 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
Jun 01, 2026Search agents are often trained as policies over growing transcripts: the model must decide how to search while also remembering what it has seen, which evidence is useful, which constraints remain open, and which claims have actually been checked. We argue that this formulation puts too much routine state management inside the policy: reinforcement learning is forced to optimize both semantic search decisions and recoverable bookkeeping that the environment can maintain more reliably. We introduce Harness-1, a 20B search agent (retrieval subagent) trained with reinforcement learning inside a stateful search harness. The harness maintains environment-side working memory, including a candidate pool, an importance-tagged curated set, compact evidence links, verification records, compressed and deduplicated observations, and budget-aware context rendering. The policy retains the semantic decisions: what to search, which documents to keep or discard, what to verify, and when to stop. Across eight retrieval benchmarks spanning web, finance, patents, and multi-hop QA, Harness-1 achieves 0.730 average curated recall, outperforming the next strongest open search subagent by +11.4 points and remaining competitive with much larger frontier-model searchers. Its gains are especially strong on held-out transfer benchmarks, suggesting that reinforcement learning over explicit search state can produce retrieval behaviors that generalize beyond the training domains. Our code is available at https://github.com/pat-jj/harness-1.
Retrieval is Cheap, Show Me the Code: Executable Multi-Hop Reasoning for Retrieval-Augmented Generation
May 13, 2026Retrieval-Augmented Generation (RAG) has become a standard approach for knowledge-intensive question answering, but existing systems remain brittle on multi-hop questions, where solving the task requires chaining multiple retrieval and reasoning steps. Key challenges are that current methods represent reasoning through free-form natural language, where intermediate states are implicit, retrieval queries can drift from intended entities, and errors are detected by the same model that produces them making self-reflection an unreliable, ungrounded signal. We observe that multi-hop question answering is a typical form of step-by-step computation, and that this structured process aligns closely with how code-specialized language models are trained to operate. Motivated by this, we introduce \pyrag, a framework that reformulates multi-hop RAG as program synthesis and execution. Instead of free-form reasoning trajectories, \pyrag represents the reasoning process as an executable Python program over retrieval and QA tools, exposing intermediate states as variables, producing deterministic feedback through execution, and yielding an inspectable trace of the entire reasoning process. This formulation further enables compiler-grounded self-repair and execution-driven adaptive retrieval without any additional training. Experiments on five QA benchmarks (PopQA, HotpotQA, 2WikiMultihopQA, MuSiQue, and Bamboogle) show that \pyrag consistently outperforms strong baselines under both training-free and RL-trained settings, with especially large gains on compositional multi-hop datasets. Our code, data and models are publicly available at https://github.com/GasolSun36/PyRAG.
Learning to Predict Future-Aligned Research Proposals with Language Models
Mar 28, 2026Large language models (LLMs) are increasingly used to assist ideation in research, but evaluating the quality of LLM-generated research proposals remains difficult: novelty and soundness are hard to measure automatically, and large-scale human evaluation is costly. We propose a verifiable alternative by reframing proposal generation as a time-sliced scientific forecasting problem. Given a research question and inspiring papers available before a cutoff time, the model generates a structured proposal and is evaluated by whether it anticipates research directions that appear in papers published after the time. We operationalize this objective with the Future Alignment Score (FAS), computed via retrieval and LLM-based semantic scoring against a held-out future corpus. To train models, we build a time-consistent dataset of 17,771 papers from targets and their pre-cutoff citations, and synthesize reasoning traces that teach gap identification and inspiration borrowing. Across Llama-3.1 and Qwen2.5 models, future-aligned tuning improves future alignment over unaligned baselines (up to +10.6% overall FAS), and domain-expert human evaluation corroborates improved proposal quality. Finally, we demonstrate practical impact by implementing two model-generated proposals with a code agent, obtaining 4.17% accuracy gain on MATH from a new prompting strategy and consistent improvements for a novel model-merging method.
