 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Quantization-Aware Training: Gradients at Quantized Weights Bias to the Low-Loss Basin
Jun 08, 2026Post-training quantization (PTQ) converts a trained full-precision model into low-bit weights without task-level retraining, while quantization-aware training (QAT) incorporates quantization into the training loop. Although PTQ is efficient and often accurate at moderate bitwidths, it can fail sharply at aggressive bitwidths; QAT is more expensive but can often recover the lost accuracy. We propose a unified geometric framework that explains both PTQ failure and QAT recovery. We model full-precision training as following a low-loss \emph{river} inside a wider \emph{valley}: a normal neighborhood of the river forms a nearly flat \emph{basin}, while leaving this basin incurs a sharp loss increase. When the quantization grid is comparable to the basin width, local PTQ objectives, including rounding and Hessian-based second-order reconstruction, can select a high-loss deployed quantized point outside the basin even when nearby low-loss quantized points exist. In this regime, straight-through-estimator-based QAT has a useful bias: it evaluates gradients at the deployed quantized weights while updating latent full-precision weights, causing the gradient to sense the valley wall and acquire an inward component that steers subsequent quantized iterates back into the basin. We formalize this mechanism through a local landscape model, construct a geometric PTQ failure mode, and prove finite-time QAT recovery under local quantizer-compatibility assumptions. Experiments across vision and language models under multiple neural-network quantization schemes corroborate the predicted basin-crossing failure of PTQ and the corresponding recovery mechanism of QAT.
Learning Interpretable Point-Based Clinical Risk Scores via Direct Optimization
May 18, 2026Many clinical risk scores are deployed as additive rules with nonnegative integer points assigned to relevant binary predictive features. These integer weights not only make the score easier to use in practice but also promote sparsity in the resulting prediction model. Such risk scores are often derived by first fitting a regression model and then rounding the estimated coefficients to the nearest integer after appropriate scaling. This approach is computationally fast but does not guarantee optimality of the resulting score. Alternatively, one may search over all possible integer weights to directly optimize a value function by posing the problem as an integer programming task. However, the associated computational burden can be substantial, especially when the value function is nonconcave or even discontinuous. In this paper, we develop new machine learning algorithms that employ a flexible greedy optimization strategy to learn such additive scoring directly under explicit and sensible optimality objectives. We apply the proposed method to a large electronic health record (EHR) cohort in Epic Cosmos to construct an integer-weighted comorbidity score for measuring the risk of post-discharge mortality. We also conduct a simulation study to examine the finite-sample operating characteristics.
GeoMotion: Rethinking Motion Segmentation via Latent 4D Geometry
Feb 25, 2026Motion segmentation in dynamic scenes is highly challenging, as conventional methods heavily rely on estimating camera poses and point correspondences from inherently noisy motion cues. Existing statistical inference or iterative optimization techniques that struggle to mitigate the cumulative errors in multi-stage pipelines often lead to limited performance or high computational cost. In contrast, we propose a fully learning-based approach that directly infers moving objects from latent feature representations via attention mechanisms, thus enabling end-to-end feed-forward motion segmentation. Our key insight is to bypass explicit correspondence estimation and instead let the model learn to implicitly disentangle object and camera motion. Supported by recent advances in 4D scene geometry reconstruction (e.g., $π^3$), the proposed method leverages reliable camera poses and rich spatial-temporal priors, which ensure stable training and robust inference for the model. Extensive experiments demonstrate that by eliminating complex pre-processing and iterative refinement, our approach achieves state-of-the-art motion segmentation performance with high efficiency. The code is available at:https://github.com/zjutcvg/GeoMotion.
COMETS: Coordinated Multi-Destination Video Transmission with In-Network Rate Adaptation
Jan 26, 2026Large-scale video streaming events attract millions of simultaneous viewers, stressing existing delivery infrastructures. Client-driven adaptation reacts slowly to shared congestion, while server-based coordination introduces scalability bottlenecks and single points of failure. We present COMETS, a coordinated multi-destination video transmission framework that leverages information-centric networking principles such as request aggregation and in-network state awareness to enable scalable, fair, and adaptive rate control. COMETS introduces a novel range-interest protocol and distributed in-network decision process that aligns video quality across receiver groups while minimizing redundant transmissions. To achieve this, we develop a lightweight distributed optimization framework that guides per-hop quality adaptation without centralized control. Extensive emulation shows that COMETS consistently improves bandwidth utilization, fairness, and user-perceived quality of experience over DASH, MoQ, and ICN baselines, particularly under high concurrency. The results highlight COMETS as a practical, deployable approach for next-generation scalable video delivery.
