 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Lottery Ticket Hypothesis for Vision Transformers
Nov 02, 2022



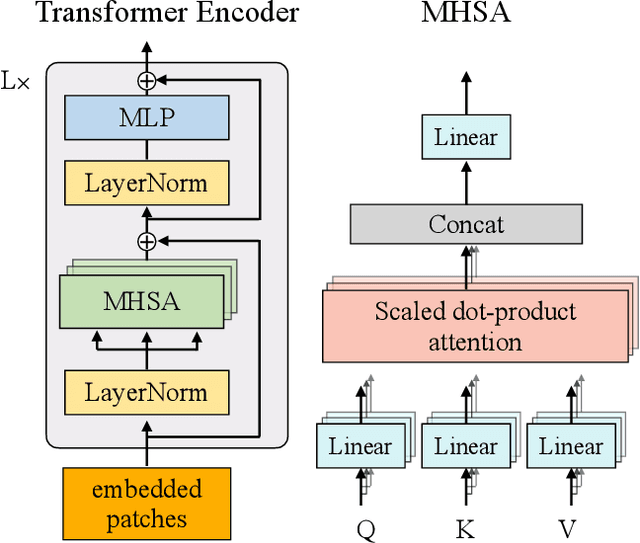
The conventional lottery ticket hypothesis (LTH) claims that there exists a sparse subnetwork within a dense neural network and a proper random initialization method, called the winning ticket, such that it can be trained from scratch to almost as good as the dense counterpart. Meanwhile, the research of LTH in vision transformers (ViTs) is scarcely evaluated. In this paper, we first show that the conventional winning ticket is hard to find at weight level of ViTs by existing methods. Then, we generalize the LTH for ViTs to input images consisting of image patches inspired by the input dependence of ViTs. That is, there exists a subset of input image patches such that a ViT can be trained from scratch by using only this subset of patches and achieve similar accuracy to the ViTs trained by using all image patches. We call this subset of input patches the winning tickets, which represent a significant amount of information in the input. Furthermore, we present a simple yet effective method to find the winning tickets in input patches for various types of ViT, including DeiT, LV-ViT, and Swin Transformers. More specifically, we use a ticket selector to generate the winning tickets based on the informativeness of patches. Meanwhile, we build another randomly selected subset of patches for comparison, and the experiments show that there is clear difference between the performance of models trained with winning tickets and randomly selected subsets.
CHEX: CHannel EXploration for CNN Model Compression
Mar 29, 2022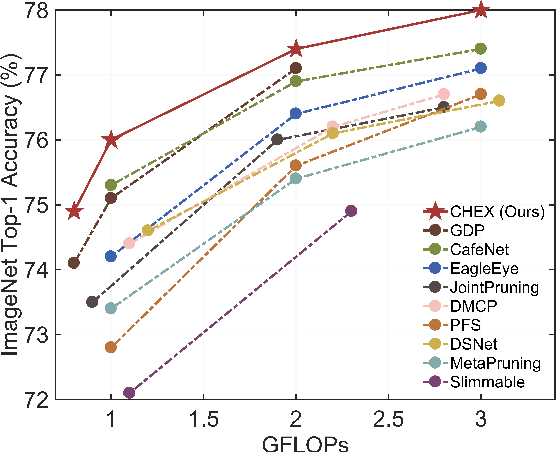
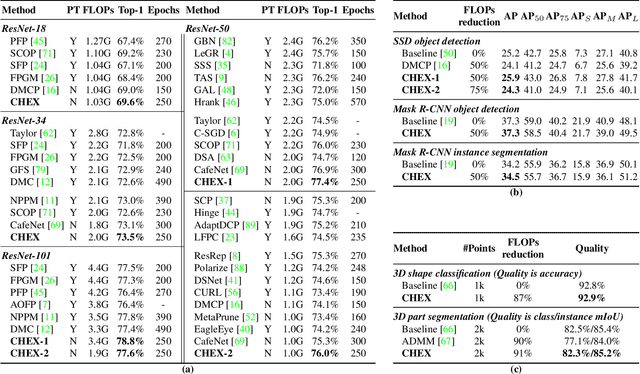
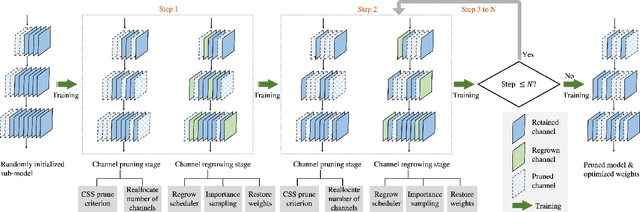

Channel pruning has been broadly recognized as an effective technique to reduce the computation and memory cost of deep convolutional neural networks. However, conventional pruning methods have limitations in that: they are restricted to pruning process only, and they require a fully pre-trained large model. Such limitations may lead to sub-optimal model quality as well as excessive memory and training cost. In this paper, we propose a novel Channel Exploration methodology, dubbed as CHEX, to rectify these problems. As opposed to pruning-only strategy, we propose to repeatedly prune and regrow the channels throughout the training process, which reduces the risk of