 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMechanism-Guided Selective Unlearning for RLVR-Induced Reasoning
Jun 17, 2026We propose MAST (Mechanism-Aligned Selective Targeting), a mechanism-guided method for unlearning RLVR-induced reasoning with substantially lower collateral damage than standard full-parameter updates. In matched SFT/RLVR checkpoints on Qwen2.5-Math-1.5B and Qwen3-1.7B-Base, the SFT-to-RLVR increment differs sharply from the SFT update in token-level delta-log-probability, and full-parameter gradient ascent forgets only by damaging retain MATH and GSM8K. MAST ranks attention-projection tensors by off-principal energy, update magnitude, and forget-gradient coupling magnitude, then updates only the top-ranked subset. On the primary model, MAST induces statistically significant target forgetting (MATH forget 45/150 to 37/150; McNemar p=0.0078) while preserving GSM8K (+0.8 pp) and MATH retain (-0.5 pp). The advantage reproduces across seeds, NPO/SimNPO objectives, and Qwen3, where MAST preserves GSM8K while full-parameter unlearning collapses it.
The Vision Encoder as a Privacy Boundary: Visual-Token Side Channels in Encoder-Free Vision-Language Models
Jun 10, 2026A vision encoder compresses image pixels into semantic embeddings, implicitly acting as a privacy boundary by preserving semantic content while attenuating pixel-local detail required for exact text recovery. Encoder-free vision-language models (VLMs) remove this boundary by routing image patches directly into the language-model token stream, thereby exposing an architectural privacy attack surface: intermediate visual tokens become a pre-output side channel. Under a token-access adversary, decoders invert visual-token streams from two encoder-free VLMs, Gemma4 and Fuyu, recovering recognizable image structure and readable held-out access codes, whereas matched encoder-based controls localize target regions but recover no exact strings. Within-model ablations show that the operative factor is spatial sampling fidelity of the visual-token grid, especially character-direction sampling density, rather than token or value count. The leakage is not limited to exported tokens: Gemma4 layer-0 key-value cache tensors are directly invertible, placing the side channel within KV caches commonly persisted by production serving stacks for decoding efficiency. The attack survives clutter, realistic document degradation, and zero-shot transfer to public document images, and it resists value-level defenses such as additive noise and quantization. Effective mitigation must therefore reduce spatial sampling, making removal of the vision encoder a first-class privacy decision in VLM deployment.
One Ring to Rule Them All: Unifying Group-Based RL via Dynamic Power-Mean Geometry
Jan 30, 2026Group-based reinforcement learning has evolved from the arithmetic mean of GRPO to the geometric mean of GMPO. While GMPO improves stability by constraining a conservative objective, it shares a fundamental limitation with GRPO: reliance on a fixed aggregation geometry that ignores the evolving and heterogeneous nature of each trajectory. In this work, we unify these approaches under Power-Mean Policy Optimization (PMPO), a generalized framework that parameterizes the aggregation geometry via the power-mean geometry exponent p. Within this framework, GRPO and GMPO are recovered as special cases. Theoretically, we demonstrate that adjusting p modulates the concentration of gradient updates, effectively reweighting tokens based on their advantage contribution. To determine p adaptively, we introduce a Clip-aware Effective Sample Size (ESS) mechanism. Specifically, we propose a deterministic rule that maps a trajectory clipping fraction to a target ESS. Then, we solve for the specific p to align the trajectory induced ESS with this target one. This allows PMPO to dynamically transition between the aggressive arithmetic mean for reliable trajectories and the conservative geometric mean for unstable ones. Experiments on multiple mathematical reasoning benchmarks demonstrate that PMPO outperforms strong baselines.
Step-GUI Technical Report
Dec 19, 2025



Recent advances in multimodal large language models unlock unprecedented opportunities for GUI automation. However, a fundamental challenge remains: how to efficiently acquire high-quality training data while maintaining annotation reliability? We introduce a self-evolving training pipeline powered by the Calibrated Step Reward System, which converts model-generated trajectories into reliable training signals through trajectory-level calibration, achieving >90% annotation accuracy with 10-100x lower cost. Leveraging this pipeline, we introduce Step-GUI, a family of models (4B/8B) that achieves state-of-the-art GUI performance (8B: 80.2% AndroidWorld, 48.5% OSWorld, 62.6% ScreenShot-Pro) while maintaining robust general capabilities. As GUI agent capabilities improve, practical deployment demands standardized interfaces across heterogeneous devices while protecting user privacy. To this end, we propose GUI-MCP, the first Model Context Protocol for GUI automation with hierarchical architecture that combines low-level atomic operations and high-level task delegation to local specialist models, enabling high-privacy execution where sensitive data stays on-device. Finally, to assess whether agents can handle authentic everyday usage, we introduce AndroidDaily, a benchmark grounded in real-world mobile usage patterns with 3146 static actions and 235 end-to-end tasks across high-frequency daily scenarios (8B: static 89.91%, end-to-end 52.50%). Our work advances the development of practical GUI agents and demonstrates strong potential for real-world deployment in everyday digital interactions.