* Accepted to appear in IEEE Transactions on Multimedia (2026)
Multiscale Cross-Modal Mapping of Molecular, Pathologic, and Radiologic Phenotypes in Lipid-Deficient Clear Cell Renal CellCarcinoma
Dec 13, 2025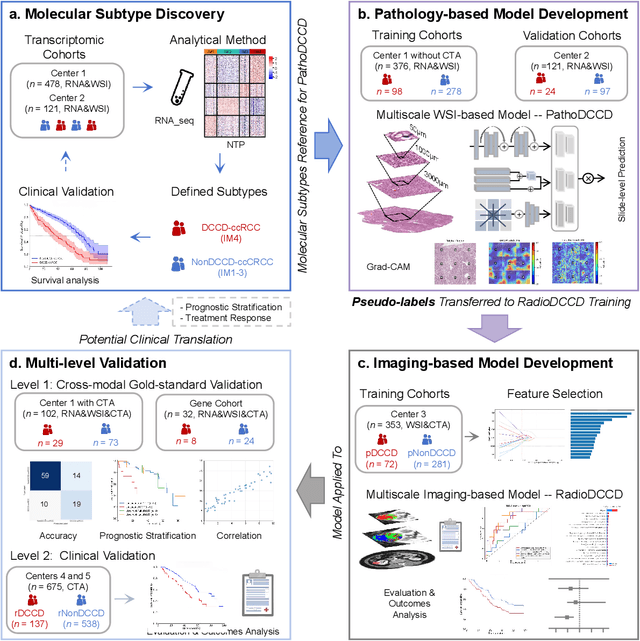
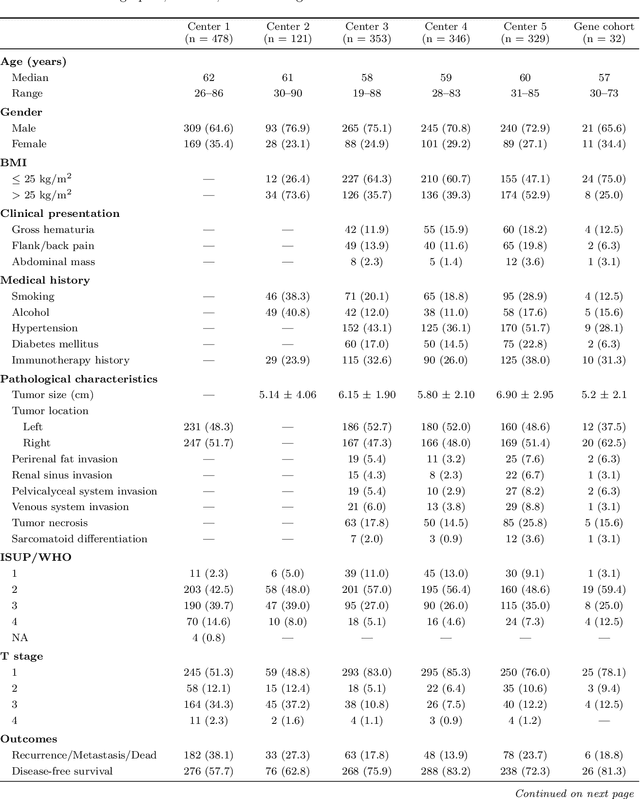
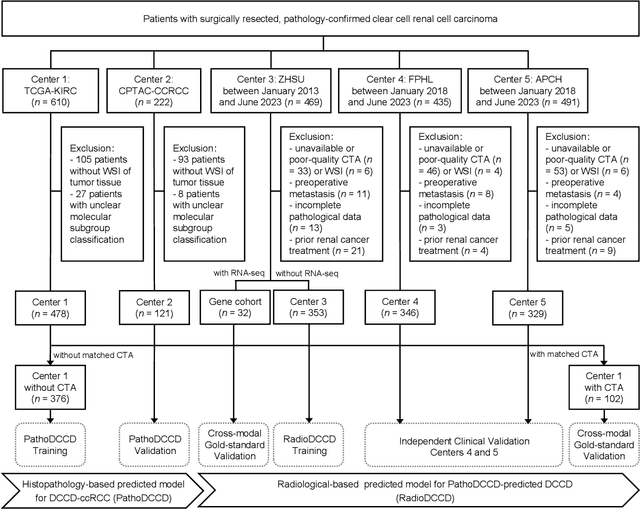
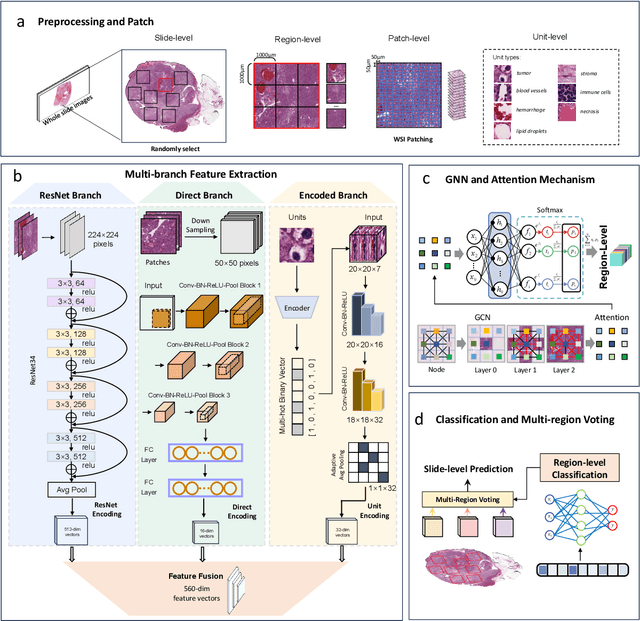
Clear cell renal cell carcinoma (ccRCC) exhibits extensive intratumoral heterogeneity on multiple biological scales, contributing to variable clinical outcomes and limiting the effectiveness of conventional TNM staging, which highlights the urgent need for multiscale integrative analytic frameworks. The lipid-deficient de-clear cell differentiated (DCCD) ccRCC subtype, defined by multi-omics analyses, is associated with adverse outcomes even in early-stage disease. Here, we establish a hierarchical cross-scale framework for the preoperative identification of DCCD-ccRCC. At the highest layer, cross-modal mapping transferred molecular signatures to histological and CT phenotypes, establishing a molecular-to-pathology-to-radiology supervisory bridge. Within this framework, each modality-specific model is designed to mirror the inherent hierarchical structure of tumor biology. PathoDCCD captured multi-scale microscopic features, from cellular morphology and tissue architecture to meso-regional organization. RadioDCCD integrated complementary macroscopic information by combining whole-tumor and its habitat-subregions radiomics with a 2D maximal-section heterogeneity metric. These nested models enabled integrated molecular subtype prediction and clinical risk stratification. Across five cohorts totaling 1,659 patients, PathoDCCD reliably recapitulated molecular subtypes, while RadioDCCD provided reliable preoperative prediction. The consistent predictions identified patients with the poorest clinical outcomes. This cross-scale paradigm unifies molecular biology, computational pathology, and quantitative radiology into a biologically grounded strategy for preoperative noninvasive molecular phenotyping of ccRCC.
