 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniHash: Unifying Pointwise and Pairwise Hashing Paradigms for Seen and Unseen Category Retrieval
Jan 14, 2026Effective retrieval across both seen and unseen categories is crucial for modern image retrieval systems. Retrieval on seen categories ensures precise recognition of known classes, while retrieval on unseen categories promotes generalization to novel classes with limited supervision. However, most existing deep hashing methods are confined to a single training paradigm, either pointwise or pairwise, where the former excels on seen categories and the latter generalizes better to unseen ones. To overcome this limitation, we propose Unified Hashing (UniHash), a dual-branch framework that unifies the strengths of both paradigms to achieve balanced retrieval performance across seen and unseen categories. UniHash consists of two complementary branches: a center-based branch following the pointwise paradigm and a pairwise branch following the pairwise paradigm. A novel hash code learning method is introduced to enable bidirectional knowledge transfer between branches, improving hash code discriminability and generalization. It employs a mutual learning loss to align hash representations and introduces a Split-Merge Mixture of Hash Experts (SM-MoH) module to enhance cross-branch exchange of hash representations. Theoretical analysis substantiates the effectiveness of UniHash, and extensive experiments on CIFAR-10, MSCOCO, and ImageNet demonstrate that UniHash consistently achieves state-of-the-art performance in both seen and unseen image retrieval scenarios.
Stable and Explainable Personality Trait Evaluation in Large Language Models with Internal Activations
Jan 14, 2026Evaluating personality traits in Large Language Models (LLMs) is key to model interpretation, comparison, and responsible deployment. However, existing questionnaire-based evaluation methods exhibit limited stability and offer little explainability, as their results are highly sensitive to minor variations in prompt phrasing or role-play configurations. To address these limitations, we propose an internal-activation-based approach, termed Persona-Vector Neutrality Interpolation (PVNI), for stable and explainable personality trait evaluation in LLMs. PVNI extracts a persona vector associated with a target personality trait from the model's internal activations using contrastive prompts. It then estimates the corresponding neutral score by interpolating along the persona vector as an anchor axis, enabling an interpretable comparison between the neutral prompt representation and the persona direction. We provide a theoretical analysis of the effectiveness and generalization properties of PVNI. Extensive experiments across diverse LLMs demonstrate that PVNI yields substantially more stable personality trait evaluations than existing methods, even under questionnaire and role-play variants.
MAP-VLA: Memory-Augmented Prompting for Vision-Language-Action Model in Robotic Manipulation
Nov 12, 2025Pre-trained Vision-Language-Action (VLA) models have achieved remarkable success in improving robustness and generalization for end-to-end robotic manipulation. However, these models struggle with long-horizon tasks due to their lack of memory and reliance solely on immediate sensory inputs. To address this limitation, we propose Memory-Augmented Prompting for Vision-Language-Action model (MAP-VLA), a novel framework that empowers pre-trained VLA models with demonstration-derived memory prompts to augment action generation for long-horizon robotic manipulation tasks. To achieve this, MAP-VLA first constructs a memory library from historical demonstrations, where each memory unit captures information about a specific stage of a task. These memory units are implemented as learnable soft prompts optimized through prompt tuning. Then, during real-time task execution, MAP-VLA retrieves relevant memory through trajectory similarity matching and dynamically integrates it into the VLA model for augmented action generation. Importantly, this prompt tuning and retrieval augmentation approach operates as a plug-and-play module for a frozen VLA model, offering a lightweight and flexible solution to improve task performance. Experimental results show that MAP-VLA delivers up to 7.0% absolute performance gains in the simulation benchmark and 25.0% on real robot evaluations for long-horizon tasks, surpassing the current state-of-the-art methods.
Mutual Learning for Hashing: Unlocking Strong Hash Functions from Weak Supervision
Oct 09, 2025Deep hashing has been widely adopted for large-scale image retrieval, with numerous strategies proposed to optimize hash function learning. Pairwise-based methods are effective in learning hash functions that preserve local similarity relationships, whereas center-based methods typically achieve superior performance by more effectively capturing global data distributions. However, the strength of center-based methods in modeling global structures often comes at the expense of underutilizing important local similarity information. To address this limitation, we propose Mutual Learning for Hashing (MLH), a novel weak-to-strong framework that enhances a center-based hashing branch by transferring knowledge from a weaker pairwise-based branch. MLH consists of two branches: a strong center-based branch and a weaker pairwise-based branch. Through an iterative mutual learning process, the center-based branch leverages local similarity cues learned by the pairwise-based branch. Furthermore, inspired by the mixture-of-experts paradigm, we introduce a novel mixture-of-hash-experts module that enables effective cross-branch interaction, further enhancing the performance of both branches. Extensive experiments demonstrate that MLH consistently outperforms state-of-the-art hashing methods across multiple benchmark datasets.
AFT: An Exemplar-Free Class Incremental Learning Method for Environmental Sound Classification
Sep 19, 2025



