 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan Image Splicing and Copy-Move Forgery Be Detected by the Same Model? Forensim: An Attention-Based State-Space Approach
Feb 10, 2026We introduce Forensim, an attention-based state-space framework for image forgery detection that jointly localizes both manipulated (target) and source regions. Unlike traditional approaches that rely solely on artifact cues to detect spliced or forged areas, Forensim is designed to capture duplication patterns crucial for understanding context. In scenarios such as protest imagery, detecting only the forged region, for example a duplicated act of violence inserted into a peaceful crowd, can mislead interpretation, highlighting the need for joint source-target localization. Forensim outputs three-class masks (pristine, source, target) and supports detection of both splicing and copy-move forgeries within a unified architecture. We propose a visual state-space model that leverages normalized attention maps to identify internal similarities, paired with a region-based block attention module to distinguish manipulated regions. This design enables end-to-end training and precise localization. Forensim achieves state-of-the-art performance on standard benchmarks. We also release CMFD-Anything, a new dataset addressing limitations of existing copy-move forgery datasets.
BioTamperNet: Affinity-Guided State-Space Model Detecting Tampered Biomedical Images
Feb 01, 2026We propose BioTamperNet, a novel framework for detecting duplicated regions in tampered biomedical images, leveraging affinity-guided attention inspired by State Space Model (SSM) approximations. Existing forensic models, primarily trained on natural images, often underperform on biomedical data where subtle manipulations can compromise experimental validity. To address this, BioTamperNet introduces an affinity-guided self-attention module to capture intra-image similarities and an affinity-guided cross-attention module to model cross-image correspondences. Our design integrates lightweight SSM-inspired linear attention mechanisms to enable efficient, fine-grained localization. Trained end-to-end, BioTamperNet simultaneously identifies tampered regions and their source counterparts. Extensive experiments on the benchmark bio-forensic datasets demonstrate significant improvements over competitive baselines in accurately detecting duplicated regions. Code - https://github.com/SoumyaroopNandi/BioTamperNet
Rescind: Countering Image Misconduct in Biomedical Publications with Vision-Language and State-Space Modeling
Jan 12, 2026Scientific image manipulation in biomedical publications poses a growing threat to research integrity and reproducibility. Unlike natural image forensics, biomedical forgery detection is uniquely challenging due to domain-specific artifacts, complex textures, and unstructured figure layouts. We present the first vision-language guided framework for both generating and detecting biomedical image forgeries. By combining diffusion-based synthesis with vision-language prompting, our method enables realistic and semantically controlled manipulations, including duplication, splicing, and region removal, across diverse biomedical modalities. We introduce Rescind, a large-scale benchmark featuring fine-grained annotations and modality-specific splits, and propose Integscan, a structured state space modeling framework that integrates attention-enhanced visual encoding with prompt-conditioned semantic alignment for precise forgery localization. To ensure semantic fidelity, we incorporate a vision-language model based verification loop that filters generated forgeries based on consistency with intended prompts. Extensive experiments on Rescind and existing benchmarks demonstrate that Integscan achieves state of the art performance in both detection and localization, establishing a strong foundation for automated scientific integrity analysis.
TrainFors: A Large Benchmark Training Dataset for Image Manipulation Detection and Localization
Aug 10, 2023



The evaluation datasets and metrics for image manipulation detection and localization (IMDL) research have been standardized. But the training dataset for such a task is still nonstandard. Previous researchers have used unconventional and deviating datasets to train neural networks for detecting image forgeries and localizing pixel maps of manipulated regions. For a fair comparison, the training set, test set, and evaluation metrics should be persistent. Hence, comparing the existing methods may not seem fair as the results depend heavily on the training datasets as well as the model architecture. Moreover, none of the previous works release the synthetic training dataset used for the IMDL task. We propose a standardized benchmark training dataset for image splicing, copy-move forgery, removal forgery, and image enhancement forgery. Furthermore, we identify the problems with the existing IMDL datasets and propose the required modifications. We also train the state-of-the-art IMDL methods on our proposed TrainFors1 dataset for a fair evaluation and report the actual performance of these methods under similar conditions.
Alexa, play with robot: Introducing the First Alexa Prize SimBot Challenge on Embodied AI
Aug 09, 2023



