 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReLaX: Reasoning with Latent Exploration for Large Reasoning Models
Dec 08, 2025Reinforcement Learning with Verifiable Rewards (RLVR) has recently demonstrated remarkable potential in enhancing the reasoning capability of Large Reasoning Models (LRMs). However, RLVR often leads to entropy collapse, resulting in premature policy convergence and performance saturation. While manipulating token-level entropy has proven effective for promoting policy exploration, we argue that the latent dynamics underlying token generation encode a far richer computational structure for steering policy optimization toward a more effective exploration-exploitation tradeoff. To enable tractable analysis and intervention of the latent dynamics of LRMs, we leverage Koopman operator theory to obtain a linearized representation of their hidden-state dynamics. This enables us to introduce Dynamic Spectral Dispersion (DSD), a new metric to quantify the heterogeneity of the model's latent dynamics, serving as a direct indicator of policy exploration. Building upon these foundations, we propose Reasoning with Latent eXploration (ReLaX), a paradigm that explicitly incorporates latent dynamics to regulate exploration and exploitation during policy optimization. Comprehensive experiments across a wide range of multimodal and text-only reasoning benchmarks show that ReLaX significantly mitigates premature convergence and consistently achieves state-of-the-art performance.
HEAR: An EEG Foundation Model with Heterogeneous Electrode Adaptive Representation
Oct 14, 2025Electroencephalography (EEG) is an essential technique for neuroscience research and brain-computer interface (BCI) applications. Recently, large-scale EEG foundation models have been developed, exhibiting robust generalization capabilities across diverse tasks and subjects. However, the heterogeneity of EEG devices not only hinders the widespread adoption of these models but also poses significant challenges to their further scaling and development. In this paper, we introduce HEAR, the first EEG foundation model explicitly designed to support heterogeneous EEG devices, accommodating varying electrode layouts and electrode counts. HEAR employs a learnable, coordinate-based spatial embedding to map electrodes with diverse layouts and varying counts into a unified representational space. This unified spatial representation is then processed by a novel spatially-guided transformer, which effectively captures spatiotemporal dependencies across electrodes. To support the development of HEAR, we construct a large-scale EEG dataset comprising 8,782 hours of data collected from over 150 distinct electrode layouts with up to 1,132 electrodes. Experimental results demonstrate that HEAR substantially outperforms existing EEG foundation models in supporting heterogeneous EEG devices and generalizing across diverse cognitive tasks and subjects.
SpikingBrain Technical Report: Spiking Brain-inspired Large Models
Sep 05, 2025Mainstream Transformer-based large language models face major efficiency bottlenecks: training computation scales quadratically with sequence length, and inference memory grows linearly, limiting long-context processing. Building large models on non-NVIDIA platforms also poses challenges for stable and efficient training. To address this, we introduce SpikingBrain, a family of brain-inspired models designed for efficient long-context training and inference. SpikingBrain leverages the MetaX GPU cluster and focuses on three aspects: (1) Model Architecture: linear and hybrid-linear attention architectures with adaptive spiking neurons; (2) Algorithmic Optimizations: an efficient, conversion-based training pipeline and a dedicated spike coding framework; (3) System Engineering: customized training frameworks, operator libraries, and parallelism strategies tailored to MetaX hardware. Using these techniques, we develop two models: SpikingBrain-7B, a linear LLM, and SpikingBrain-76B, a hybrid-linear MoE LLM. These models demonstrate the feasibility of large-scale LLM development on non-NVIDIA platforms. SpikingBrain achieves performance comparable to open-source Transformer baselines while using only about 150B tokens for continual pre-training. Our models significantly improve long-sequence training efficiency and deliver inference with (partially) constant memory and event-driven spiking behavior. For example, SpikingBrain-7B attains over 100x speedup in Time to First Token for 4M-token sequences. Training remains stable for weeks on hundreds of MetaX C550 GPUs, with the 7B model reaching a Model FLOPs Utilization of 23.4 percent. The proposed spiking scheme achieves 69.15 percent sparsity, enabling low-power operation. Overall, this work demonstrates the potential of brain-inspired mechanisms to drive the next generation of efficient and scalable large model design.