As sounds carry rich information, environmental sound classification (ESC) is crucial for numerous applications such as rare wild animals detection. However, our world constantly changes, asking ESC models to adapt to new sounds periodically. The major challenge here is catastrophic forgetting, where models lose the ability to recognize old sounds when learning new ones. Many methods address this using replay-based continual learning. This could be impractical in scenarios such as data privacy concerns. Exemplar-free methods are commonly used but can distort old features, leading to worse performance. To overcome such limitations, we propose an Acoustic Feature Transformation (AFT) technique that aligns the temporal features of old classes to the new space, including a selectively compressed feature space. AFT mitigates the forgetting of old knowledge without retaining past data. We conducted experiments on two datasets, showing consistent improvements over baseline models with accuracy gains of 3.7\% to 3.9\%.
Federated Learning for Medical Image Classification: A Comprehensive Benchmark
Apr 07, 2025



The federated learning paradigm is wellsuited for the field of medical image analysis, as it can effectively cope with machine learning on isolated multicenter data while protecting the privacy of participating parties. However, current research on optimization algorithms in federated learning often focuses on limited datasets and scenarios, primarily centered around natural images, with insufficient comparative experiments in medical contexts. In this work, we conduct a comprehensive evaluation of several state-of-the-art federated learning algorithms in the context of medical imaging. We conduct a fair comparison of classification models trained using various federated learning algorithms across multiple medical imaging datasets. Additionally, we evaluate system performance metrics, such as communication cost and computational efficiency, while considering different federated learning architectures. Our findings show that medical imaging datasets pose substantial challenges for current federated learning optimization algorithms. No single algorithm consistently delivers optimal performance across all medical federated learning scenarios, and many optimization algorithms may underperform when applied to these datasets. Our experiments provide a benchmark and guidance for future research and application of federated learning in medical imaging contexts. Furthermore, we propose an efficient and robust method that combines generative techniques using denoising diffusion probabilistic models with label smoothing to augment datasets, widely enhancing the performance of federated learning on classification tasks across various medical imaging datasets. Our code will be released on GitHub, offering a reliable and comprehensive benchmark for future federated learning studies in medical imaging.
FACT: Feature Adaptive Continual-learning Tracker for Multiple Object Tracking
Sep 12, 2024



Multiple object tracking (MOT) involves identifying multiple targets and assigning them corresponding IDs within a video sequence, where occlusions are often encountered. Recent methods address occlusions using appearance cues through online learning techniques to improve adaptivity or offline learning techniques to utilize temporal information from videos. However, most existing online learning-based MOT methods are unable to learn from all past tracking information to improve adaptivity on long-term occlusions while maintaining real-time tracking speed. On the other hand, temporal information-based offline learning methods maintain a long-term memory to store past tracking information, but this approach restricts them to use only local past information during tracking. To address these challenges, we propose a new MOT framework called the Feature Adaptive Continual-learning Tracker (FACT), which enables real-time tracking and feature learning for targets by utilizing all past tracking information. We demonstrate that the framework can be integrated with various state-of-the-art feature-based trackers, thereby improving their tracking ability. Specifically, we develop the feature adaptive continual-learning (FAC) module, a neural network that can be trained online to learn features adaptively using all past tracking information during tracking. Moreover, we also introduce a two-stage association module specifically designed for the proposed continual learning-based tracking. Extensive experiment results demonstrate that the proposed method achieves state-of-the-art online tracking performance on MOT17 and MOT20 benchmarks. The code will be released upon acceptance.
Dual Branch Network Towards Accurate Printed Mathematical Expression Recognition
Dec 14, 2023Over the past years, Printed Mathematical Expression Recognition (PMER) has progressed rapidly. However, due to the insufficient context information captured by Convolutional Neural Networks, some mathematical symbols might be incorrectly recognized or missed. To tackle this problem, in this paper, a Dual Branch transformer-based Network (DBN) is proposed to learn both local and global context information for accurate PMER. In our DBN, local and global features are extracted simultaneously, and a Context Coupling Module (CCM) is developed to complement the features between the global and local contexts. CCM adopts an interactive manner so that the coupled context clues are highly correlated to each expression symbol. Additionally, we design a Dynamic Soft Target (DST) strategy to utilize the similarities among symbol categories for reasonable label generation. Our experimental results have demonstrated that DBN can accurately recognize mathematical expressions and has achieved state-of-the-art performance.
POAR: Towards Open-World Pedestrian Attribute Recognition
Mar 26, 2023



