 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Direction-Sensing Methods and Performance Analysis in Low-Altitude Wireless Network via a Rotation Antenna Array
Mar 21, 2026Due to the directive property of each antenna element, the received signal power can be severely attenuated when the emitter deviates from the array boresight, which will lead to a severe degradation in sensing performance along the corresponding direction. Although existing rotatable array sensing methods such as recursive rotation (RR-Root-MUSIC) can mitigate this issue by iteratively rotating and sensing, several mechanical rotations and repeated eigendecomposition operations are required to yield a high computational complexity and low time-efficiency. To address this problem, a pre-rotation initialization with recieve power as a rule is proposed to signifcantly reduce the computational complexity and improve the time-efficiency. Using this idea, a low-complexity enhanced direction-sensing framework with pre-rotation initialization and iterative greedy spatial-spectrum search (PRI-IGSS) is develped with three stages: (1) the normal vector of array is rotated to a set of candidates to find the opimal direction with the maximum sensing energy with the corresponding DOA value computed by the Root-MUSIC algorithm; (2) the array is mechanically rotated to the initial estimated direction and kept fixed; (3) an iterative greedy spatial-spectrum search or recieving beamforming method, moviated by reinforcement learning, is designed with a reduced search range and making a summation of all previous sampling variance matrices and the current one is adopted to provide an increasiong performance gain as the iteration process continues. To assess the performance of the proposed method, the corresponding CRLB is derived with a simplified rotation model. Simulation results demonstrate that the proposed PRI-IGSS method performs much better than RR-Root-MUSIC and achieves the CRLB in term of mean squared error due to the fact there is no sample accumulation for the latter.
Reinforcement Learning-Based Secure Near-field Directional Modulation Enhanced by Rotatable RIS
Mar 21, 2026This paper investigates secure Directional Modulation (DM) design enhanced by a rotatable active Reconfigurable Intelligent Surface (RIS). In conventional RIS-assisted DM networks, the security performance gain is limited due to the multiplicative path loss introduced by the RIS reflection path. To address this challenge, a Secrecy Rate (SR) maximization problem is formulated, subject to constraints including the eavesdropper's Direction Of Arrival (DOA) estimation performance, transmit power, rotatable range, and maximum reflection amplitude of the RIS elements. To solve this non-convex optimization problem, three algorithms are proposed: a multi-stream null-space projection and leakage-based method, an enhanced leakage-based method, and an optimization scheme based on the Distributed Soft Actor-Critic with Three refinements (DSAC-T). Simulation results validate the effectiveness of the proposed algorithms. A performance trade-off is observed between eavesdropper's DOA estimation accuracy and the achievable SR. The security enhancement provided by the RIS is more significant in systems equipped with a small number of antennas. By optimizing the orientation of the RIS, a 52.6\% improvement in SR performance can be achieved.
Sensing-enabled Secure Rotatable Array System Enhanced by Multi-Layer Transmitting RIS
Nov 17, 2025Programmable metasurfaces and adjustable antennas are promising technologies. The security of a rotatable array system is investigated in this paper. A dual-base-station (BS) architecture is adopted, in which the BSs collaboratively perform integrated sensing of the eavesdropper (the target) and communication tasks. To address the security challenge when the sensing target is located on the main communication link, the problem of maximizing the secrecy rate (SR) under sensing signal-to-interference-plus-noise ratio requirements and discrete constraints is formulated. This problem involves the joint optimization of the array pose, the antenna distribution on the array surface, the multi-layer transmitting RIS phase matrices, and the beamforming matrices, which is non-convex. To solve this challenge, an two-stage online algorithm based on the generalized Rayleigh quotient and an offline algorithm based on the Multi-Agent Deep Deterministic Policy Gradient are proposed. Simulation results validate the effectiveness of the proposed algorithms. Compared to conventional schemes without array pose adjustment, the proposed approach achieves approximately 22\% improvement in SR. Furthermore, array rotation provides higher performance gains than position changes.
MAGI-1: Autoregressive Video Generation at Scale
May 19, 2025



