 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexLoRA: Entropy-Guided Flexible Low-Rank Adaptation
Jan 30, 2026Large pre-trained models achieve remarkable success across diverse domains, yet fully fine-tuning incurs prohibitive computational and memory costs. Parameter-efficient fine-tuning (PEFT) has thus become a mainstream paradigm. Among them, Low-Rank Adaptation (LoRA) introduces trainable low-rank matrices and shows strong performance, nevertheless, its fixed-rank design limits flexibility. Dynamic rank allocation methods mitigate this issue by pruning redundant directions; however, they often rely on heuristic, element-level metrics that globally sort rank directions without matrix-wise distinction, and they lack mechanisms to expand capacity in layers requiring additional adaptation. To overcome these limitations, we propose FlexLoRA, an entropy-guided flexible low-rank adaptation framework that (i) evaluates matrix importance via spectral energy entropy, (ii) supports rank pruning and expansion under a global budget, and (iii) employs zero-impact initialization for newly added singular directions to ensure stability. By addressing granularity, flexibility, and stability limitations, FlexLoRA provides a more principled solution for PEFT. Extensive experiments show that FlexLoRA consistently outperforms state-of-the-art baselines across benchmarks. Codes are available at https://github.com/Chongjie-Si/Subspace-Tuning.
DualEdit: Dual Editing for Knowledge Updating in Vision-Language Models
Jun 16, 2025Model editing aims to efficiently update a pre-trained model's knowledge without the need for time-consuming full retraining. While existing pioneering editing methods achieve promising results, they primarily focus on editing single-modal language models (LLMs). However, for vision-language models (VLMs), which involve multiple modalities, the role and impact of each modality on editing performance remain largely unexplored. To address this gap, we explore the impact of textual and visual modalities on model editing and find that: (1) textual and visual representations reach peak sensitivity at different layers, reflecting their varying importance; and (2) editing both modalities can efficiently update knowledge, but this comes at the cost of compromising the model's original capabilities. Based on our findings, we propose DualEdit, an editor that modifies both textual and visual modalities at their respective key layers. Additionally, we introduce a gating module within the more sensitive textual modality, allowing DualEdit to efficiently update new knowledge while preserving the model's original information. We evaluate DualEdit across multiple VLM backbones and benchmark datasets, demonstrating its superiority over state-of-the-art VLM editing baselines as well as adapted LLM editing methods on different evaluation metrics.
Weight Spectra Induced Efficient Model Adaptation
May 29, 2025Large-scale foundation models have demonstrated remarkable versatility across a wide range of downstream tasks. However, fully fine-tuning these models incurs prohibitive computational costs, motivating the development of Parameter-Efficient Fine-Tuning (PEFT) methods such as LoRA, which introduces low-rank updates to pre-trained weights. Despite their empirical success, the underlying mechanisms by which PEFT modifies model parameters remain underexplored. In this work, we present a systematic investigation into the structural changes of weight matrices during fully fine-tuning. Through singular value decomposition (SVD), we reveal that fine-tuning predominantly amplifies the top singular values while leaving the remainder largely intact, suggesting that task-specific knowledge is injected into a low-dimensional subspace. Furthermore, we find that the dominant singular vectors are reoriented in task-specific directions, whereas the non-dominant subspace remains stable. Building on these insights, we propose a novel method that leverages learnable rescaling of top singular directions, enabling precise modulation of the most influential components without disrupting the global structure. Our approach achieves consistent improvements over strong baselines across multiple tasks, highlighting the efficacy of structurally informed fine-tuning.
MAP: Revisiting Weight Decomposition for Low-Rank Adaptation
May 29, 2025
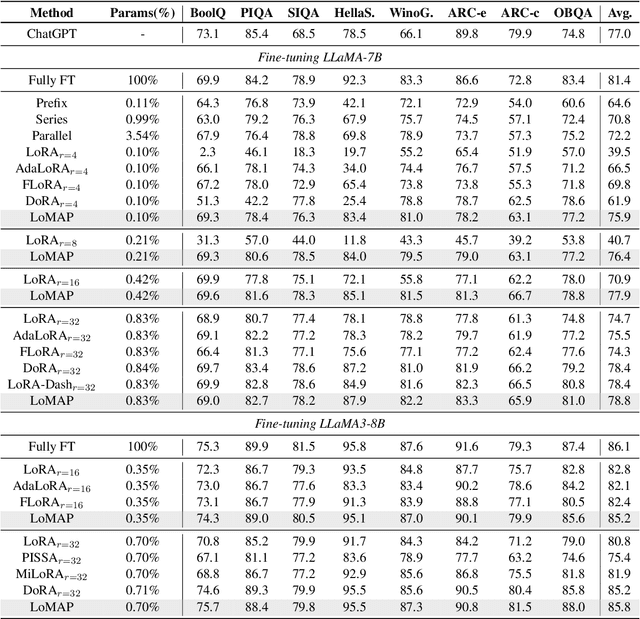
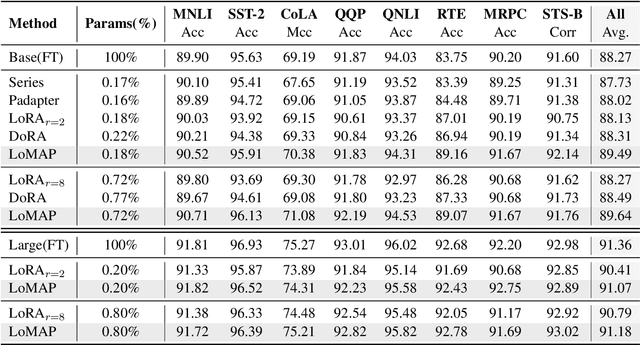