Adaptation of Agentic AI
Dec 22, 2025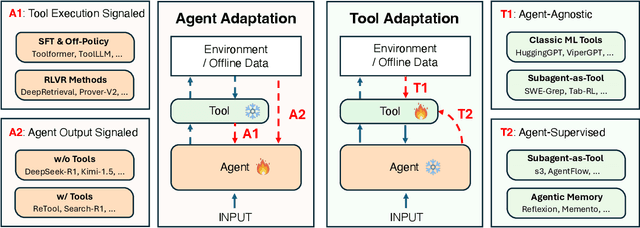
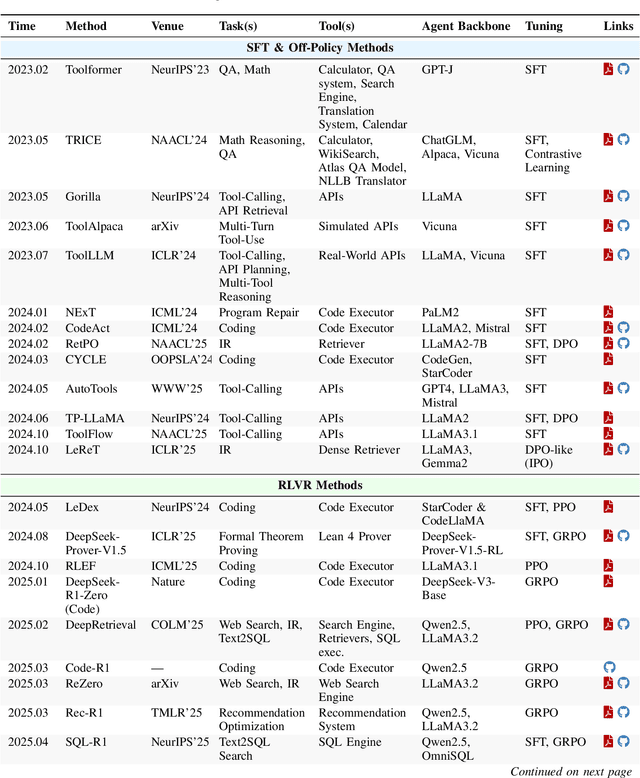
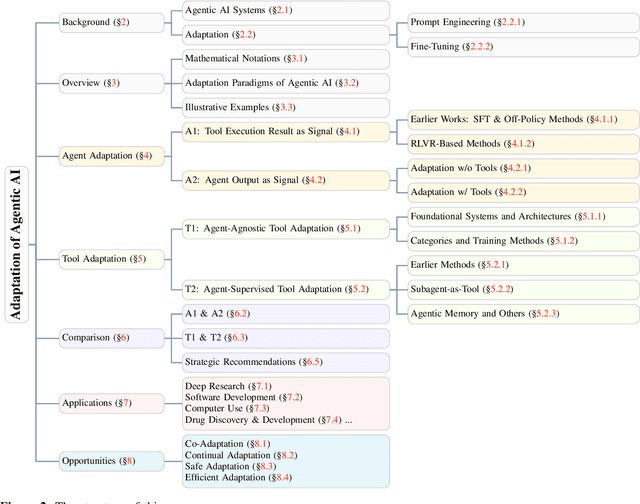
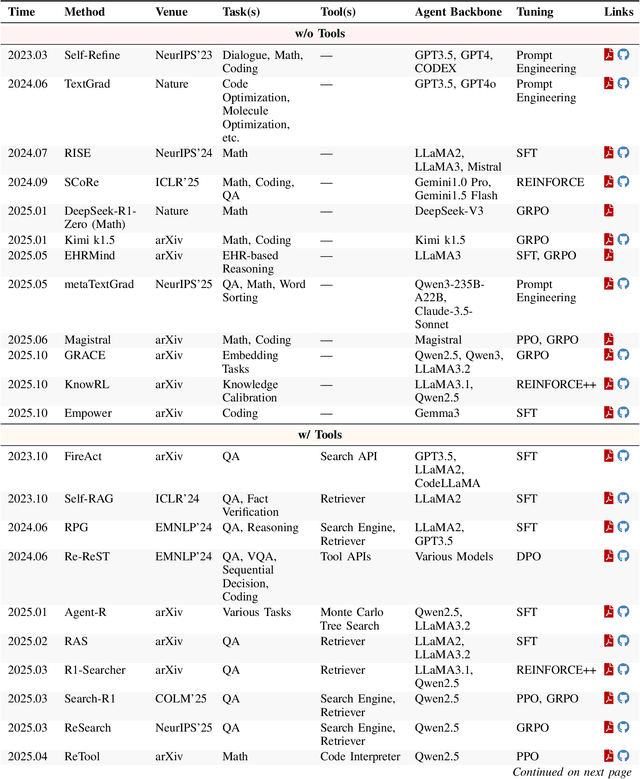
Cutting-edge agentic AI systems are built on foundation models that can be adapted to plan, reason, and interact with external tools to perform increasingly complex and specialized tasks. As these systems grow in capability and scope, adaptation becomes a central mechanism for improving performance, reliability, and generalization. In this paper, we unify the rapidly expanding research landscape into a systematic framework that spans both agent adaptations and tool adaptations. We further decompose these into tool-execution-signaled and agent-output-signaled forms of agent adaptation, as well as agent-agnostic and agent-supervised forms of tool adaptation. We demonstrate that this framework helps clarify the design space of adaptation strategies in agentic AI, makes their trade-offs explicit, and provides practical guidance for selecting or switching among strategies during system design. We then review the representative approaches in each category, analyze their strengths and limitations, and highlight key open challenges and future opportunities. Overall, this paper aims to offer a conceptual foundation and practical roadmap for researchers and practitioners seeking to build more capable, efficient, and reliable agentic AI systems.
Virtual Multiplex Staining for Histological Images using a Marker-wise Conditioned Diffusion Model