IML-Spikeformer: Input-aware Multi-Level Spiking Transformer for Speech Processing
Jul 10, 2025
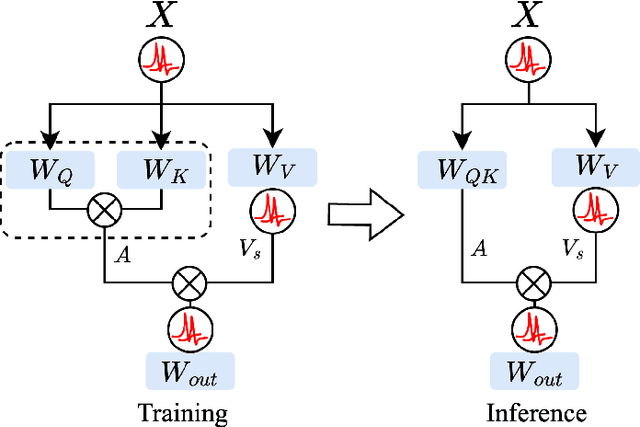


Spiking Neural Networks (SNNs), inspired by biological neural mechanisms, represent a promising neuromorphic computing paradigm that offers energy-efficient alternatives to traditional Artificial Neural Networks (ANNs). Despite proven effectiveness, SNN architectures have struggled to achieve competitive performance on large-scale speech processing task. Two key challenges hinder progress: (1) the high computational overhead during training caused by multi-timestep spike firing, and (2) the absence of large-scale SNN architectures tailored to speech processing tasks. To overcome the issues, we introduce Input-aware Multi-Level Spikeformer, i.e. IML-Spikeformer, a spiking Transformer architecture specifically designed for large-scale speech processing. Central to our design is the Input-aware Multi-Level Spike (IMLS) mechanism, which simulate multi-timestep spike firing within a single timestep using an adaptive, input-aware thresholding scheme. IML-Spikeformer further integrates a Reparameterized Spiking Self-Attention (RepSSA) module with a Hierarchical Decay Mask (HDM), forming the HD-RepSSA module. This module enhances the precision of attention maps and enables modeling of multi-scale temporal dependencies in speech signals. Experiments demonstrate that IML-Spikeformer achieves word error rates of 6.0\% on AiShell-1 and 3.4\% on Librispeech-960, comparable to conventional ANN transformers while reducing theoretical inference energy consumption by 4.64$\times$ and 4.32$\times$ respectively. IML-Spikeformer marks an advance of scalable SNN architectures for large-scale speech processing in both task performance and energy efficiency.
ZeCO: Zero Communication Overhead Sequence Parallelism for Linear Attention
Jul 02, 2025Linear attention mechanisms deliver significant advantages for Large Language Models (LLMs) by providing linear computational complexity, enabling efficient processing of ultra-long sequences (e.g., 1M context). However, existing Sequence Parallelism (SP) methods, essential for distributing these workloads across devices, become the primary bottleneck due to substantial communication overhead. In this paper, we introduce ZeCO (Zero Communication Overhead) sequence parallelism for linear attention models, a new SP method designed to overcome these limitations and achieve end-to-end near-linear scalability for long sequence training. For example, training a model with a 1M sequence length across 64 devices using ZeCO takes roughly the same time as training with an 16k sequence on a single device. At the heart of ZeCO lies All-Scan, a new collective communication primitive. All-Scan provides each SP rank with precisely the initial operator state it requires while maintaining a minimal communication footprint, effectively eliminating communication overhead. Theoretically, we prove the optimaity of ZeCO, showing that it introduces only negligible time and space overhead. Empirically, we compare the communication costs of different sequence parallelism strategies and demonstrate that All-Scan achieves the fastest communication in SP scenarios. Specifically, on 256 GPUs with an 8M sequence length, ZeCO achieves a 60\% speedup compared to the current state-of-the-art (SOTA) SP method. We believe ZeCO establishes a clear path toward efficiently training next-generation LLMs on previously intractable sequence lengths.
Diversity-Aware Policy Optimization for Large Language Model Reasoning
May 29, 2025The reasoning capabilities of large language models (LLMs) have advanced rapidly, particularly following the release of DeepSeek R1, which has inspired a surge of research into data quality and reinforcement learning (RL) algorithms. Despite the pivotal role diversity plays in RL, its influence on LLM reasoning remains largely underexplored. To bridge this gap, this work presents a systematic investigation into the impact of diversity in RL-based training for LLM reasoning, and proposes a novel diversity-aware policy optimization method. Across evaluations on 12 LLMs, we observe a strong positive correlation between the solution diversity and Potential at k (a novel metric quantifying an LLM's reasoning potential) in high-performing models. This finding motivates our method to explicitly promote diversity during RL training. Specifically, we design a token-level diversity and reformulate it into a practical objective, then we selectively apply it to positive samples. Integrated into the R1-zero training framework, our method achieves a 3.5 percent average improvement across four mathematical reasoning benchmarks, while generating more diverse and robust solutions.