The rapid development of large language models has revolutionized natural language processing, but their fine-tuning remains computationally expensive, hindering broad deployment. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, have emerged as solutions. Recent work like DoRA attempts to further decompose weight adaptation into direction and magnitude components. However, existing formulations often define direction heuristically at the column level, lacking a principled geometric foundation. In this paper, we propose MAP, a novel framework that reformulates weight matrices as high-dimensional vectors and decouples their adaptation into direction and magnitude in a rigorous manner. MAP normalizes the pre-trained weights, learns a directional update, and introduces two scalar coefficients to independently scale the magnitude of the base and update vectors. This design enables more interpretable and flexible adaptation, and can be seamlessly integrated into existing PEFT methods. Extensive experiments show that MAP significantly improves performance when coupling with existing methods, offering a simple yet powerful enhancement to existing PEFT methods. Given the universality and simplicity of MAP, we hope it can serve as a default setting for designing future PEFT methods.
Revisiting Sparsity Constraint Under High-Rank Property in Partial Multi-Label Learning
May 27, 2025



Partial Multi-Label Learning (PML) extends the multi-label learning paradigm to scenarios where each sample is associated with a candidate label set containing both ground-truth labels and noisy labels. Existing PML methods commonly rely on two assumptions: sparsity of the noise label matrix and low-rankness of the ground-truth label matrix. However, these assumptions are inherently conflicting and impractical for real-world scenarios, where the true label matrix is typically full-rank or close to full-rank. To address these limitations, we demonstrate that the sparsity constraint contributes to the high-rank property of the predicted label matrix. Based on this, we propose a novel method Schirn, which introduces a sparsity constraint on the noise label matrix while enforcing a high-rank property on the predicted label matrix. Extensive experiments demonstrate the superior performance of Schirn compared to state-of-the-art methods, validating its effectiveness in tackling real-world PML challenges.
Co-Reinforcement Learning for Unified Multimodal Understanding and Generation
May 23, 2025This paper presents a pioneering exploration of reinforcement learning (RL) via group relative policy optimization for unified multimodal large language models (ULMs), aimed at simultaneously reinforcing generation and understanding capabilities. Through systematic pilot studies, we uncover the significant potential of ULMs to enable the synergistic co-evolution of dual capabilities within a shared policy optimization framework. Building on this insight, we introduce \textbf{CoRL}, a co-reinforcement learning framework comprising a unified RL stage for joint optimization and a refined RL stage for task-specific enhancement. With the proposed CoRL, our resulting model, \textbf{ULM-R1}, achieves average improvements of \textbf{7%} on three text-to-image generation datasets and \textbf{23%} on nine multimodal understanding benchmarks. These results demonstrate the effectiveness of CoRL and highlight the substantial benefit of reinforcement learning in facilitating cross-task synergy and optimization for ULMs.
Why Can Accurate Models Be Learned from Inaccurate Annotations?
May 22, 2025