Aug 20, 2025Multiplex imaging is revolutionizing pathology by enabling the simultaneous visualization of multiple biomarkers within tissue samples, providing molecular-level insights that traditional hematoxylin and eosin (H&E) staining cannot provide. However, the complexity and cost of multiplex data acquisition have hindered its widespread adoption. Additionally, most existing large repositories of H&E images lack corresponding multiplex images, limiting opportunities for multimodal analysis. To address these challenges, we leverage recent advances in latent diffusion models (LDMs), which excel at modeling complex data distributions utilizing their powerful priors for fine-tuning to a target domain. In this paper, we introduce a novel framework for virtual multiplex staining that utilizes pretrained LDM parameters to generate multiplex images from H&E images using a conditional diffusion model. Our approach enables marker-by-marker generation by conditioning the diffusion model on each marker, while sharing the same architecture across all markers. To tackle the challenge of varying pixel value distributions across different marker stains and to improve inference speed, we fine-tune the model for single-step sampling, enhancing both color contrast fidelity and inference efficiency through pixel-level loss functions. We validate our framework on two publicly available datasets, notably demonstrating its effectiveness in generating up to 18 different marker types with improved accuracy, a substantial increase over the 2-3 marker types achieved in previous approaches. This validation highlights the potential of our framework, pioneering virtual multiplex staining. Finally, this paper bridges the gap between H&E and multiplex imaging, potentially enabling retrospective studies and large-scale analyses of existing H&E image repositories.