Fast MLE and MAPE-Based Device Activity Detection for Grant-Free Access via PSCA and PSCA-Net
Mar 19, 2025



Fast and accurate device activity detection is the critical challenge in grant-free access for supporting massive machine-type communications (mMTC) and ultra-reliable low-latency communications (URLLC) in 5G and beyond. The state-of-the-art methods have unsatisfactory error rates or computation times. To address these outstanding issues, we propose new maximum likelihood estimation (MLE) and maximum a posterior estimation (MAPE) based device activity detection methods for known and unknown pathloss that achieve superior error rate and computation time tradeoffs using optimization and deep learning techniques. Specifically, we investigate four non-convex optimization problems for MLE and MAPE in the two pathloss cases, with one MAPE problem being formulated for the first time. For each non-convex problem, we develop an innovative parallel iterative algorithm using the parallel successive convex approximation (PSCA) method. Each PSCA-based algorithm allows parallel computations, uses up to the objective function's second-order information, converges to the problem's stationary points, and has a low per-iteration computational complexity compared to the state-of-the-art algorithms. Then, for each PSCA-based iterative algorithm, we present a deep unrolling neural network implementation, called PSCA-Net, to further reduce the computation time. Each PSCA-Net elegantly marries the underlying PSCA-based algorithm's parallel computation mechanism with the parallelizable neural network architecture and effectively optimizes its step sizes based on vast data samples to speed up the convergence. Numerical results demonstrate that the proposed methods can significantly reduce the error rate and computation time compared to the state-of-the-art methods, revealing their significant values for grant-free access.