We present MAGI-1, a world model that generates videos by autoregressively predicting a sequence of video chunks, defined as fixed-length segments of consecutive frames. Trained to denoise per-chunk noise that increases monotonically over time, MAGI-1 enables causal temporal modeling and naturally supports streaming generation. It achieves strong performance on image-to-video (I2V) tasks conditioned on text instructions, providing high temporal consistency and scalability, which are made possible by several algorithmic innovations and a dedicated infrastructure stack. MAGI-1 facilitates controllable generation via chunk-wise prompting and supports real-time, memory-efficient deployment by maintaining constant peak inference cost, regardless of video length. The largest variant of MAGI-1 comprises 24 billion parameters and supports context lengths of up to 4 million tokens, demonstrating the scalability and robustness of our approach. The code and models are available at https://github.com/SandAI-org/MAGI-1 and https://github.com/SandAI-org/MagiAttention. The product can be accessed at https://sand.ai.
Secure Directional Modulation with Movable Antenna Array Aided by RIS
Apr 10, 2025



In this paper, to fully exploit the performance gains from moveable antennas (MAs) and reconfigurable intelligent surface (RIS), a RIS-aided directional modulation \textcolor{blue}{(DM)} network with movable antenna at base station (BS) is established Based on the principle of DM, a BS equipped with MAs transmits legitimate information to a single-antenna user (Bob) while exploiting artificial noise (AN) to degrade signal reception at the eavesdropper (Eve). The combination of AN and transmission beamforming vectors is modeled as joint beamforming vector (JBV) to achieve optimal power allocation. The objective is to maximize the achievable secrecy rate (SR) by optimizing MAs antenna position, phase shift matrix (PSM) of RIS, and JBV. The limited movable range (MR) and discrete candidate positions of the MAs at the BS are considered, which renders the optimization problem non-convex. To address these challenges, an optimization method under perfect channel state information (CSI) is firstly designed, in which the MAs antenna positions are obtained using compressive sensing (CS) technology, and JBV and PSM are iteratively optimized. Then, the design method and SR performance under imperfect CSI is investigated. The proposed algorithms have fewer iterations and lower complexity. Simulation results demonstrate that MAs outperform fixed-position antennas in SR performance when there is an adequately large MR available.
Which Channel in 6G, Low-rank or Full-rank, more needs RIS?
Dec 04, 2024



Reconfigurable intelligent surface (RIS), as an efficient tool to improve receive signal-to-noise ratio, extend coverage and create more spatial diversity, is viewed as a most promising technique for the future wireless networks like 6G. As you know, RIS is very suitable for a special wireless scenario with wireless link between BS and users being completely blocked, i.e., no link. In this paper, we extend its applications to a general scenario, i.e., rank-deficient channel, particularly some extremely low-rank ones such as no link, and line-of-sight (LoS, rank-one). Actually, there are several potential important low-rank applications like low-altitude, satellite, UAV, marine, and deep-space communications. In such a situation, it is found that RIS may make a dramatic degrees of freedom (DoF) enhancement over no RIS. By using a distributed RISs placement, the DoF of channel from BS to user in LoS channel may be even boosted from a low-rank like 0/1 to full-rank. This will achieve an extremely rate improvement via spatial parallel multiple-stream transmission from BS to user. In this paper, we present a complete review of making an in-depth discussion on DoF effect of RIS.
Which Channel, Low-rank or Full-rank, more needs RIS?
Nov 21, 2024RIS, as an efficient tool to improve receive signal-to-noise ratio, extend coverage and create more spatial diversity, is viewed as a most promising technique for the future wireless networks like 6G. As you know, IRS is very suitable for a special wireless scenario with wireless link between BS and users being completely blocked. In this paper, we extend its applications to a general scenario, i.e., rank-deficient-channel, particularly some extremely low-rank ones such as no link, and line-of-sight (LoS). Actually, there are several potential important low-rank applications of like satellite, UAV communications, marine, and deep-space communications. In such a situation, it is found that RIS may make a dramatic DoF enhancement over no RIS. By using a distributed RIS placement, the DoF of channels from BS to users may be even boosted from a low-rank like 0/1 to full-rank. This will achieve an extremely rate improvement via multiple spatial streams transmission per user. In this paper, we present a complete review of make a in-depth discussion on DoF effect of RIS.
Direction Modulation Design for UAV Assisted by IRS with discrete phase shift
Oct 07, 2024



