 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvian: Towards Explainable Visual Instruction-tuning Data Auditing
Apr 22, 2026The efficacy of Large Vision-Language Models (LVLMs) is critically dependent on the quality of their training data, requiring a precise balance between visual fidelity and instruction-following capability. Existing datasets, however, are plagued by inconsistent quality, and current data filtering methods rely on coarse-grained scores that lack the granularity to identify nuanced semantic flaws like logical fallacies or factual errors. This creates a fundamental bottleneck in developing more reliable models. To address this, we make three core contributions. First, we construct a large-scale, 300K-sample benchmark by systematically injecting diverse, subtle defects to provide a challenging testbed for data auditing. Second, we introduce a novel "Decomposition-then-Evaluation" paradigm that breaks model responses into constituent cognitive components: visual description, subjective inference, and factual claim, enabling targeted analysis. Third, we instantiate this paradigm via EVIAN (Explainable Visual Instruction-tuning Data AuditiNg), an automated framework that evaluates these components along the orthogonal axes of Image-Text Consistency, Logical Coherence, and Factual Accuracy. Our empirical findings challenge the prevailing scale-centric paradigm: a model fine-tuned on a compact, high-quality subset curated by EVIAN consistently surpassed models trained on orders-of-magnitude larger datasets. We also reveal that dividing complex auditing into verifiable subtasks enables robust curation, and that Logical Coherence is the most critical factor in data quality evaluation.
VP-Bench: A Comprehensive Benchmark for Visual Prompting in Multimodal Large Language Models
Nov 14, 2025Multimodal large language models (MLLMs) have enabled a wide range of advanced vision-language applications, including fine-grained object recognition and contextual understanding. When querying specific regions or objects in an image, human users naturally use "visual prompts" (VPs), such as bounding boxes, to provide reference. However, no existing benchmark systematically evaluates the ability of MLLMs to interpret such VPs. This gap leaves it unclear whether current MLLMs can effectively recognize VPs, an intuitive prompting method for humans, and use them to solve problems. To address this limitation, we introduce VP-Bench, a benchmark for assessing MLLMs' capability in VP perception and utilization. VP-Bench employs a two-stage evaluation framework: Stage 1 examines models' ability to perceive VPs in natural scenes, using 30k visualized prompts spanning eight shapes and 355 attribute combinations. Stage 2 investigates the impact of VPs on downstream tasks, measuring their effectiveness in real-world problem-solving scenarios. Using VP-Bench, we evaluate 28 MLLMs, including proprietary systems (e.g., GPT-4o) and open-source models (e.g., InternVL3 and Qwen2.5-VL), and provide a comprehensive analysis of factors that affect VP understanding, such as variations in VP attributes, question arrangement, and model scale. VP-Bench establishes a new reference framework for studying how MLLMs comprehend and resolve grounded referring questions.
Better Reasoning with Less Data: Enhancing VLMs Through Unified Modality Scoring
Jun 10, 2025

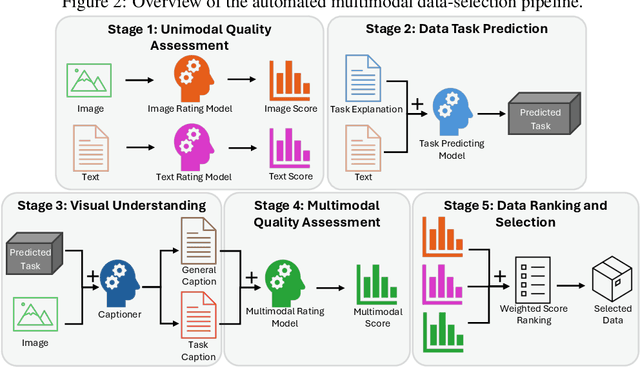

The application of visual instruction tuning and other post-training techniques has significantly enhanced the capabilities of Large Language Models (LLMs) in visual understanding, enriching Vision-Language Models (VLMs) with more comprehensive visual language datasets. However, the effectiveness of VLMs is highly dependent on large-scale, high-quality datasets that ensure precise recognition and accurate reasoning. Two key challenges hinder progress: (1) noisy alignments between images and the corresponding text, which leads to misinterpretation, and (2) ambiguous or misleading text, which obscures visual content. To address these challenges, we propose SCALE (Single modality data quality and Cross modality Alignment Evaluation), a novel quality-driven data selection pipeline for VLM instruction tuning datasets. Specifically, SCALE integrates a cross-modality assessment framework that first assigns each data entry to its appropriate vision-language task, generates general and task-specific captions (covering scenes, objects, style, etc.), and evaluates the alignment, clarity, task rarity, text coherence, and image clarity of each entry based on the generated captions. We reveal that: (1) current unimodal quality assessment methods evaluate one modality while overlooking the rest, which can underestimate samples essential for specific tasks and discard the lower-quality instances that help build model robustness; and (2) appropriately generated image captions provide an efficient way to transfer the image-text multimodal task into a unified text modality.