Learning from inaccurate annotations has gained significant attention due to the high cost of precise labeling. However, despite the presence of erroneous labels, models trained on noisy data often retain the ability to make accurate predictions. This intriguing phenomenon raises a fundamental yet largely unexplored question: why models can still extract correct label information from inaccurate annotations remains unexplored. In this paper, we conduct a comprehensive investigation into this issue. By analyzing weight matrices from both empirical and theoretical perspectives, we find that label inaccuracy primarily accumulates noise in lower singular components and subtly perturbs the principal subspace. Within a certain range, the principal subspaces of weights trained on inaccurate labels remain largely aligned with those learned from clean labels, preserving essential task-relevant information. We formally prove that the angles of principal subspaces exhibit minimal deviation under moderate label inaccuracy, explaining why models can still generalize effectively. Building on these insights, we propose LIP, a lightweight plug-in designed to help classifiers retain principal subspace information while mitigating noise induced by label inaccuracy. Extensive experiments on tasks with various inaccuracy conditions demonstrate that LIP consistently enhances the performance of existing algorithms. We hope our findings can offer valuable theoretical and practical insights to understand of model robustness under inaccurate supervision.
NAN: A Training-Free Solution to Coefficient Estimation in Model Merging
May 22, 2025Model merging offers a training-free alternative to multi-task learning by combining independently fine-tuned models into a unified one without access to raw data. However, existing approaches often rely on heuristics to determine the merging coefficients, limiting their scalability and generality. In this work, we revisit model merging through the lens of least-squares optimization and show that the optimal merging weights should scale with the amount of task-specific information encoded in each model. Based on this insight, we propose NAN, a simple yet effective method that estimates model merging coefficients via the inverse of parameter norm. NAN is training-free, plug-and-play, and applicable to a wide range of merging strategies. Extensive experiments on show that NAN consistently improves performance of baseline methods.
Generalized Tensor-based Parameter-Efficient Fine-Tuning via Lie Group Transformations
Apr 01, 2025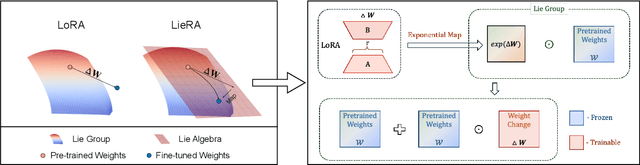
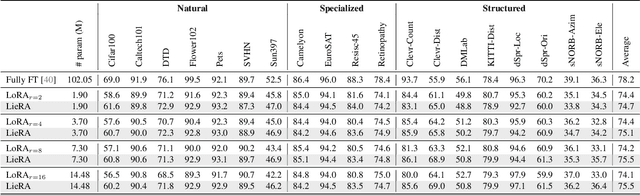
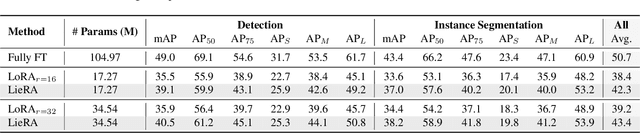

Adapting pre-trained foundation models for diverse downstream tasks is a core practice in artificial intelligence. However, the wide range of tasks and high computational costs make full fine-tuning impractical. To overcome this, parameter-efficient fine-tuning (PEFT) methods like LoRA have emerged and are becoming a growing research focus. Despite the success of these methods, they are primarily designed for linear layers, focusing on two-dimensional matrices while largely ignoring higher-dimensional parameter spaces like convolutional kernels. Moreover, directly applying these methods to higher-dimensional parameter spaces often disrupts their structural relationships. Given the rapid advancements in matrix-based PEFT methods, rather than designing a specialized strategy, we propose a generalization that extends matrix-based PEFT methods to higher-dimensional parameter spaces without compromising their structural properties. Specifically, we treat parameters as elements of a Lie group, with updates modeled as perturbations in the corresponding Lie algebra. These perturbations are mapped back to the Lie group through the exponential map, ensuring smooth, consistent updates that preserve the inherent structure of the parameter space. Extensive experiments on computer vision and natural language processing validate the effectiveness and versatility of our approach, demonstrating clear improvements over existing methods.
Unveiling the Mystery of Weight in Large Foundation Models: Gaussian Distribution Never Fades
Jan 18, 2025



This paper presents a pioneering exploration of the mechanisms underlying large foundation models' (LFMs) weights, aiming to simplify AI research. Through extensive observation and analysis on prevailing LFMs, we find that regardless of initialization strategies, their weights predominantly follow a Gaussian distribution, with occasional sharp, inverted T-shaped, or linear patterns. We further discover that the weights share the i.i.d. properties of Gaussian noise, and explore their direct relationship. We find that transformation weights can be derived from Gaussian noise, and they primarily serve to increase the standard deviation of pre-trained weights, with their standard deviation growing with layer depth. In other words, transformation weights broaden the acceptable deviation from the optimal weights, facilitating adaptation to downstream tasks. Building upon the above conclusions, we thoroughly discussed the nature of optimal weights, ultimately concluding that they should exhibit zero-mean, symmetry, and sparsity, with the sparse values being a truncated Gaussian distribution and a few outliers. Our experiments in LFM adaptation and editing demonstrate the effectiveness of these insights. We hope these findings can provide a foundational understanding to pave the way for future advancements in the LFM community.