pruning important channels prematurely. More exactly: From intra-layer's aspect, we tackle the channel pruning problem via a well known column subset selection (CSS) formulation. From inter-layer's aspect, our regrowing stages open a path for dynamically re-allocating the number of channels across all the layers under a global channel sparsity constraint. In addition, all the exploration process is done in a single training from scratch without the need of a pre-trained large model. Experimental results demonstrate that CHEX can effectively reduce the FLOPs of diverse CNN architectures on a variety of computer vision tasks, including image classification, object detection, instance segmentation, and 3D vision. For example, our compressed ResNet-50 model on ImageNet dataset achieves 76% top1 accuracy with only 25% FLOPs of the original ResNet-50 model, outperforming previous state-of-the-art channel pruning methods. The checkpoints and code are available at here .
Coarsening the Granularity: Towards Structurally Sparse Lottery Tickets
Feb 09, 2022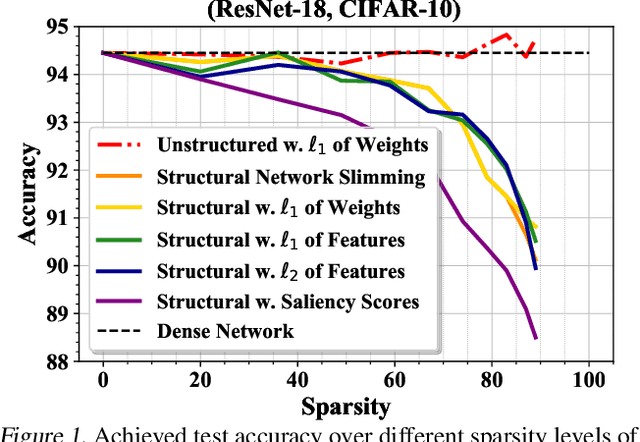
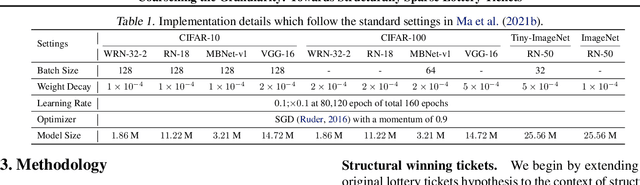
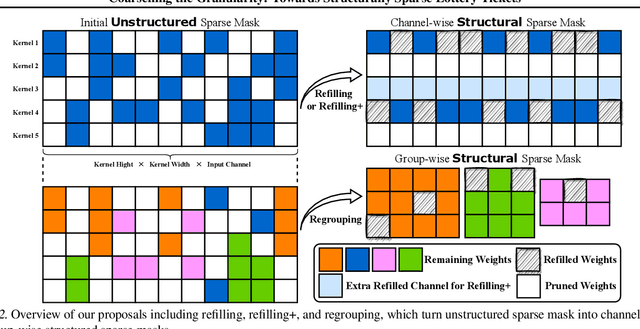
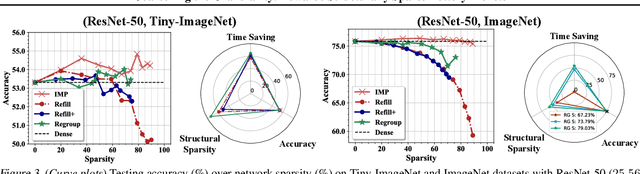
The lottery ticket hypothesis (LTH) has shown that dense models contain highly sparse subnetworks (i.e., winning tickets) that can be trained in isolation to match full accuracy. Despite many exciting efforts being made, there is one "commonsense" seldomly challenged: a winning ticket is found by iterative magnitude pruning (IMP) and hence the resultant pruned subnetworks have only unstructured sparsity. That gap limits the appeal of winning tickets in practice, since the highly irregular sparse patterns are challenging to accelerate on hardware. Meanwhile, directly substituting structured pruning for unstructured pruning in IMP damages performance more severely and is usually unable to locate winning tickets. In this paper, we demonstrate the first positive result that a structurally sparse winning ticket can be effectively found in general. The core idea is to append "post-processing techniques" after each round of (unstructured) IMP, to enforce the formation of structural sparsity. Specifically, we first "re-fill" pruned elements back in some channels deemed to be important, and then "re-group" non-zero elements to create flexible group-wise structural patterns. Both our identified channel- and group-wise structural subnetworks win the