ICM-Assistant: Instruction-tuning Multimodal Large Language Models for Rule-based Explainable Image Content Moderation
Dec 24, 2024



Controversial contents largely inundate the Internet, infringing various cultural norms and child protection standards. Traditional Image Content Moderation (ICM) models fall short in producing precise moderation decisions for diverse standards, while recent multimodal large language models (MLLMs), when adopted to general rule-based ICM, often produce classification and explanation results that are inconsistent with human moderators. Aiming at flexible, explainable, and accurate ICM, we design a novel rule-based dataset generation pipeline, decomposing concise human-defined rules and leveraging well-designed multi-stage prompts to enrich short explicit image annotations. Our ICM-Instruct dataset includes detailed moderation explanation and moderation Q-A pairs. Built upon it, we create our ICM-Assistant model in the framework of rule-based ICM, making it readily applicable in real practice. Our ICM-Assistant model demonstrates exceptional performance and flexibility. Specifically, it significantly outperforms existing approaches on various sources, improving both the moderation classification (36.8\% on average) and moderation explanation quality (26.6\% on average) consistently over existing MLLMs. Code/Data is available at https://github.com/zhaoyuzhi/ICM-Assistant.
LLaVA-SpaceSGG: Visual Instruct Tuning for Open-vocabulary Scene Graph Generation with Enhanced Spatial Relations
Dec 09, 2024



Scene Graph Generation (SGG) converts visual scenes into structured graph representations, providing deeper scene understanding for complex vision tasks. However, existing SGG models often overlook essential spatial relationships and struggle with generalization in open-vocabulary contexts. To address these limitations, we propose LLaVA-SpaceSGG, a multimodal large language model (MLLM) designed for open-vocabulary SGG with enhanced spatial relation modeling. To train it, we collect the SGG instruction-tuning dataset, named SpaceSGG. This dataset is constructed by combining publicly available datasets and synthesizing data using open-source models within our data construction pipeline. It combines object locations, object relations, and depth information, resulting in three data formats: spatial SGG description, question-answering, and conversation. To enhance the transfer of MLLMs' inherent capabilities to the SGG task, we introduce a two-stage training paradigm. Experiments show that LLaVA-SpaceSGG outperforms other open-vocabulary SGG methods, boosting recall by 8.6% and mean recall by 28.4% compared to the baseline. Our codebase, dataset, and trained models are publicly accessible on GitHub at the following URL: https://github.com/Endlinc/LLaVA-SpaceSGG.
