prominent swarm intelligence algorithm extensively applied to path planning. However, traditional ACO methods often exhibit shortcomings, such as blind search behavior and slow convergence within complex environments. To address these challenges, this paper proposes the Pheromone-Focused Ant Colony Optimization (PFACO) algorithm, which introduces three key strategies to enhance the problem-solving ability of the ant colony. First, the initial pheromone distribution is concentrated in more promising regions based on the Euclidean distances of nodes to the start and end points, balancing the trade-off between exploration and exploitation. Second, promising solutions are reinforced during colony iterations to intensify pheromone deposition along high-quality paths, accelerating convergence while maintaining solution diversity. Third, a forward-looking mechanism is implemented to penalize redundant path turns, promoting smoother and more efficient solutions. These strategies collectively produce the focused pheromones to guide the ant colony's search, which enhances the global optimization capabilities of the PFACO algorithm, significantly improving convergence speed and solution quality across diverse optimization problems. The experimental results demonstrate that PFACO consistently outperforms comparative ACO algorithms in terms of convergence speed and solution quality.
Pro-AD: Learning Comprehensive Prototypes with Prototype-based Constraint for Multi-class Unsupervised Anomaly Detection
Jun 16, 2025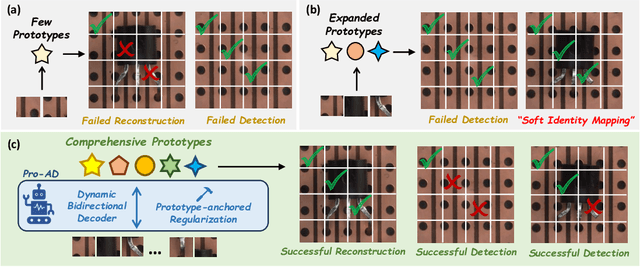

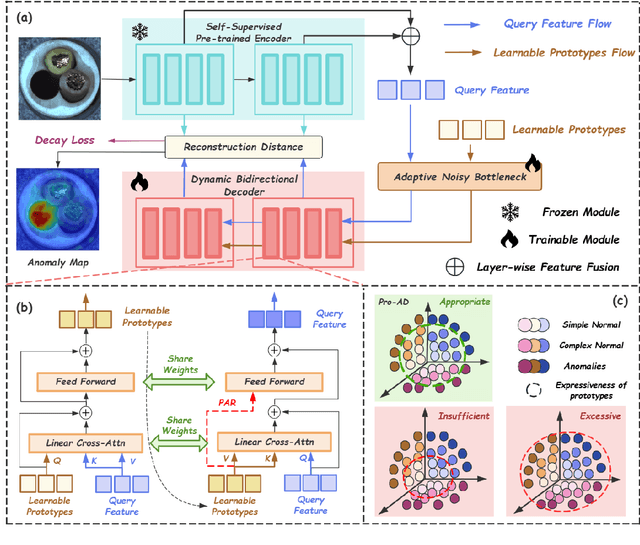

Prototype-based reconstruction methods for unsupervised anomaly detection utilize a limited set of learnable prototypes which only aggregates insufficient normal information, resulting in undesirable reconstruction. However, increasing the number of prototypes may lead to anomalies being well reconstructed through the attention mechanism, which we refer to as the "Soft Identity Mapping" problem. In this paper, we propose Pro-AD to address these issues and fully utilize the prototypes to boost the performance of anomaly detection. Specifically, we first introduce an expanded set of learnable prototypes to provide sufficient capacity for semantic information. Then we employ a Dynamic Bidirectional Decoder which integrates the process of the normal information aggregation and the target feature reconstruction via prototypes, with the aim of allowing the prototypes to aggregate more comprehensive normal semantic information from different levels of the image features and the target feature reconstruction to not only utilize its contextual information but also dynamically leverage the learned comprehensive prototypes. Additionally, to prevent the anomalies from being well reconstructed using sufficient semantic information through the attention mechanism, Pro-AD introduces a Prototype-based Constraint that applied within the target feature reconstruction process of the decoder, which further improves the performance of our approach. Extensive experiments on multiple challenging benchmarks demonstrate that our Pro-AD achieve state-of-the-art performance, highlighting its superior robustness and practical effectiveness for Multi-class Unsupervised Anomaly Detection task.
Real-IAD D3: A Real-World 2D/Pseudo-3D/3D Dataset for Industrial Anomaly Detection
Apr 19, 2025The increasing complexity of industrial anomaly detection (IAD) has positioned multimodal detection methods as a focal area of machine vision research. However, dedicated multimodal datasets specifically tailored for IAD remain limited. Pioneering datasets like MVTec 3D have laid essential groundwork in multimodal IAD by incorporating RGB+3D data, but still face challenges in bridging the gap with real industrial environments due to limitations in scale and resolution. To address these challenges, we introduce Real-IAD D3, a high-precision multimodal dataset that uniquely incorporates an additional pseudo3D modality generated through photometric stereo, alongside high-resolution RGB images and micrometer-level 3D point clouds. Real-IAD D3 features finer defects, diverse anomalies, and greater scale across 20 categories, providing a challenging benchmark for multimodal IAD Additionally, we introduce an effective approach that integrates RGB, point cloud, and pseudo-3D depth information to leverage the complementary strengths of each modality, enhancing detection performance. Our experiments highlight the importance of these modalities in boosting detection robustness and overall IAD performance. The dataset and code are publicly accessible for research purposes at https://realiad4ad.github.io/Real-IAD D3
ViG3D-UNet: Volumetric Vascular Connectivity-Aware Segmentation via 3D Vision Graph Representation
Apr 18, 2025