lottery, with substantial inference speedups readily supported by existing hardware. Extensive experiments, conducted on diverse datasets across multiple network backbones, consistently validate our proposal, showing that the hardware acceleration roadblock of LTH is now removed. Specifically, the structural winning tickets obtain up to {64.93%, 64.84%, 64.84%} running time savings at {36% ~ 80%, 74%, 58%} sparsity on {CIFAR, Tiny-ImageNet, ImageNet}, while maintaining comparable accuracy. Codes are available in https://github.com/VITA-Group/Structure-LTH.
VAQF: Fully Automatic Software-hardware Co-design Framework for Low-bit Vision Transformer
Jan 17, 2022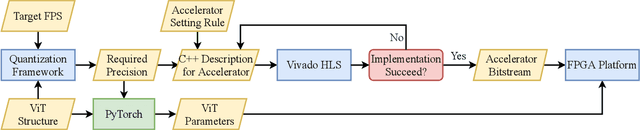
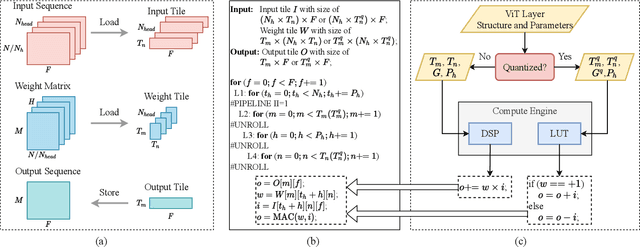
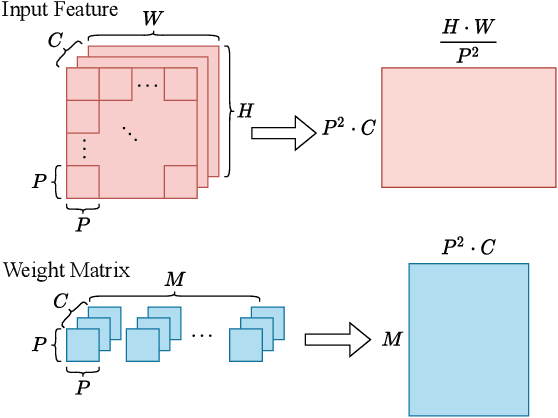
The transformer architectures with attention mechanisms have obtained success in Nature Language Processing (NLP), and Vision Transformers (ViTs) have recently extended the application domains to various vision tasks. While achieving high performance, ViTs suffer from large model size and high computation complexity that hinders the deployment of them on edge devices. To achieve high throughput on hardware and preserve the model accuracy simultaneously, we propose VAQF, a framework that builds inference accelerators on FPGA platforms for quantized ViTs with binary weights and low-precision activations. Given the model structure and the desired frame rate, VAQF will automatically output the required quantization precision for activations as well as the optimized parameter settings of the accelerator that fulfill the hardware requirements. The implementations are developed with Vivado High-Level Synthesis (HLS) on the Xilinx ZCU102 FPGA board, and the evaluation results with the DeiT-base model indicate that a frame rate requirement of 24 frames per second (FPS) is satisfied with 8-bit activation quantization, and a target of 30 FPS is met with 6-bit activation quantization. To the best of our knowledge, this is the first time quantization has been incorporated into ViT acceleration on FPGAs with the help of a fully automatic framework to guide the quantization strategy on the software side and the accelerator implementations on the hardware side given the target frame rate. Very small compilation time cost is incurred compared with quantization training, and the generated accelerators show the capability of achieving real-time execution for state-of-the-art ViT models on FPGAs.