DualEdit: Dual Editing for Knowledge Updating in Vision-Language Models
Jun 16, 2025Model editing aims to efficiently update a pre-trained model's knowledge without the need for time-consuming full retraining. While existing pioneering editing methods achieve promising results, they primarily focus on editing single-modal language models (LLMs). However, for vision-language models (VLMs), which involve multiple modalities, the role and impact of each modality on editing performance remain largely unexplored. To address this gap, we explore the impact of textual and visual modalities on model editing and find that: (1) textual and visual representations reach peak sensitivity at different layers, reflecting their varying importance; and (2) editing both modalities can efficiently update knowledge, but this comes at the cost of compromising the model's original capabilities. Based on our findings, we propose DualEdit, an editor that modifies both textual and visual modalities at their respective key layers. Additionally, we introduce a gating module within the more sensitive textual modality, allowing DualEdit to efficiently update new knowledge while preserving the model's original information. We evaluate DualEdit across multiple VLM backbones and benchmark datasets, demonstrating its superiority over state-of-the-art VLM editing baselines as well as adapted LLM editing methods on different evaluation metrics.
MAP: Revisiting Weight Decomposition for Low-Rank Adaptation
May 29, 2025
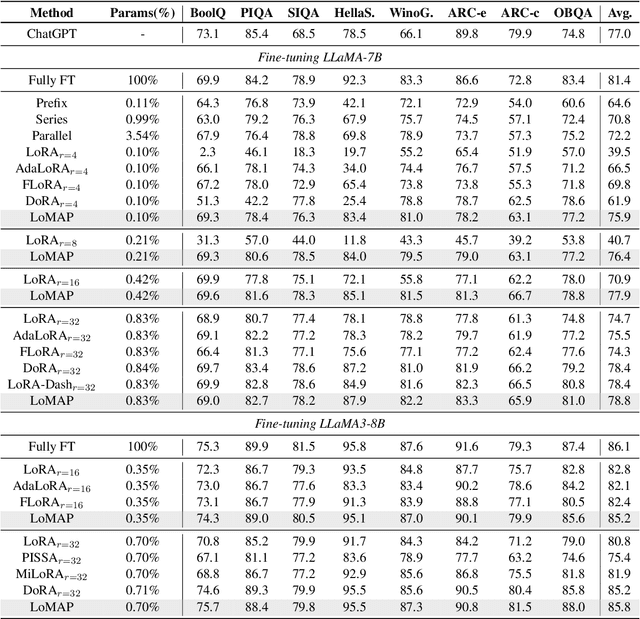
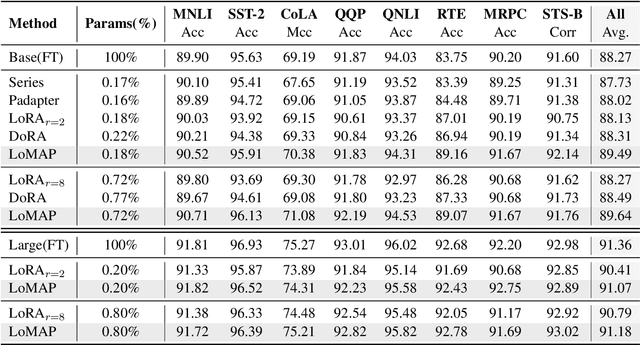

The rapid development of large language models has revolutionized natural language processing, but their fine-tuning remains computationally expensive, hindering broad deployment. Parameter-efficient fine-tuning (PEFT) methods, such as LoRA, have emerged as solutions. Recent work like DoRA attempts to further decompose weight adaptation into direction and magnitude components. However, existing formulations often define direction heuristically at the column level, lacking a principled geometric foundation. In this paper, we propose MAP, a novel framework that reformulates weight matrices as high-dimensional vectors and decouples their adaptation into direction and magnitude in a rigorous manner. MAP normalizes the pre-trained weights, learns a directional update, and introduces two scalar coefficients to independently scale the magnitude of the base and update vectors. This design enables more interpretable and flexible adaptation, and can be seamlessly integrated into existing PEFT methods. Extensive experiments show that MAP significantly improves performance when coupling with existing methods, offering a simple yet powerful enhancement to existing PEFT methods. Given the universality and simplicity of MAP, we hope it can serve as a default setting for designing future PEFT methods.