Accurate vascular segmentation is essential for coronary visualization and the diagnosis of coronary heart disease. This task involves the extraction of sparse tree-like vascular branches from the volumetric space. However, existing methods have faced significant challenges due to discontinuous vascular segmentation and missing endpoints. To address this issue, a 3D vision graph neural network framework, named ViG3D-UNet, was introduced. This method integrates 3D graph representation and aggregation within a U-shaped architecture to facilitate continuous vascular segmentation. The ViG3D module captures volumetric vascular connectivity and topology, while the convolutional module extracts fine vascular details. These two branches are combined through channel attention to form the encoder feature. Subsequently, a paperclip-shaped offset decoder minimizes redundant computations in the sparse feature space and restores the feature map size to match the original input dimensions. To evaluate the effectiveness of the proposed approach for continuous vascular segmentation, evaluations were performed on two public datasets, ASOCA and ImageCAS. The segmentation results show that the ViG3D-UNet surpassed competing methods in maintaining vascular segmentation connectivity while achieving high segmentation accuracy. Our code will be available soon.
Hybrid Gaussian Process Regression with Temporal Feature Extraction for Partially Interpretable Remaining Useful Life Interval Prediction in Aeroengine Prognostics
Nov 19, 2024The estimation of Remaining Useful Life (RUL) plays a pivotal role in intelligent manufacturing systems and Industry 4.0 technologies. While recent advancements have improved RUL prediction, many models still face interpretability and compelling uncertainty modeling challenges. This paper introduces a modified Gaussian Process Regression (GPR) model for RUL interval prediction, tailored for the complexities of manufacturing process development. The modified GPR predicts confidence intervals by learning from historical data and addresses uncertainty modeling in a more structured way. The approach effectively captures intricate time-series patterns and dynamic behaviors inherent in modern manufacturing systems by coupling GPR with deep adaptive learning-enhanced AI process models. Moreover, the model evaluates feature significance to ensure more transparent decision-making, which is crucial for optimizing manufacturing processes. This comprehensive approach supports more accurate RUL predictions and provides transparent, interpretable insights into uncertainty, contributing to robust process development and management.
Improving Generalization in Visual Reinforcement Learning via Conflict-aware Gradient Agreement Augmentation
Aug 02, 2023



Learning a policy with great generalization to unseen environments remains challenging but critical in visual reinforcement learning. Despite the success of augmentation combination in the supervised learning generalization, naively applying it to visual RL algorithms may damage the training efficiency, suffering from serve performance degradation. In this paper, we first conduct qualitative analysis and illuminate the main causes: (i) high-variance gradient magnitudes and (ii) gradient conflicts existed in various augmentation methods. To alleviate these issues, we propose a general policy gradient optimization framework, named Conflict-aware Gradient Agreement Augmentation (CG2A), and better integrate augmentation combination into visual RL algorithms to address the generalization bias. In particular, CG2A develops a Gradient Agreement Solver to adaptively balance the varying gradient magnitudes, and introduces a Soft Gradient Surgery strategy to alleviate the gradient conflicts. Extensive experiments demonstrate that CG2A significantly improves the generalization performance and sample efficiency of visual RL algorithms.