Pedestrian attribute recognition (PAR) aims to predict the attributes of a target pedestrian in a surveillance system. Existing methods address the PAR problem by training a multi-label classifier with predefined attribute classes. However, it is impossible to exhaust all pedestrian attributes in the real world. To tackle this problem, we develop a novel pedestrian open-attribute recognition (POAR) framework. Our key idea is to formulate the POAR problem as an image-text search problem. We design a Transformer-based image encoder with a masking strategy. A set of attribute tokens are introduced to focus on specific pedestrian parts (e.g., head, upper body, lower body, feet, etc.) and encode corresponding attributes into visual embeddings. Each attribute category is described as a natural language sentence and encoded by the text encoder. Then, we compute the similarity between the visual and text embeddings of attributes to find the best attribute descriptions for the input images. Different from existing methods that learn a specific classifier for each attribute category, we model the pedestrian at a part-level and explore the searching method to handle the unseen attributes. Finally, a many-to-many contrastive (MTMC) loss with masked tokens is proposed to train the network since a pedestrian image can comprise multiple attributes. Extensive experiments have been conducted on benchmark PAR datasets with an open-attribute setting. The results verified the effectiveness of the proposed POAR method, which can form a strong baseline for the POAR task.
ACIL: Analytic Class-Incremental Learning with Absolute Memorization and Privacy Protection
May 30, 2022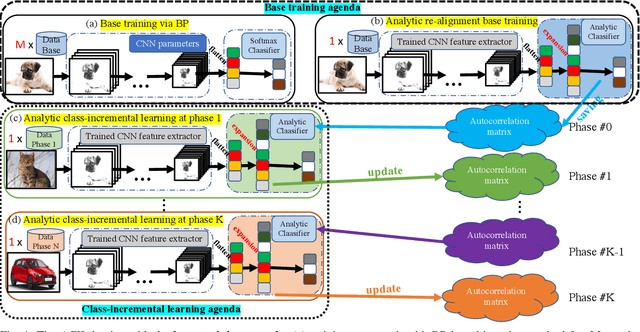
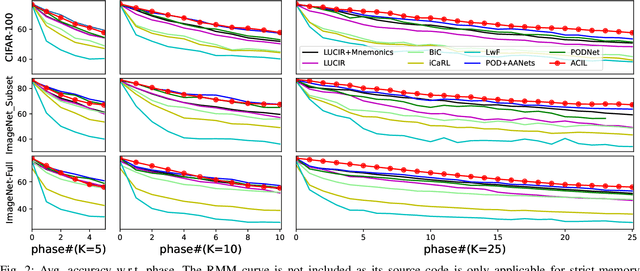

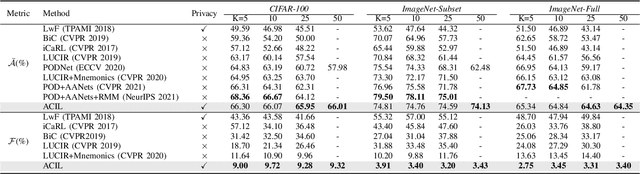
Class-incremental learning (CIL) learns a classification model with training data of different classes arising progressively. Existing CIL either suffers from serious accuracy loss due to catastrophic forgetting, or invades data privacy by revisiting used exemplars. Inspired by linear learning formulations, we propose an analytic class-incremental learning (ACIL) with absolute memorization of past knowledge while avoiding breaching of data privacy (i.e., without storing historical data). The absolute memorization is demonstrated in the sense that class-incremental learning using ACIL given present data would give identical results to that from its joint-learning counterpart which consumes both present and historical samples. This equality is theoretically validated. Data privacy is ensured since no historical data are involved during the learning process. Empirical validations demonstrate ACIL's competitive accuracy performance with near-identical results for various incremental task settings (e.g., 5-50 phases). This also allows ACIL to outperform the state-of-the-art methods for large-phase scenarios (e.g., 25 and 50 phases).