SPViT: Enabling Faster Vision Transformers via Soft Token Pruning
Dec 27, 2021

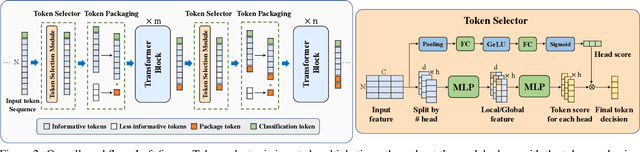
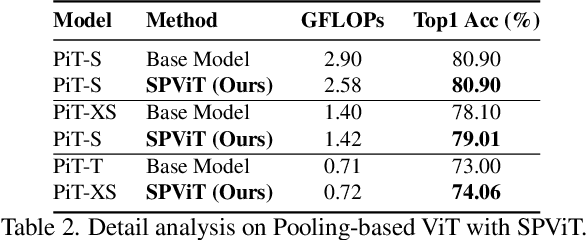
Recently, Vision Transformer (ViT) has continuously established new milestones in the computer vision field, while the high computation and memory cost makes its propagation in industrial production difficult. Pruning, a traditional model compression paradigm for hardware efficiency, has been widely applied in various DNN structures. Nevertheless, it stays ambiguous on how to perform exclusive pruning on the ViT structure. Considering three key points: the structural characteristics, the internal data pattern of ViTs, and the related edge device deployment, we leverage the input token sparsity and propose a computation-aware soft pruning framework, which can be set up on vanilla Transformers of both flatten and CNN-type structures, such as Pooling-based ViT (PiT). More concretely, we design a dynamic attention-based multi-head token selector, which is a lightweight module for adaptive instance-wise token selection. We further introduce a soft pruning technique, which integrates the less informative tokens generated by the selector module into a package token that will participate in subsequent calculations rather than being completely discarded. Our framework is bound to the trade-off between accuracy and computation constraints of specific edge devices through our proposed computation-aware training strategy. Experimental results show that our framework significantly reduces the computation cost of ViTs while maintaining comparable performance on image classification. Moreover, our framework can guarantee the identified model to meet resource specifications of mobile devices and FPGA, and even achieve the real-time execution of DeiT-T on mobile platforms. For example, our method reduces the latency of DeiT-T to 26 ms (26%$\sim $41% superior to existing works) on the mobile device with 0.25%$\sim $4% higher top-1 accuracy on ImageNet. Our code will be released soon.