The Alexa Prize program has empowered numerous university students to explore, experiment, and showcase their talents in building conversational agents through challenges like the SocialBot Grand Challenge and the TaskBot Challenge. As conversational agents increasingly appear in multimodal and embodied contexts, it is important to explore the affordances of conversational interaction augmented with computer vision and physical embodiment. This paper describes the SimBot Challenge, a new challenge in which university teams compete to build robot assistants that complete tasks in a simulated physical environment. This paper provides an overview of the SimBot Challenge, which included both online and offline challenge phases. We describe the infrastructure and support provided to the teams including Alexa Arena, the simulated environment, and the ML toolkit provided to teams to accelerate their building of vision and language models. We summarize the approaches the participating teams took to overcome research challenges and extract key lessons learned. Finally, we provide analysis of the performance of the competing SimBots during the competition.
AMPERE: AMR-Aware Prefix for Generation-Based Event Argument Extraction Model
May 26, 2023



Event argument extraction (EAE) identifies event arguments and their specific roles for a given event. Recent advancement in generation-based EAE models has shown great performance and generalizability over classification-based models. However, existing generation-based EAE models mostly focus on problem re-formulation and prompt design, without incorporating additional information that has been shown to be effective for classification-based models, such as the abstract meaning representation (AMR) of the input passages. Incorporating such information into generation-based models is challenging due to the heterogeneous nature of the natural language form prevalently used in generation-based models and the structured form of AMRs. In this work, we study strategies to incorporate AMR into generation-based EAE models. We propose AMPERE, which generates AMR-aware prefixes for every layer of the generation model. Thus, the prefix introduces AMR information to the generation-based EAE model and then improves the generation. We also introduce an adjusted copy mechanism to AMPERE to help overcome potential noises brought by the AMR graph. Comprehensive experiments and analyses on ACE2005 and ERE datasets show that AMPERE can get 4% - 10% absolute F1 score improvements with reduced training data and it is in general powerful across different training sizes.
Alexa Arena: A User-Centric Interactive Platform for Embodied AI
Mar 02, 2023



We introduce Alexa Arena, a user-centric simulation platform for Embodied AI (EAI) research. Alexa Arena provides a variety of multi-room layouts and interactable objects, for the creation of human-robot interaction (HRI) missions. With user-friendly graphics and control mechanisms, Alexa Arena supports the development of gamified robotic tasks readily accessible to general human users, thus opening a new venue for high-efficiency HRI data collection and EAI system evaluation. Along with the platform, we introduce a dialog-enabled instruction-following benchmark and provide baseline results for it. We make Alexa Arena publicly available to facilitate research in building generalizable and assistive embodied agents.
AlexaTM 20B: Few-Shot Learning Using a Large-Scale Multilingual Seq2Seq Model
Aug 03, 2022


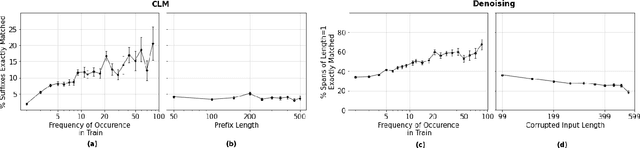
In this work, we demonstrate that multilingual large-scale sequence-to-sequence (seq2seq) models, pre-trained on a mixture of denoising and Causal Language Modeling (CLM) tasks, are more efficient few-shot learners than decoder-only models on various tasks. In particular, we train a 20 billion parameter multilingual seq2seq model called Alexa Teacher Model (AlexaTM 20B) and show that it achieves state-of-the-art (SOTA) performance on 1-shot summarization tasks, outperforming a much larger 540B PaLM decoder model. AlexaTM 20B also achieves SOTA in 1-shot machine translation, especially for low-resource languages, across almost all language pairs supported by the model (Arabic, English, French, German, Hindi, Italian, Japanese, Marathi, Portuguese, Spanish, Tamil, and Telugu) on Flores-101 dataset. We also show in zero-shot setting, AlexaTM 20B outperforms GPT3 (175B) on SuperGLUE and SQuADv2 datasets and provides SOTA performance on multilingual tasks such as XNLI, XCOPA, Paws-X, and XWinograd. Overall, our results present a compelling case for seq2seq models as a powerful alternative to decoder-only models for Large-scale Language Model (LLM) training.
MONet: Multi-scale Overlap Network for Duplication Detection in Biomedical Images
Jul 19, 2022