Jitter Does Matter: Adapting Gaze Estimation to New Domains
Oct 05, 2022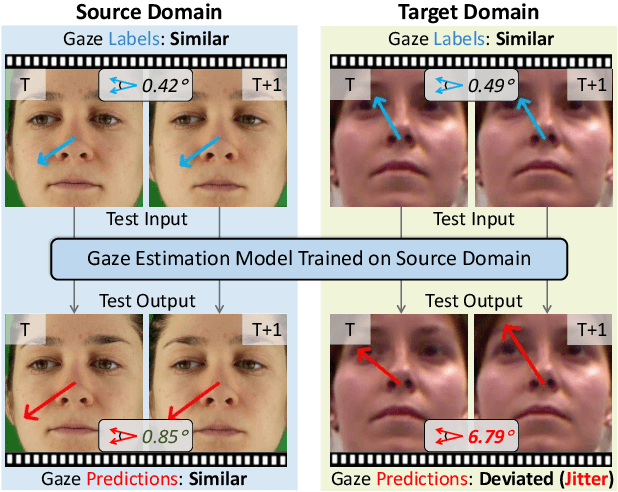
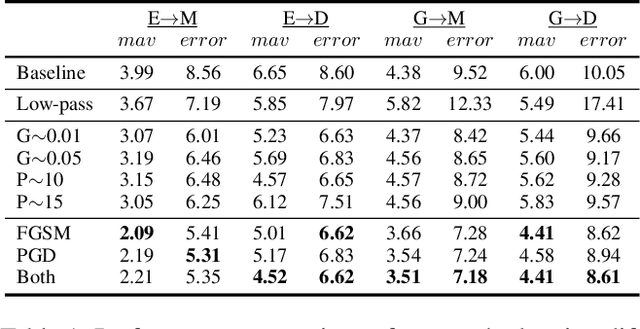
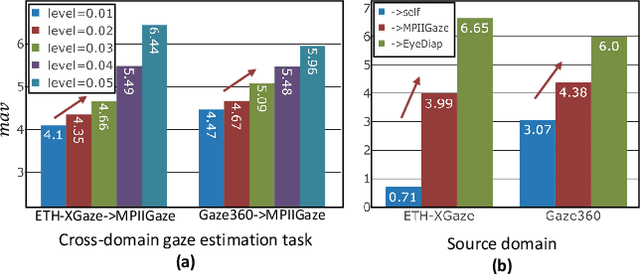
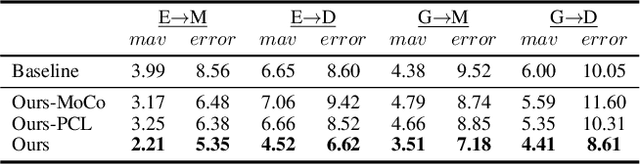
Deep neural networks have demonstrated superior performance on appearance-based gaze estimation tasks. However, due to variations in person, illuminations, and background, performance degrades dramatically when applying the model to a new domain. In this paper, we discover an interesting gaze jitter phenomenon in cross-domain gaze estimation, i.e., the gaze predictions of two similar images can be severely deviated in target domain. This is closely related to cross-domain gaze estimation tasks, but surprisingly, it has not been noticed yet previously. Therefore, we innovatively propose to utilize the gaze jitter to analyze and optimize the gaze domain adaptation task. We find that the high-frequency component (HFC) is an important factor that leads to jitter. Based on this discovery, we add high-frequency components to input images using the adversarial attack and employ contrastive learning to encourage the model to obtain similar representations between original and perturbed data, which reduces the impacts of HFC. We evaluate the proposed method on four cross-domain gaze estimation tasks, and experimental results demonstrate that it significantly reduces the gaze jitter and improves the gaze estimation performance in target domains.