Load-balanced Gather-scatter Patterns for Sparse Deep Neural Networks
Dec 20, 2021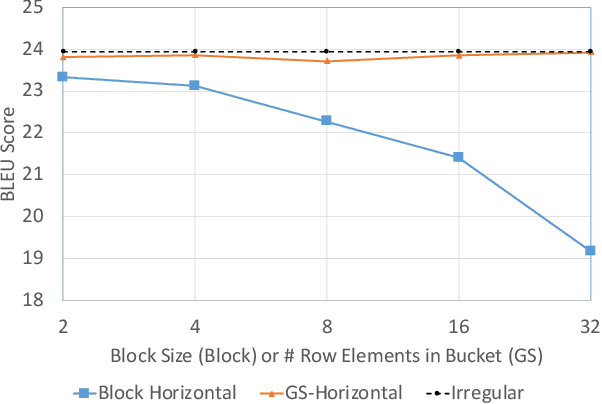
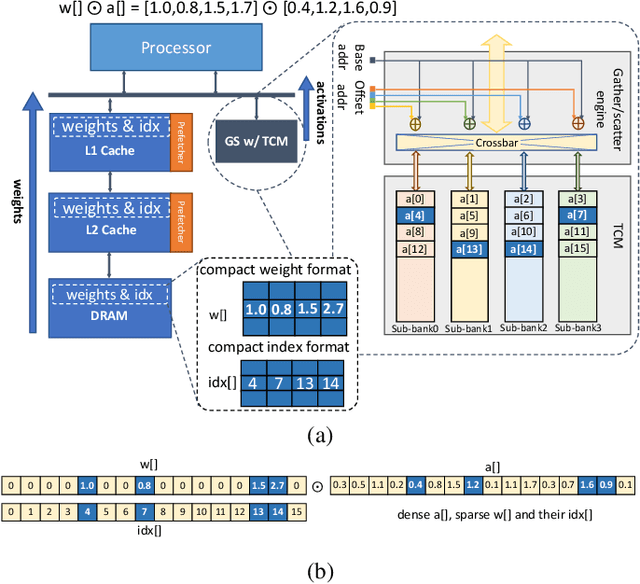

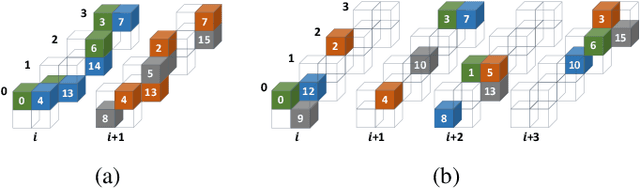
Deep neural networks (DNNs) have been proven to be effective in solving many real-life problems, but its high computation cost prohibits those models from being deployed to edge devices. Pruning, as a method to introduce zeros to model weights, has shown to be an effective method to provide good trade-offs between model accuracy and computation efficiency, and is a widely-used method to generate compressed models. However, the granularity of pruning makes important trade-offs. At the same sparsity level, a coarse-grained structured sparse pattern is more efficient on conventional hardware but results in worse accuracy, while a fine-grained unstructured sparse pattern can achieve better accuracy but is inefficient on existing hardware. On the other hand, some modern processors are equipped with fast on-chip scratchpad memories and gather/scatter engines that perform indirect load and store operations on such memories. In this work, we propose a set of novel sparse patterns, named gather-scatter (GS) patterns, to utilize the scratchpad memories and gather/scatter engines to speed up neural network inferences. Correspondingly, we present a compact sparse format. The proposed set of sparse patterns, along with a novel pruning methodology, address the load imbalance issue and result in models with quality close to unstructured sparse models and computation efficiency close to structured sparse models. Our experiments show that GS patterns consistently make better trade-offs between accuracy and computation efficiency compared to conventional structured sparse patterns. GS patterns can reduce the runtime of the DNN components by two to three times at the same accuracy levels. This is confirmed on three different deep learning tasks and popular models, namely, GNMT for machine translation, ResNet50 for image recognition, and Japser for acoustic speech recognition.
