 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntentReact: Guiding Reactive Object-Centric Navigation via Topological Intent
Mar 26, 2026Object-goal visual navigation requires robots to reason over semantic structure and act effectively under partial observability. Recent approaches based on object-level topological maps enable long-horizon navigation without dense geometric reconstruction, but their execution remains limited by the gap between global topological guidance and local perception-driven control. In particular, local decisions are made solely from the current egocentric observation, without access to information beyond the robot's field of view. As a result, the robot may persist along its current heading even when initially oriented away from the goal, moving toward directions that do not decrease the global topological distance. In this work, we propose IntentReact, an intent-conditioned object-centric navigation framework that introduces a compact interface between global topological planning and reactive object-centric control. Our approach encodes global topological guidance as a low-dimensional directional signal, termed intent, which conditions a learned waypoint prediction policy to bias navigation toward topologically consistent progression. This design enables the robot to promptly reorient when local observations are misleading, guiding motion toward directions that decrease global topological distance while preserving the reactivity and robustness of object-centric control. We evaluate the proposed framework through extensive experiments, demonstrating improved navigation success and execution quality compared to prior object-centric navigation methods.
MPD-SGR: Robust Spiking Neural Networks with Membrane Potential Distribution-Driven Surrogate Gradient Regularization
Nov 18, 2025The surrogate gradient (SG) method has shown significant promise in enhancing the performance of deep spiking neural networks (SNNs), but it also introduces vulnerabilities to adversarial attacks. Although spike coding strategies and neural dynamics parameters have been extensively studied for their impact on robustness, the critical role of gradient magnitude, which reflects the model's sensitivity to input perturbations, remains underexplored. In SNNs, the gradient magnitude is primarily determined by the interaction between the membrane potential distribution (MPD) and the SG function. In this study, we investigate the relationship between the MPD and SG and their implications for improving the robustness of SNNs. Our theoretical analysis reveals that reducing the proportion of membrane potentials lying within the gradient-available range of the SG function effectively mitigates the sensitivity of SNNs to input perturbations. Building upon this insight, we propose a novel MPD-driven surrogate gradient regularization (MPD-SGR) method, which enhances robustness by explicitly regularizing the MPD based on its interaction with the SG function. Extensive experiments across multiple image classification benchmarks and diverse network architectures confirm that the MPD-SGR method significantly enhances the resilience of SNNs to adversarial perturbations and exhibits strong generalizability across diverse network configurations, SG functions, and spike encoding schemes.
Spiking Neural Networks with Temporal Attention-Guided Adaptive Fusion for imbalanced Multi-modal Learning
May 20, 2025Multimodal spiking neural networks (SNNs) hold significant potential for energy-efficient sensory processing but face critical challenges in modality imbalance and temporal misalignment. Current approaches suffer from uncoordinated convergence speeds across modalities and static fusion mechanisms that ignore time-varying cross-modal interactions. We propose the temporal attention-guided adaptive fusion framework for multimodal SNNs with two synergistic innovations: 1) The Temporal Attention-guided Adaptive Fusion (TAAF) module that dynamically assigns importance scores to fused spiking features at each timestep, enabling hierarchical integration of temporally heterogeneous spike-based features; 2) The temporal adaptive balanced fusion loss that modulates learning rates per modality based on the above attention scores, preventing dominant modalities from monopolizing optimization. The proposed framework implements adaptive fusion, especially in the temporal dimension, and alleviates the modality imbalance during multimodal learning, mimicking cortical multisensory integration principles. Evaluations on CREMA-D, AVE, and EAD datasets demonstrate state-of-the-art performance (77.55\%, 70.65\% and 97.5\%accuracy, respectively) with energy efficiency. The system resolves temporal misalignment through learnable time-warping operations and faster modality convergence coordination than baseline SNNs. This work establishes a new paradigm for temporally coherent multimodal learning in neuromorphic systems, bridging the gap between biological sensory processing and efficient machine intelligence.
ASRC-SNN: Adaptive Skip Recurrent Connection Spiking Neural Network
May 16, 2025In recent years, Recurrent Spiking Neural Networks (RSNNs) have shown promising potential in long-term temporal modeling. Many studies focus on improving neuron models and also integrate recurrent structures, leveraging their synergistic effects to improve the long-term temporal modeling capabilities of Spiking Neural Networks (SNNs). However, these studies often place an excessive emphasis on the role of neurons, overlooking the importance of analyzing neurons and recurrent structures as an integrated framework. In this work, we consider neurons and recurrent structures as an integrated system and conduct a systematic analysis of gradient propagation along the temporal dimension, revealing a challenging gradient vanishing problem. To address this issue, we propose the Skip Recurrent Connection (SRC) as a replacement for the vanilla recurrent structure, effectively mitigating the gradient vanishing problem and enhancing long-term temporal modeling performance. Additionally, we propose the Adaptive Skip Recurrent Connection (ASRC), a method that can learn the skip span of skip recurrent connection in each layer of the network. Experiments show that replacing the vanilla recurrent structure in RSNN with SRC significantly improves the model's performance on temporal benchmark datasets. Moreover, ASRC-SNN outperforms SRC-SNN in terms of temporal modeling capabilities and robustness.