AdaTooler-V: Adaptive Tool-Use for Images and Videos
Dec 19, 2025



Recent advances have shown that multimodal large language models (MLLMs) benefit from multimodal interleaved chain-of-thought (CoT) with vision tool interactions. However, existing open-source models often exhibit blind tool-use reasoning patterns, invoking vision tools even when they are unnecessary, which significantly increases inference overhead and degrades model performance. To this end, we propose AdaTooler-V, an MLLM that performs adaptive tool-use by determining whether a visual problem truly requires tools. First, we introduce AT-GRPO, a reinforcement learning algorithm that adaptively adjusts reward scales based on the Tool Benefit Score of each sample, encouraging the model to invoke tools only when they provide genuine improvements. Moreover, we construct two datasets to support training: AdaTooler-V-CoT-100k for SFT cold start and AdaTooler-V-300k for RL with verifiable rewards across single-image, multi-image, and video data. Experiments across twelve benchmarks demonstrate the strong reasoning capability of AdaTooler-V, outperforming existing methods in diverse visual reasoning tasks. Notably, AdaTooler-V-7B achieves an accuracy of 89.8\% on the high-resolution benchmark V*, surpassing the commercial proprietary model GPT-4o and Gemini 1.5 Pro. All code, models, and data are released.
Adaptive Agent Selection and Interaction Network for Image-to-point cloud Registration
Nov 08, 2025Typical detection-free methods for image-to-point cloud registration leverage transformer-based architectures to aggregate cross-modal features and establish correspondences. However, they often struggle under challenging conditions, where noise disrupts similarity computation and leads to incorrect correspondences. Moreover, without dedicated designs, it remains difficult to effectively select informative and correlated representations across modalities, thereby limiting the robustness and accuracy of registration. To address these challenges, we propose a novel cross-modal registration framework composed of two key modules: the Iterative Agents Selection (IAS) module and the Reliable Agents Interaction (RAI) module. IAS enhances structural feature awareness with phase maps and employs reinforcement learning principles to efficiently select reliable agents. RAI then leverages these selected agents to guide cross-modal interactions, effectively reducing mismatches and improving overall robustness. Extensive experiments on the RGB-D Scenes v2 and 7-Scenes benchmarks demonstrate that our method consistently achieves state-of-the-art performance.
AeroDuo: Aerial Duo for UAV-based Vision and Language Navigation
Aug 21, 2025Aerial Vision-and-Language Navigation (VLN) is an emerging task that enables Unmanned Aerial Vehicles (UAVs) to navigate outdoor environments using natural language instructions and visual cues. However, due to the extended trajectories and complex maneuverability of UAVs, achieving reliable UAV-VLN performance is challenging and often requires human intervention or overly detailed instructions. To harness the advantages of UAVs' high mobility, which could provide multi-grained perspectives, while maintaining a manageable motion space for learning, we introduce a novel task called Dual-Altitude UAV Collaborative VLN (DuAl-VLN). In this task, two UAVs operate at distinct altitudes: a high-altitude UAV responsible for broad environmental reasoning, and a low-altitude UAV tasked with precise navigation. To support the training and evaluation of the DuAl-VLN, we construct the HaL-13k, a dataset comprising 13,838 collaborative high-low UAV demonstration trajectories, each paired with target-oriented language instructions. This dataset includes both unseen maps and an unseen object validation set to systematically evaluate the model's generalization capabilities across novel environments and unfamiliar targets. To consolidate their complementary strengths, we propose a dual-UAV collaborative VLN framework, AeroDuo, where the high-altitude UAV integrates a multimodal large language model (Pilot-LLM) for target reasoning, while the low-altitude UAV employs a lightweight multi-stage policy for navigation and target grounding. The two UAVs work collaboratively and only exchange minimal coordinate information to ensure efficiency.
DeepGo: Predictive Directed Greybox Fuzzing
Jul 29, 2025The state-of-the-art DGF techniques redefine and optimize the fitness metric to reach the target sites precisely and quickly. However, optimizations for fitness metrics are mainly based on heuristic algorithms, which usually rely on historical execution information and lack foresight on paths that have not been exercised yet. Thus, those hard-to-execute paths with complex constraints would hinder DGF from reaching the targets, making DGF less efficient. In this paper, we propose DeepGo, a predictive directed grey-box fuzzer that can combine historical and predicted information to steer DGF to reach the target site via an optimal path. We first propose the path transition model, which models DGF as a process of reaching the target site through specific path transition sequences. The new seed generated by mutation would cause the path transition, and the path corresponding to the high-reward path transition sequence indicates a high likelihood of reaching the target site through it. Then, to predict the path transitions and the corresponding rewards, we use deep neural networks to construct a Virtual Ensemble Environment (VEE), which gradually imitates the path transition model and predicts the rewards of path transitions that have not been taken yet. To determine the optimal path, we develop a Reinforcement Learning for Fuzzing (RLF) model to generate the transition sequences with the highest sequence rewards. The RLF model can combine historical and predicted path transitions to generate the optimal path transition sequences, along with the policy to guide the mutation strategy of fuzzing. Finally, to exercise the high-reward path transition sequence, we propose the concept of an action group, which comprehensively optimizes the critical steps of fuzzing to realize the optimal path to reach the target efficiently.