MEST: Accurate and Fast Memory-Economic Sparse Training Framework on the Edge
Oct 26, 2021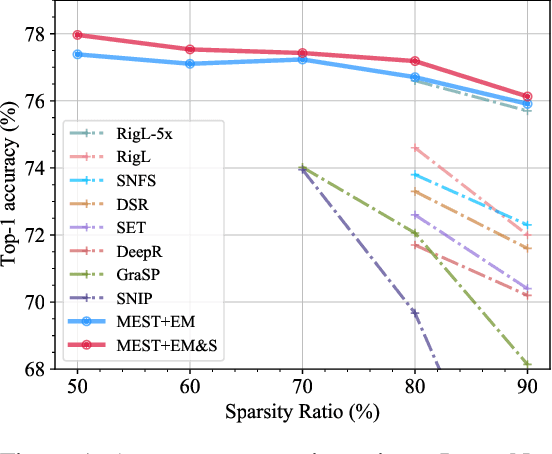
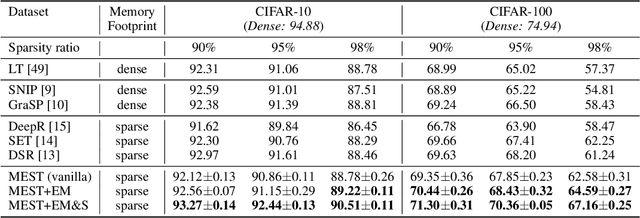
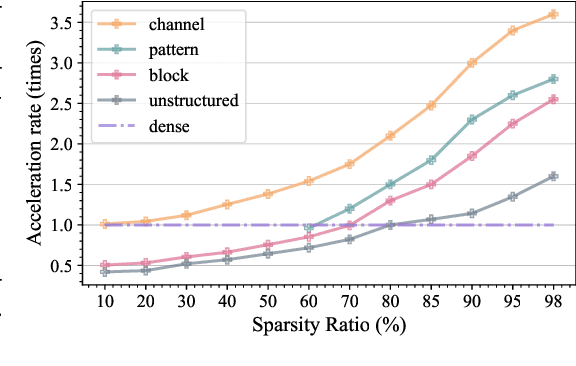
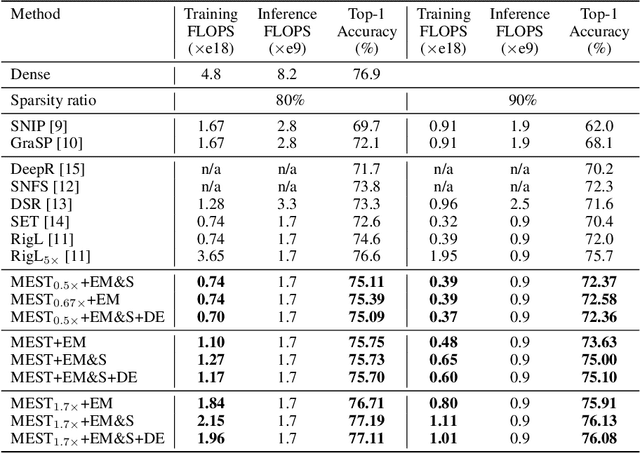
Recently, a new trend of exploring sparsity for accelerating neural network training has emerged, embracing the paradigm of training on the edge. This paper proposes a novel Memory-Economic Sparse Training (MEST) framework targeting for accurate and fast execution on edge devices. The proposed MEST framework consists of enhancements by Elastic Mutation (EM) and Soft Memory Bound (&S) that ensure superior accuracy at high sparsity ratios. Different from the existing works for sparse training, this current work reveals the importance of sparsity schemes on the performance of sparse training in terms of accuracy as well as training speed on real edge devices. On top of that, the paper proposes to employ data efficiency for further acceleration of sparse training. Our results suggest that unforgettable examples can be identified in-situ even during the dynamic exploration of sparsity masks in the sparse training process, and therefore can be removed for further training speedup on edge devices. Comparing with state-of-the-art (SOTA) works on accuracy, our MEST increases Top-1 accuracy significantly on ImageNet when using the same unstructured sparsity scheme. Systematical evaluation on accuracy, training speed, and memory footprint are conducted, where the proposed MEST framework consistently outperforms representative SOTA works. A reviewer strongly against our work based on his false assumptions and misunderstandings. On top of the previous submission, we employ data efficiency for further acceleration of sparse training. And we explore the impact of model sparsity, sparsity schemes, and sparse training algorithms on the number of removable training examples. Our codes are publicly available at: https://github.com/boone891214/MEST.