Generalized Tensor-based Parameter-Efficient Fine-Tuning via Lie Group Transformations
Apr 01, 2025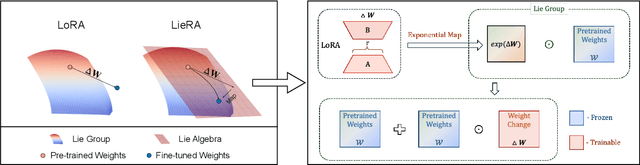
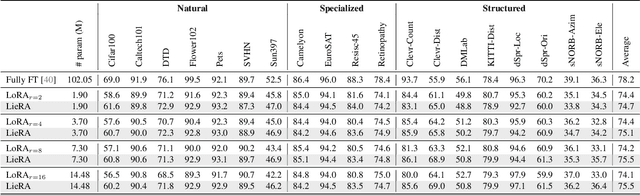
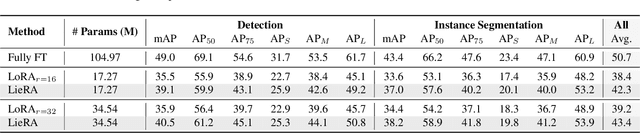

Adapting pre-trained foundation models for diverse downstream tasks is a core practice in artificial intelligence. However, the wide range of tasks and high computational costs make full fine-tuning impractical. To overcome this, parameter-efficient fine-tuning (PEFT) methods like LoRA have emerged and are becoming a growing research focus. Despite the success of these methods, they are primarily designed for linear layers, focusing on two-dimensional matrices while largely ignoring higher-dimensional parameter spaces like convolutional kernels. Moreover, directly applying these methods to higher-dimensional parameter spaces often disrupts their structural relationships. Given the rapid advancements in matrix-based PEFT methods, rather than designing a specialized strategy, we propose a generalization that extends matrix-based PEFT methods to higher-dimensional parameter spaces without compromising their structural properties. Specifically, we treat parameters as elements of a Lie group, with updates modeled as perturbations in the corresponding Lie algebra. These perturbations are mapped back to the Lie group through the exponential map, ensuring smooth, consistent updates that preserve the inherent structure of the parameter space. Extensive experiments on computer vision and natural language processing validate the effectiveness and versatility of our approach, demonstrating clear improvements over existing methods.
Multimodal Learning for Embryo Viability Prediction in Clinical IVF
Oct 21, 2024In clinical In-Vitro Fertilization (IVF), identifying the most viable embryo for transfer is important to increasing the likelihood of a successful pregnancy. Traditionally, this process involves embryologists manually assessing embryos' static morphological features at specific intervals using light microscopy. This manual evaluation is not only time-intensive and costly, due to the need for expert analysis, but also inherently subjective, leading to variability in the selection process. To address these challenges, we develop a multimodal model that leverages both time-lapse video data and Electronic Health Records (EHRs) to predict embryo viability. One of the primary challenges of our research is to effectively combine time-lapse video and EHR data, owing to their inherent differences in modality. We comprehensively analyze our multimodal model with various modality inputs and integration approaches. Our approach will enable fast and automated embryo viability predictions in scale for clinical IVF.
Unleashing the Power of Task-Specific Directions in Parameter Efficient Fine-tuning
Sep 02, 2024



Large language models demonstrate impressive performance on downstream tasks, yet requiring extensive resource consumption when fully fine-tuning all parameters. To mitigate this, Parameter Efficient Fine-Tuning (PEFT) strategies, such as LoRA, have been developed. In this paper, we delve into the concept of task-specific directions--critical for transitioning large models from pre-trained states to task-specific enhancements in PEFT. We propose a framework to clearly define these directions and explore their properties, and practical utilization challenges. We then introduce a novel approach, LoRA-Dash, which aims to maximize the impact of task-specific directions during the fine-tuning process, thereby enhancing model performance on targeted tasks. Extensive experiments have conclusively demonstrated the effectiveness of LoRA-Dash, and in-depth analyses further reveal the underlying mechanisms of LoRA-Dash. The code is available at https://github.com/Chongjie-Si/Subspace-Tuning.