Vulnerability of Appearance-based Gaze Estimation
Mar 24, 2021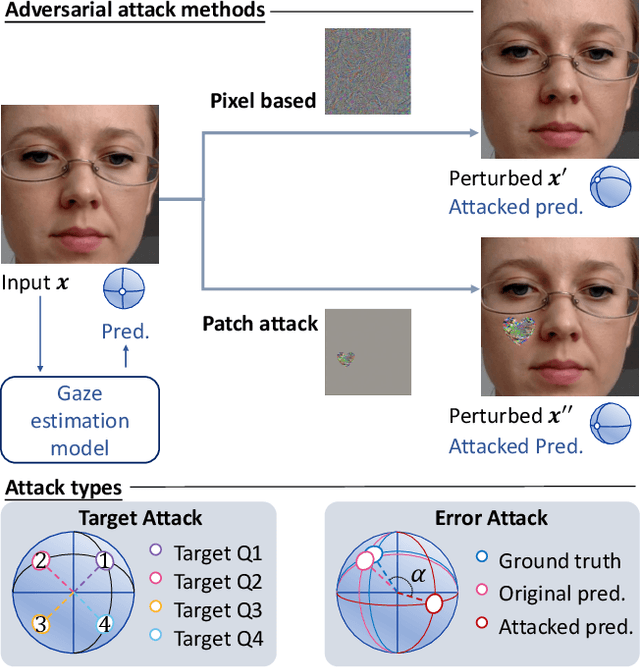
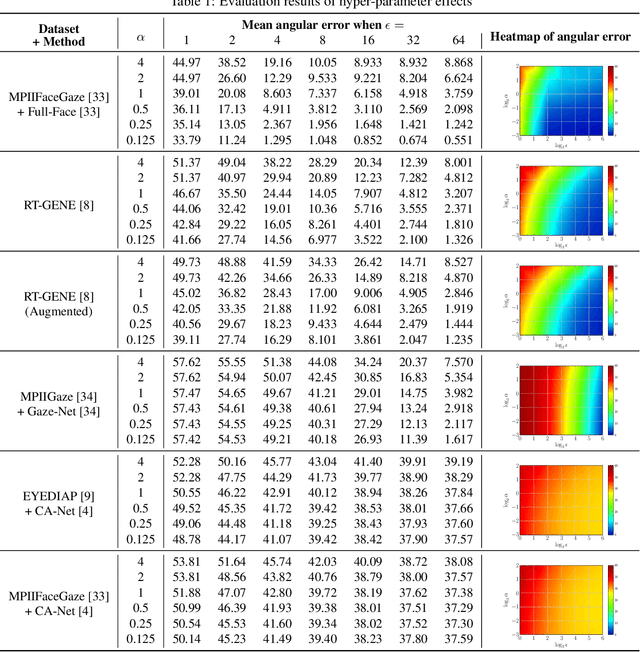
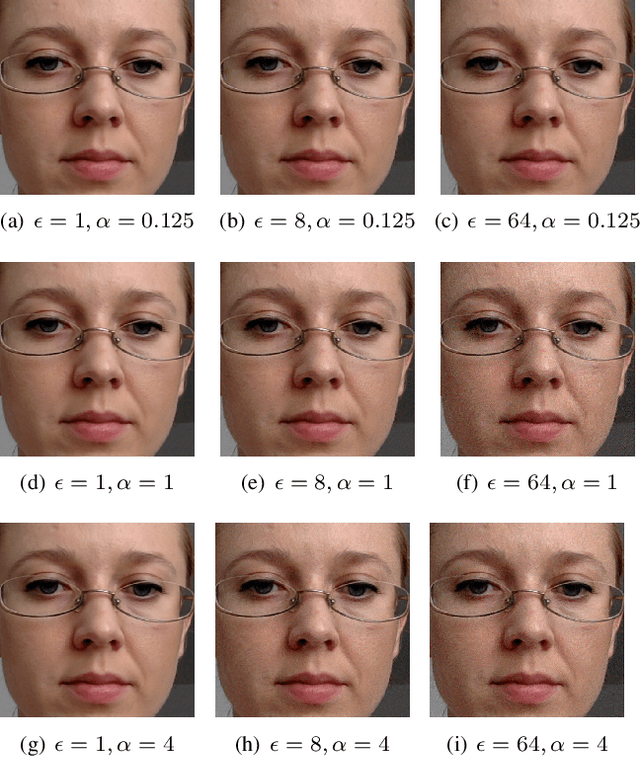
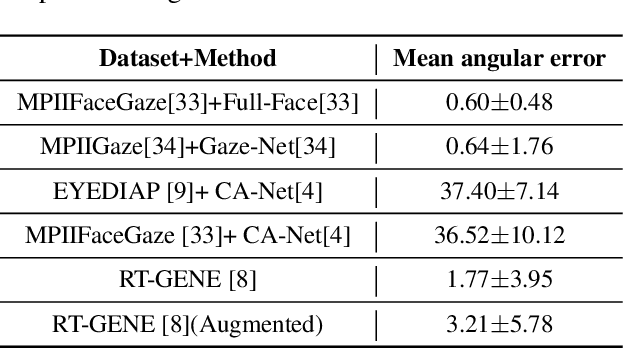
Appearance-based gaze estimation has achieved significant improvement by using deep learning. However, many deep learning-based methods suffer from the vulnerability property, i.e., perturbing the raw image using noise confuses the gaze estimation models. Although the perturbed image visually looks similar to the original image, the gaze estimation models output the wrong gaze direction. In this paper, we investigate the vulnerability of appearance-based gaze estimation. To our knowledge, this is the first time that the vulnerability of gaze estimation to be found. We systematically characterized the vulnerability property from multiple aspects, the pixel-based adversarial attack, the patch-based adversarial attack and the defense strategy. Our experimental results demonstrate that the CA-Net shows superior performance against attack among the four popular appearance-based gaze estimation networks, Full-Face, Gaze-Net, CA-Net and RT-GENE. This study draws the attention of researchers in the appearance-based gaze estimation community to defense from adversarial attacks.