Neuromorphic Sequential Arena: A Benchmark for Neuromorphic Temporal Processing
May 28, 2025Temporal processing is vital for extracting meaningful information from time-varying signals. Recent advancements in Spiking Neural Networks (SNNs) have shown immense promise in efficiently processing these signals. However, progress in this field has been impeded by the lack of effective and standardized benchmarks, which complicates the consistent measurement of technological advancements and limits the practical applicability of SNNs. To bridge this gap, we introduce the Neuromorphic Sequential Arena (NSA), a comprehensive benchmark that offers an effective, versatile, and application-oriented evaluation framework for neuromorphic temporal processing. The NSA includes seven real-world temporal processing tasks from a diverse range of application scenarios, each capturing rich temporal dynamics across multiple timescales. Utilizing NSA, we conduct extensive comparisons of recently introduced spiking neuron models and neural architectures, presenting comprehensive baselines in terms of task performance, training speed, memory usage, and energy efficiency. Our findings emphasize an urgent need for efficient SNN designs that can consistently deliver high performance across tasks with varying temporal complexities while maintaining low computational costs. NSA enables systematic tracking of advancements in neuromorphic algorithm research and paves the way for developing effective and efficient neuromorphic temporal processing systems.
MSVIT: Improving Spiking Vision Transformer Using Multi-scale Attention Fusion
May 19, 2025The combination of Spiking Neural Networks(SNNs) with Vision Transformer architectures has attracted significant attention due to the great potential for energy-efficient and high-performance computing paradigms. However, a substantial performance gap still exists between SNN-based and ANN-based transformer architectures. While existing methods propose spiking self-attention mechanisms that are successfully combined with SNNs, the overall architectures proposed by these methods suffer from a bottleneck in effectively extracting features from different image scales. In this paper, we address this issue and propose MSVIT, a novel spike-driven Transformer architecture, which firstly uses multi-scale spiking attention (MSSA) to enrich the capability of spiking attention blocks. We validate our approach across various main data sets. The experimental results show that MSVIT outperforms existing SNN-based models, positioning itself as a state-of-the-art solution among SNN-transformer architectures. The codes are available at https://github.com/Nanhu-AI-Lab/MSViT.
EventDiff: A Unified and Efficient Diffusion Model Framework for Event-based Video Frame Interpolation
May 13, 2025



Video Frame Interpolation (VFI) is a fundamental yet challenging task in computer vision, particularly under conditions involving large motion, occlusion, and lighting variation. Recent advancements in event cameras have opened up new opportunities for addressing these challenges. While existing event-based VFI methods have succeeded in recovering large and complex motions by leveraging handcrafted intermediate representations such as optical flow, these designs often compromise high-fidelity image reconstruction under subtle motion scenarios due to their reliance on explicit motion modeling. Meanwhile, diffusion models provide a promising alternative for VFI by reconstructing frames through a denoising process, eliminating the need for explicit motion estimation or warping operations. In this work, we propose EventDiff, a unified and efficient event-based diffusion model framework for VFI. EventDiff features a novel Event-Frame Hybrid AutoEncoder (HAE) equipped with a lightweight Spatial-Temporal Cross Attention (STCA) module that effectively fuses dynamic event streams with static frames. Unlike previous event-based VFI methods, EventDiff performs interpolation directly in the latent space via a denoising diffusion process, making it more robust across diverse and challenging VFI scenarios. Through a two-stage training strategy that first pretrains the HAE and then jointly optimizes it with the diffusion model, our method achieves state-of-the-art performance across multiple synthetic and real-world event VFI datasets. The proposed method outperforms existing state-of-the-art event-based VFI methods by up to 1.98dB in PSNR on Vimeo90K-Triplet and shows superior performance in SNU-FILM tasks with multiple difficulty levels. Compared to the emerging diffusion-based VFI approach, our method achieves up to 5.72dB PSNR gain on Vimeo90K-Triplet and 4.24X faster inference.
Spiking Neural Networks for Temporal Processing: Status Quo and Future Prospects
Feb 13, 2025



Temporal processing is fundamental for both biological and artificial intelligence systems, as it enables the comprehension of dynamic environments and facilitates timely responses. Spiking Neural Networks (SNNs) excel in handling such data with high efficiency, owing to their rich neuronal dynamics and sparse activity patterns. Given the recent surge in the development of SNNs, there is an urgent need for a comprehensive evaluation of their temporal processing capabilities. In this paper, we first conduct an in-depth assessment of commonly used neuromorphic benchmarks, revealing critical limitations in their ability to evaluate the temporal processing capabilities of SNNs. To bridge this gap, we further introduce a benchmark suite consisting of three temporal processing tasks characterized by rich temporal dynamics across multiple timescales. Utilizing this benchmark suite, we perform a thorough evaluation of recently introduced SNN approaches to elucidate the current status of SNNs in temporal processing. Our findings indicate significant advancements in recently developed spiking neuron models and neural architectures regarding their temporal processing capabilities, while also highlighting a performance gap in handling long-range dependencies when compared to state-of-the-art non-spiking models. Finally, we discuss the key challenges and outline potential avenues for future research.