GRIM: A General, Real-Time Deep Learning Inference Framework for Mobile Devices based on Fine-Grained Structured Weight Sparsity
Aug 25, 2021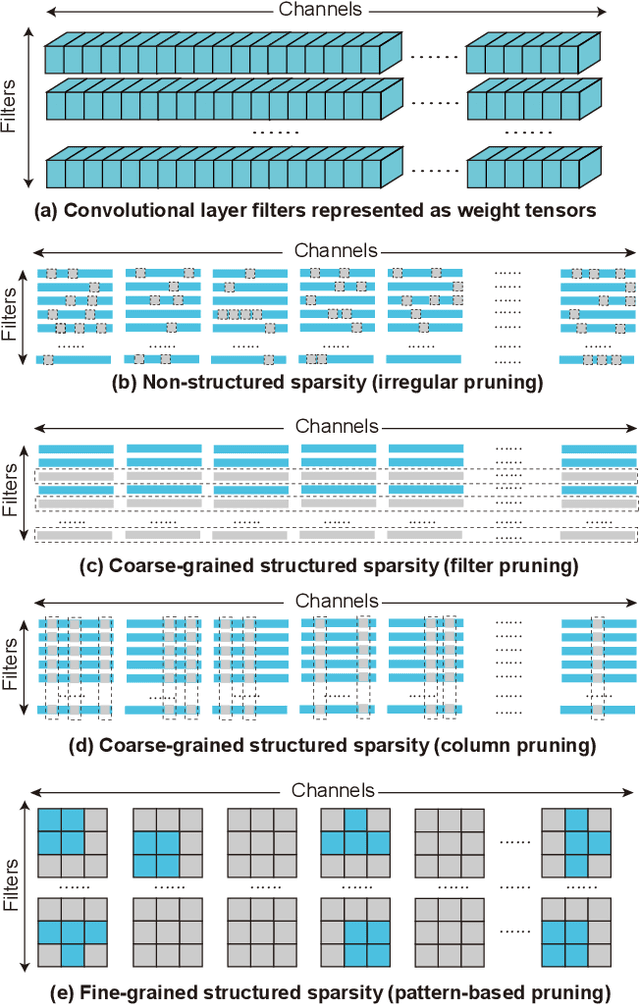
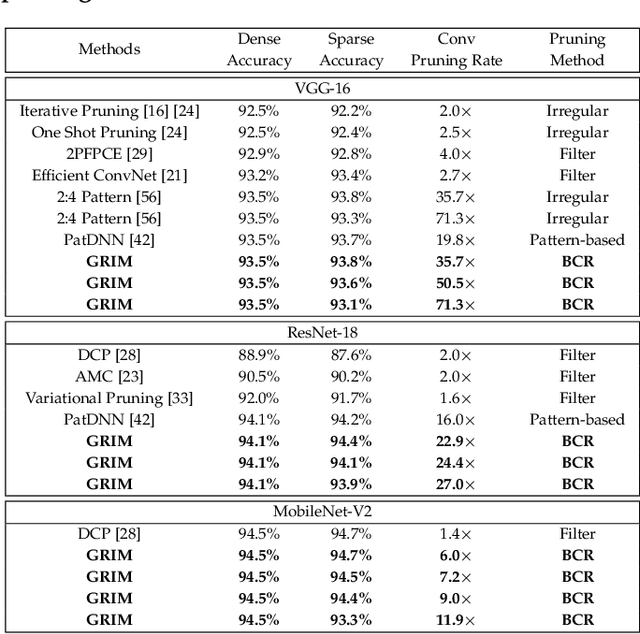
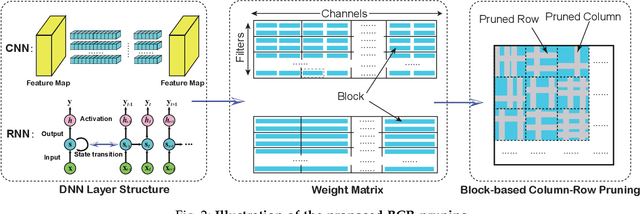
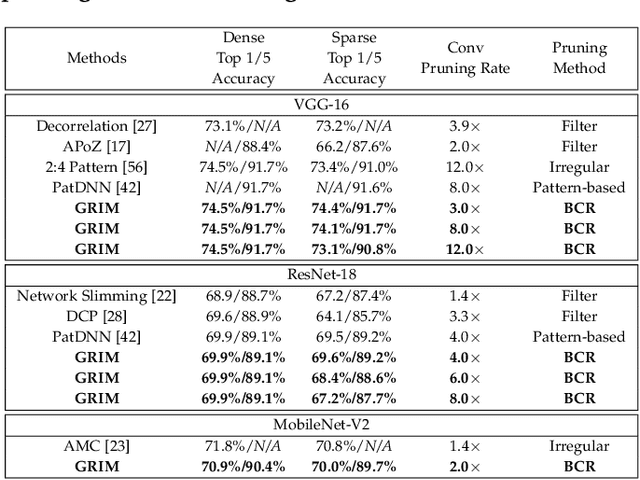
It is appealing but challenging to achieve real-time deep neural network (DNN) inference on mobile devices because even the powerful modern mobile devices are considered as ``resource-constrained'' when executing large-scale DNNs. It necessitates the sparse model inference via weight pruning, i.e., DNN weight sparsity, and it is desirable to design a new DNN weight sparsity scheme that can facilitate real-time inference on mobile devices while preserving a high sparse model accuracy. This paper designs a novel mobile inference acceleration framework GRIM that is General to both convolutional neural networks (CNNs) and recurrent neural networks (RNNs) and that achieves Real-time execution and high accuracy, leveraging fine-grained structured sparse model Inference and compiler optimizations for Mobiles. We start by proposing a new fine-grained structured sparsity scheme through the Block-based Column-Row (BCR) pruning. Based on this new fine-grained structured sparsity, our GRIM framework consists of two parts: (a) the compiler optimization and code generation for real-time mobile inference; and (b) the BCR pruning optimizations for determining pruning hyperparameters and performing weight pruning. We compare GRIM with Alibaba MNN, TVM, TensorFlow-Lite, a sparse implementation based on CSR, PatDNN, and ESE (a representative FPGA inference acceleration framework for RNNs), and achieve up to 14.08x speedup.