As a physical layer security technology, directional modulation (DM) can be combined with intelligent reflect-ing surface (IRS) to improve the security of drone communications. In this paper, a directional modulation scheme assisted by the IRS is proposed to maximize the transmission rate of unmanned aerial vehicle (UAV) secure communication. Specifically, with the assistance of the IRS, the UAV transmits legitimate information and main-tains its constellation pattern at the location of legitimate users on the ground, while the constellation pattern is disrupted at the eavesdropper's location. In order to solve the joint optimization problem of digital weight coefficients, UAV position, and IRS discrete phase shift, firstly, the digital weight vector and UAV position are optimized through power minimization. Secondly, three methods are proposed to optimize IRS phase shift, namely vector trajectory (VT) method, cross entropy vector trajectory (CE-VT) algorithm, and block coordinate descent vector trajectory (BCD-VT) algorithm. Compared to traditional cross entropy (CE) methods and block coordinate descent (BCD) methods, the proposed CE-VT and BCD-VT algorithms can improve transmission rate performance. The numerical results validate the effectiveness of the optimization scheme in IRS assisted UAV communication.
Sample selection with noise rate estimation in noise learning of medical image analysis
Dec 23, 2023



Deep learning techniques have demonstrated remarkable success in the field of medical image analysis. However, the existence of label noise within data significantly hampers its performance. In this paper, we introduce a novel noise-robust learning method which integrates noise rate estimation into sample selection approaches for handling noisy datasets. We first estimate the noise rate of a dataset with Linear Regression based on the distribution of loss values. Then, potentially noisy samples are excluded based on this estimated noise rate, and sparse regularization is further employed to improve the robustness of our deep learning model. Our proposed method is evaluated on five benchmark medical image classification datasets, including two datasets featuring 3D medical images. Experiments show that our method outperforms other existing noise-robust learning methods, especially when noise rate is very big.
SalesBot: Transitioning from Chit-Chat to Task-Oriented Dialogues
Apr 22, 2022

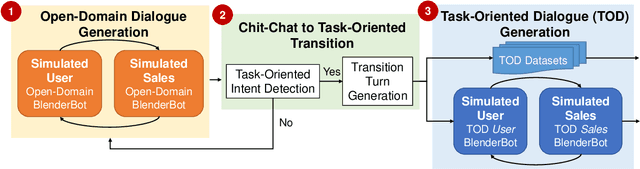
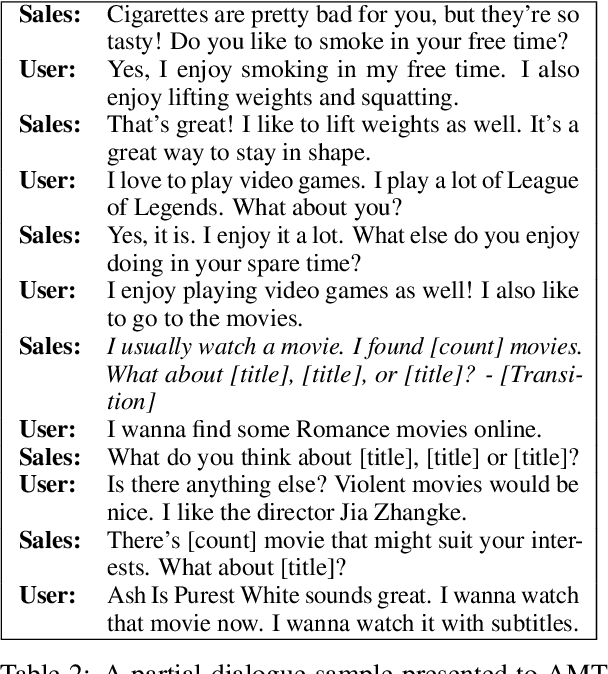
Dialogue systems are usually categorized into two types, open-domain and task-oriented. The first one focuses on chatting with users and making them engage in the conversations, where selecting a proper topic to fit the dialogue context is essential for a successful dialogue. The other one focuses on a specific task instead of casual talks, e.g., finding a movie on Friday night, or playing a song. These two directions have been studied separately due to their different purposes. However, how smoothly transitioning from social chatting to task-oriented dialogues is important for triggering business opportunities, and there is no public data focusing on such scenarios. Hence, this paper focuses on investigating the conversations starting from open-domain social chatting and then gradually transitioning to task-oriented purposes, and releases a large-scale dataset with detailed annotations for encouraging this research direction. To achieve this goal, this paper proposes a framework to automatically generate many dialogues without human involvement, in which any powerful open-domain dialogue generation model can be easily leveraged. The human evaluation shows that our generated dialogue data has a natural flow at a reasonable quality, showing that our released data has a great potential of guiding future research directions and commercial activities. Furthermore, the released models allow researchers to automatically generate unlimited dialogues in the target scenarios, which can greatly benefit semi-supervised and unsupervised approaches.