Unleashing the Potential of Consistency Learning for Detecting and Grounding Multi-Modal Media Manipulation
Jun 06, 2025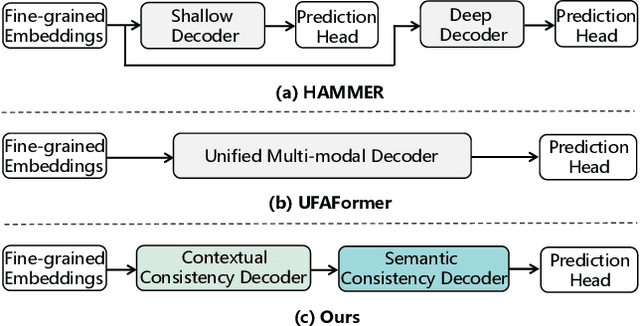
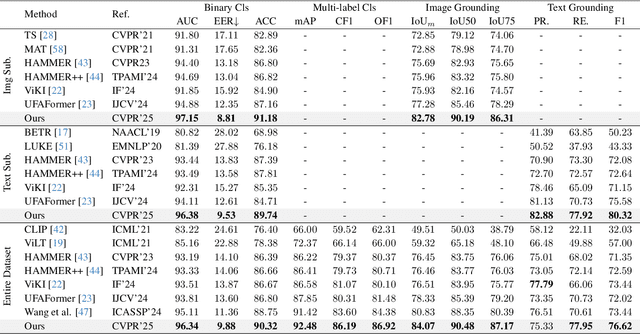
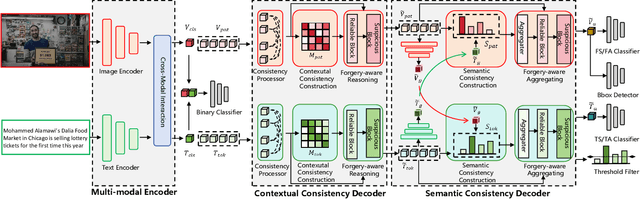
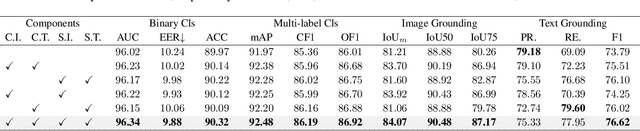
To tackle the threat of fake news, the task of detecting and grounding multi-modal media manipulation DGM4 has received increasing attention. However, most state-of-the-art methods fail to explore the fine-grained consistency within local content, usually resulting in an inadequate perception of detailed forgery and unreliable results. In this paper, we propose a novel approach named Contextual-Semantic Consistency Learning (CSCL) to enhance the fine-grained perception ability of forgery for DGM4. Two branches for image and text modalities are established, each of which contains two cascaded decoders, i.e., Contextual Consistency Decoder (CCD) and Semantic Consistency Decoder (SCD), to capture within-modality contextual consistency and across-modality semantic consistency, respectively. Both CCD and SCD adhere to the same criteria for capturing fine-grained forgery details. To be specific, each module first constructs consistency features by leveraging additional supervision from the heterogeneous information of each token pair. Then, the forgery-aware reasoning or aggregating is adopted to deeply seek forgery cues based on the consistency features. Extensive experiments on DGM4 datasets prove that CSCL achieves new state-of-the-art performance, especially for the results of grounding manipulated content. Codes and weights are avaliable at https://github.com/liyih/CSCL.
InstructSAM: A Training-Free Framework for Instruction-Oriented Remote Sensing Object Recognition
May 21, 2025Language-Guided object recognition in remote sensing imagery is crucial for large-scale mapping and automated data annotation. However, existing open-vocabulary and visual grounding methods rely on explicit category cues, limiting their ability to handle complex or implicit queries that require advanced reasoning. To address this issue, we introduce a new suite of tasks, including Instruction-Oriented Object Counting, Detection, and Segmentation (InstructCDS), covering open-vocabulary, open-ended, and open-subclass scenarios. We further present EarthInstruct, the first InstructCDS benchmark for earth observation. It is constructed from two diverse remote sensing datasets with varying spatial resolutions and annotation rules across 20 categories, necessitating models to interpret dataset-specific instructions. Given the scarcity of semantically rich labeled data in remote sensing, we propose InstructSAM, a training-free framework for instruction-driven object recognition. InstructSAM leverages large vision-language models to interpret user instructions and estimate object counts, employs SAM2 for mask proposal, and formulates mask-label assignment as a binary integer programming problem. By integrating semantic similarity with counting constraints, InstructSAM efficiently assigns categories to predicted masks without relying on confidence thresholds. Experiments demonstrate that InstructSAM matches or surpasses specialized baselines across multiple tasks while maintaining near-constant inference time regardless of object count, reducing output tokens by 89% and overall runtime by over 32% compared to direct generation approaches. We believe the contributions of the proposed tasks, benchmark, and effective approach will advance future research in developing versatile object recognition systems.