A Topological-Framework to Improve Analysis of Machine Learning Model Performance
Jul 09, 2021

As both machine learning models and the datasets on which they are evaluated have grown in size and complexity, the practice of using a few summary statistics to understand model performance has become increasingly problematic. This is particularly true in real-world scenarios where understanding model failure on certain subpopulations of the data is of critical importance. In this paper we propose a topological framework for evaluating machine learning models in which a dataset is treated as a "space" on which a model operates. This provides us with a principled way to organize information about model performance at both the global level (over the entire test set) and also the local level (on specific subpopulations). Finally, we describe a topological data structure, presheaves, which offer a convenient way to store and analyze model performance between different subpopulations.
Sanity Checks for Lottery Tickets: Does Your Winning Ticket Really Win the Jackpot?
Jul 01, 2021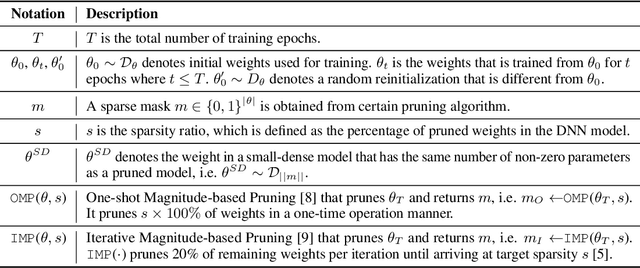
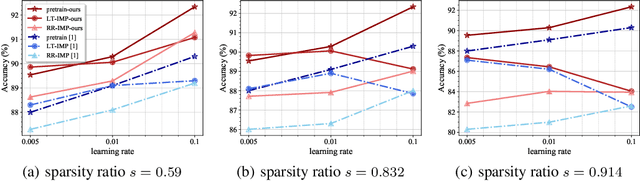
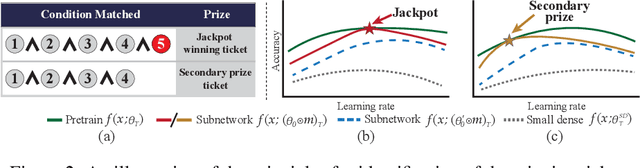

There have been long-standing controversies and inconsistencies over the experiment setup and criteria for identifying the "winning ticket" in literature. To reconcile such, we revisit the definition of lottery ticket hypothesis, with comprehensive and more rigorous conditions. Under our new definition, we show concrete evidence to clarify whether the winning ticket exists across the major DNN architectures and/or applications. Through extensive experiments, we perform quantitative analysis on the correlations between winning tickets and various experimental factors, and empirically study the patterns of our observations. We find that the key training hyperparameters, such as learning rate and training epochs, as well as the architecture characteristics such as capacities and residual connections, are all highly correlated with whether and when the winning tickets can be identified. Based on our analysis, we summarize a guideline for parameter settings in regards of specific architecture characteristics, which we hope to catalyze the research progress on the topic of lottery ticket hypothesis.