Hybrid Spiking Vision Transformer for Object Detection with Event Cameras
May 12, 2025
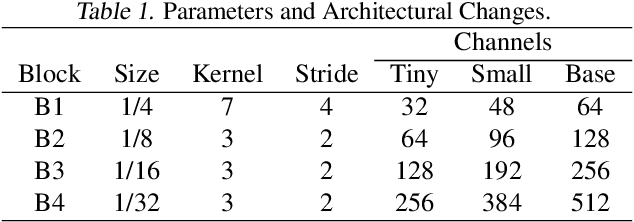
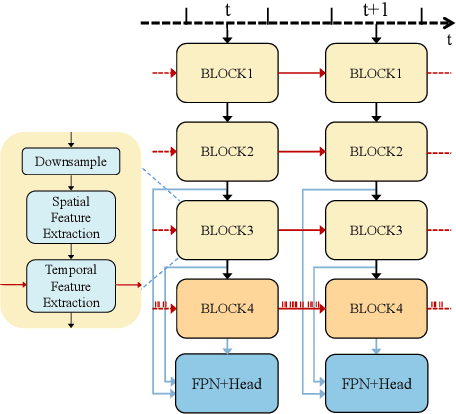
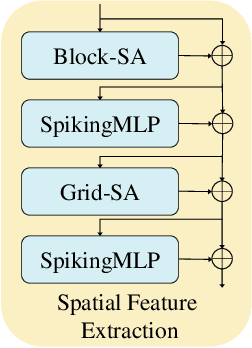
Event-based object detection has gained increasing attention due to its advantages such as high temporal resolution, wide dynamic range, and asynchronous address-event representation. Leveraging these advantages, Spiking Neural Networks (SNNs) have emerged as a promising approach, offering low energy consumption and rich spatiotemporal dynamics. To further enhance the performance of event-based object detection, this study proposes a novel hybrid spike vision Transformer (HsVT) model. The HsVT model integrates a spatial feature extraction module to capture local and global features, and a temporal feature extraction module to model time dependencies and long-term patterns in event sequences. This combination enables HsVT to capture spatiotemporal features, improving its capability to handle complex event-based object detection tasks. To support research in this area, we developed and publicly released The Fall Detection Dataset as a benchmark for event-based object detection tasks. This dataset, captured using an event-based camera, ensures facial privacy protection and reduces memory usage due to the event representation format. We evaluated the HsVT model on GEN1 and Fall Detection datasets across various model sizes. Experimental results demonstrate that HsVT achieves significant performance improvements in event detection with fewer parameters.
EBAD-Gaussian: Event-driven Bundle Adjusted Deblur Gaussian Splatting
Apr 14, 2025While 3D Gaussian Splatting (3D-GS) achieves photorealistic novel view synthesis, its performance degrades with motion blur. In scenarios with rapid motion or low-light conditions, existing RGB-based deblurring methods struggle to model camera pose and radiance changes during exposure, reducing reconstruction accuracy. Event cameras, capturing continuous brightness changes during exposure, can effectively assist in modeling motion blur and improving reconstruction quality. Therefore, we propose Event-driven Bundle Adjusted Deblur Gaussian Splatting (EBAD-Gaussian), which reconstructs sharp 3D Gaussians from event streams and severely blurred images. This method jointly learns the parameters of these Gaussians while recovering camera motion trajectories during exposure time. Specifically, we first construct a blur loss function by synthesizing multiple latent sharp images during the exposure time, minimizing the difference between real and synthesized blurred images. Then we use event stream to supervise the light intensity changes between latent sharp images at any time within the exposure period, supplementing the light intensity dynamic changes lost in RGB images. Furthermore, we optimize the latent sharp images at intermediate exposure times based on the event-based double integral (EDI) prior, applying consistency constraints to enhance the details and texture information of the reconstructed images. Extensive experiments on synthetic and real-world datasets show that EBAD-Gaussian can achieve high-quality 3D scene reconstruction under the condition of blurred images and event stream inputs.