Distill Any Depth: Distillation Creates a Stronger Monocular Depth Estimator
Feb 26, 2025Monocular depth estimation (MDE) aims to predict scene depth from a single RGB image and plays a crucial role in 3D scene understanding. Recent advances in zero-shot MDE leverage normalized depth representations and distillation-based learning to improve generalization across diverse scenes. However, current depth normalization methods for distillation, relying on global normalization, can amplify noisy pseudo-labels, reducing distillation effectiveness. In this paper, we systematically analyze the impact of different depth normalization strategies on pseudo-label distillation. Based on our findings, we propose Cross-Context Distillation, which integrates global and local depth cues to enhance pseudo-label quality. Additionally, we introduce a multi-teacher distillation framework that leverages complementary strengths of different depth estimation models, leading to more robust and accurate depth predictions. Extensive experiments on benchmark datasets demonstrate that our approach significantly outperforms state-of-the-art methods, both quantitatively and qualitatively.
DiffCalib: Reformulating Monocular Camera Calibration as Diffusion-Based Dense Incident Map Generation
May 24, 2024Monocular camera calibration is a key precondition for numerous 3D vision applications. Despite considerable advancements, existing methods often hinge on specific assumptions and struggle to generalize across varied real-world scenarios, and the performance is limited by insufficient training data. Recently, diffusion models trained on expansive datasets have been confirmed to maintain the capability to generate diverse, high-quality images. This success suggests a strong potential of the models to effectively understand varied visual information. In this work, we leverage the comprehensive visual knowledge embedded in pre-trained diffusion models to enable more robust and accurate monocular camera intrinsic estimation. Specifically, we reformulate the problem of estimating the four degrees of freedom (4-DoF) of camera intrinsic parameters as a dense incident map generation task. The map details the angle of incidence for each pixel in the RGB image, and its format aligns well with the paradigm of diffusion models. The camera intrinsic then can be derived from the incident map with a simple non-learning RANSAC algorithm during inference. Moreover, to further enhance the performance, we jointly estimate a depth map to provide extra geometric information for the incident map estimation. Extensive experiments on multiple testing datasets demonstrate that our model achieves state-of-the-art performance, gaining up to a 40% reduction in prediction errors. Besides, the experiments also show that the precise camera intrinsic and depth maps estimated by our pipeline can greatly benefit practical applications such as 3D reconstruction from a single in-the-wild image.
Fast Computation of Superquantile-Constrained Optimization Through Implicit Scenario Reduction
May 13, 2024Superquantiles have recently gained significant interest as a risk-aware metric for addressing fairness and distribution shifts in statistical learning and decision making problems. This paper introduces a fast, scalable and robust second-order computational framework to solve large-scale optimization problems with superquantile-based constraints. Unlike empirical risk minimization, superquantile-based optimization requires ranking random functions evaluated across all scenarios to compute the tail conditional expectation. While this tail-based feature might seem computationally unfriendly, it provides an advantageous setting for a semismooth-Newton-based augmented Lagrangian method. The superquantile operator effectively reduces the dimensions of the Newton systems since the tail expectation involves considerably fewer scenarios. Notably, the extra cost of obtaining relevant second-order information and performing matrix inversions is often comparable to, and sometimes even less than, the effort required for gradient computation. Our developed solver is particularly effective when the number of scenarios substantially exceeds the number of decision variables. In synthetic problems with linear and convex diagonal quadratic objectives, numerical experiments demonstrate that our method outperforms existing approaches by a large margin: It achieves speeds more than 750 times faster for linear and quadratic objectives than the alternating direction method of multipliers as implemented by OSQP for computing low-accuracy solutions. Additionally, it is up to 25 times faster for linear objectives and 70 times faster for quadratic objectives than the commercial solver Gurobi, and 20 times faster for linear objectives and 30 times faster for quadratic objectives than the Portfolio Safeguard optimization suite for high-accuracy solution computations.
Evaluation of ChatGPT-Generated Medical Responses: A Systematic Review and Meta-Analysis
Oct 12, 2023Large language models such as ChatGPT are increasingly explored in medical domains. However, the absence of standard guidelines for performance evaluation has led to methodological inconsistencies. This study aims to summarize the available evidence on evaluating ChatGPT's performance in medicine and provide direction for future research. We searched ten medical literature databases on June 15, 2023, using the keyword "ChatGPT". A total of 3520 articles were identified, of which 60 were reviewed and summarized in this paper and 17 were included in the meta-analysis. The analysis showed that ChatGPT displayed an overall integrated accuracy of 56% (95% CI: 51%-60%, I2 = 87%) in addressing medical queries. However, the studies varied in question resource, question-asking process, and evaluation metrics. Moreover, many studies failed to report methodological details, including the version of ChatGPT and whether each question was used independently or repeatedly. Our findings revealed that although ChatGPT demonstrated considerable potential for application in healthcare, the heterogeneity of the studies and insufficient reporting may affect the reliability of these results. Further well-designed studies with comprehensive and transparent reporting are needed to evaluate ChatGPT's performance in medicine.