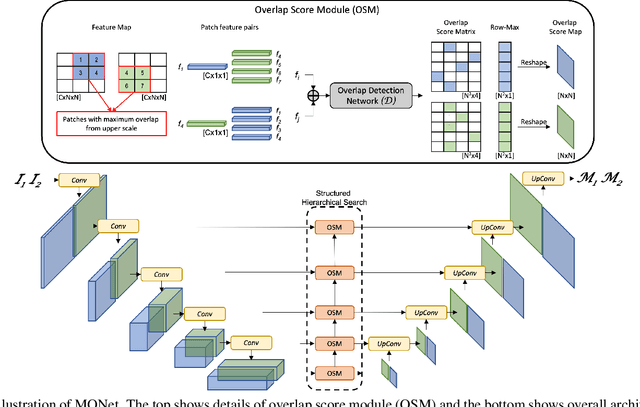
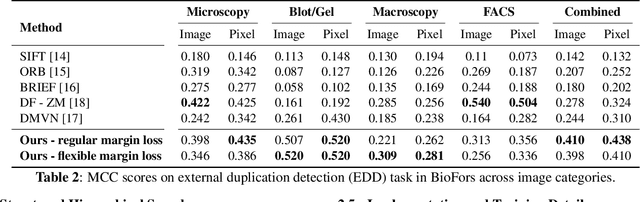
Manipulation of biomedical images to misrepresent experimental results has plagued the biomedical community for a while. Recent interest in the problem led to the curation of a dataset and associated tasks to promote the development of biomedical forensic methods. Of these, the largest manipulation detection task focuses on the detection of duplicated regions between images. Traditional computer-vision based forensic models trained on natural images are not designed to overcome the challenges presented by biomedical images. We propose a multi-scale overlap detection model to detect duplicated image regions. Our model is structured to find duplication hierarchically, so as to reduce the number of patch operations. It achieves state-of-the-art performance overall and on multiple biomedical image categories.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022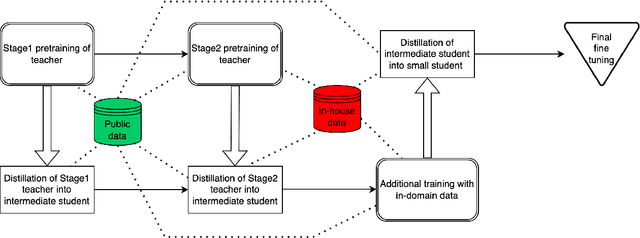
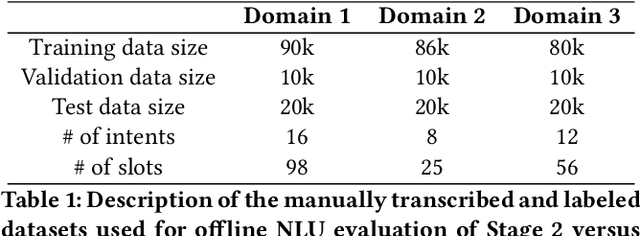
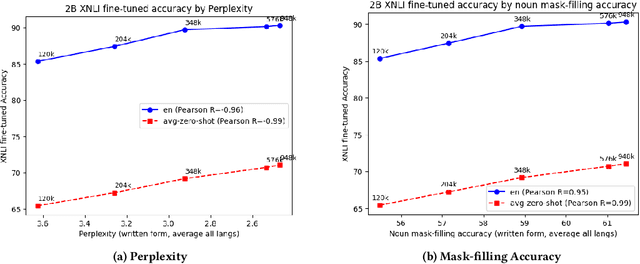
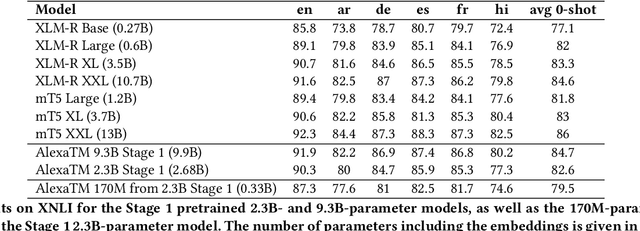
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022