Spiking Neural Networks for Temporal Processing: Status Quo and Future Prospects
Feb 13, 2025



Temporal processing is fundamental for both biological and artificial intelligence systems, as it enables the comprehension of dynamic environments and facilitates timely responses. Spiking Neural Networks (SNNs) excel in handling such data with high efficiency, owing to their rich neuronal dynamics and sparse activity patterns. Given the recent surge in the development of SNNs, there is an urgent need for a comprehensive evaluation of their temporal processing capabilities. In this paper, we first conduct an in-depth assessment of commonly used neuromorphic benchmarks, revealing critical limitations in their ability to evaluate the temporal processing capabilities of SNNs. To bridge this gap, we further introduce a benchmark suite consisting of three temporal processing tasks characterized by rich temporal dynamics across multiple timescales. Utilizing this benchmark suite, we perform a thorough evaluation of recently introduced SNN approaches to elucidate the current status of SNNs in temporal processing. Our findings indicate significant advancements in recently developed spiking neuron models and neural architectures regarding their temporal processing capabilities, while also highlighting a performance gap in handling long-range dependencies when compared to state-of-the-art non-spiking models. Finally, we discuss the key challenges and outline potential avenues for future research.
ALADE-SNN: Adaptive Logit Alignment in Dynamically Expandable Spiking Neural Networks for Class Incremental Learning
Dec 17, 2024



Inspired by the human brain's ability to adapt to new tasks without erasing prior knowledge, we develop spiking neural networks (SNNs) with dynamic structures for Class Incremental Learning (CIL). Our comparative experiments reveal that limited datasets introduce biases in logits distributions among tasks. Fixed features from frozen past-task extractors can cause overfitting and hinder the learning of new tasks. To address these challenges, we propose the ALADE-SNN framework, which includes adaptive logit alignment for balanced feature representation and OtoN suppression to manage weights mapping frozen old features to new classes during training, releasing them during fine-tuning. This approach dynamically adjusts the network architecture based on analytical observations, improving feature extraction and balancing performance between new and old tasks. Experiment results show that ALADE-SNN achieves an average incremental accuracy of 75.42 on the CIFAR100-B0 benchmark over 10 incremental steps. ALADE-SNN not only matches the performance of DNN-based methods but also surpasses state-of-the-art SNN-based continual learning algorithms. This advancement enhances continual learning in neuromorphic computing, offering a brain-inspired, energy-efficient solution for real-time data processing.
Enhancing SNN-based Spatio-Temporal Learning: A Benchmark Dataset and Cross-Modality Attention Model
Oct 21, 2024



Spiking Neural Networks (SNNs), renowned for their low power consumption, brain-inspired architecture, and spatio-temporal representation capabilities, have garnered considerable attention in recent years. Similar to Artificial Neural Networks (ANNs), high-quality benchmark datasets are of great importance to the advances of SNNs. However, our analysis indicates that many prevalent neuromorphic datasets lack strong temporal correlation, preventing SNNs from fully exploiting their spatio-temporal representation capabilities. Meanwhile, the integration of event and frame modalities offers more comprehensive visual spatio-temporal information. Yet, the SNN-based cross-modality fusion remains underexplored. In this work, we present a neuromorphic dataset called DVS-SLR that can better exploit the inherent spatio-temporal properties of SNNs. Compared to existing datasets, it offers advantages in terms of higher temporal correlation, larger scale, and more varied scenarios. In addition, our neuromorphic dataset contains corresponding frame data, which can be used for developing SNN-based fusion methods. By virtue of the dual-modal feature of the dataset, we propose a Cross-Modality Attention (CMA) based fusion method. The CMA model efficiently utilizes the unique advantages of each modality, allowing for SNNs to learn both temporal and spatial attention scores from the spatio-temporal features of event and frame modalities, subsequently allocating these scores across modalities to enhance their synergy. Experimental results demonstrate that our method not only improves recognition accuracy but also ensures robustness across diverse scenarios.
Spiking GS: Towards High-Accuracy and Low-Cost Surface Reconstruction via Spiking Neuron-based Gaussian Splatting
Oct 09, 20243D Gaussian Splatting is capable of reconstructing 3D scenes in minutes. Despite recent advances in improving surface reconstruction accuracy, the reconstructed results still exhibit bias and suffer from inefficiency in storage and training. This paper provides a different observation on the cause of the inefficiency and the reconstruction bias, which is attributed to the integration of the low-opacity parts (LOPs) of the generated Gaussians. We show that LOPs consist of Gaussians with overall low-opacity (LOGs) and the low-opacity tails (LOTs) of Gaussians. We propose Spiking GS to reduce such two types of LOPs by integrating spiking neurons into the Gaussian Splatting pipeline. Specifically, we introduce global and local full-precision integrate-and-fire spiking neurons to the opacity and representation function of flattened 3D Gaussians, respectively. Furthermore, we enhance the density control strategy with spiking neurons' thresholds and an new criterion on the scale of Gaussians. Our method can represent more accurate reconstructed surfaces at a lower cost. The code is available at \url{https://github.com/shippoT/Spiking_GS}.