 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRT: Accelerating Reinforcement Learning via Speculative Rollout with Tree-Structured Cache
Jan 14, 2026We present Speculative Rollout with Tree-Structured Cache (SRT), a simple, model-free approach to accelerate on-policy reinforcement learning (RL) for language models without sacrificing distributional correctness. SRT exploits the empirical similarity of rollouts for the same prompt across training steps by storing previously generated continuations in a per-prompt tree-structured cache. During generation, the current policy uses this tree as the draft model for performing speculative decoding. To keep the cache fresh and improve draft model quality, SRT updates trees online from ongoing rollouts and proactively performs run-ahead generation during idle GPU bubbles. Integrated into standard RL pipelines (\textit{e.g.}, PPO, GRPO and DAPO) and multi-turn settings, SRT consistently reduces generation and step latency and lowers per-token inference cost, achieving up to 2.08x wall-clock time speedup during rollout.
Mesh-Attention: A New Communication-Efficient Distributed Attention with Improved Data Locality
Dec 24, 2025Distributed attention is a fundamental problem for scaling context window for Large Language Models (LLMs). The state-of-the-art method, Ring-Attention, suffers from scalability limitations due to its excessive communication traffic. This paper proposes a new distributed attention algorithm, Mesh-Attention, by rethinking the design space of distributed attention with a new matrix-based model. Our method assigns a two-dimensional tile -- rather than one-dimensional row or column -- of computation blocks to each GPU to achieve higher efficiency through lower communication-computation (CommCom) ratio. The general approach covers Ring-Attention as a special case, and allows the tuning of CommCom ratio with different tile shapes. Importantly, we propose a greedy algorithm that can efficiently search the scheduling space within the tile with restrictions that ensure efficient communication among GPUs. The theoretical analysis shows that Mesh-Attention leads to a much lower communication complexity and exhibits good scalability comparing to other current algorithms. Our extensive experiment results show that Mesh-Attention can achieve up to 3.4x speedup (2.9x on average) and reduce the communication volume by up to 85.4% (79.0% on average) on 256 GPUs. Our scalability results further demonstrate that Mesh-Attention sustains superior performance as the system scales, substantially reducing overhead in large-scale deployments. The results convincingly confirm the advantage of Mesh-Attention.
GreedySnake: Accelerating SSD-Offloaded LLM Training with Efficient Scheduling and Optimizer Step Overlapping
Dec 19, 2025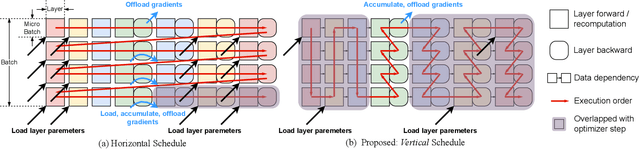
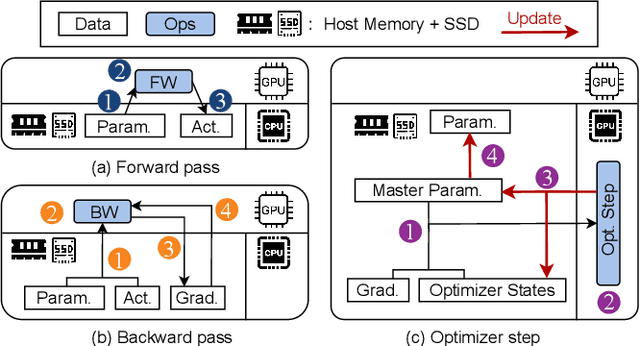
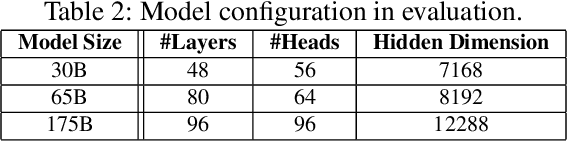
SSD-offloaded training offers a practical and promising approach to making LLM training cost-effective. Building on gradient accumulation with micro-batches, this paper introduces GreedySnake, a new SSD-offloaded training system that employs vertical scheduling, which executes all microbatches of a layer before proceeding to the next. Compared to existing systems that use horizontal scheduling (i.e., executing micro-batches sequentially), GreedySnake achieves higher training throughput with smaller batch sizes, bringing the system much closer to the ideal scenario predicted by the roofline model. To further mitigate the I/O bottleneck, GreedySnake overlaps part of the optimization step with the forward pass of the next iteration. Experimental results on A100 GPUs show that GreedySnake achieves saturated training throughput improvements over ZeRO-Infinity: 1.96x on 1 GPU and 1.93x on 4 GPUs for GPT-65B, and 2.53x on 1 GPU for GPT-175B. The code is open-sourced at https://github.com/npz7yyk/GreedySnake
Fine-Grained Embedding Dimension Optimization During Training for Recommender Systems
Jan 09, 2024



Huge embedding tables in modern Deep Learning Recommender Models (DLRM) require prohibitively large memory during training and inference. Aiming to reduce the memory footprint of training, this paper proposes FIne-grained In-Training Embedding Dimension optimization (FIITED). Given the observation that embedding vectors are not equally important, FIITED adjusts the dimension of each individual embedding vector continuously during training, assigning longer dimensions to more important embeddings while adapting to dynamic changes in data. A novel embedding storage system based on virtually-hashed physically-indexed hash tables is designed to efficiently implement the embedding dimension adjustment and effectively enable memory saving. Experiments on two industry models show that FIITED is able to reduce the size of embeddings by more than 65% while maintaining the trained model's quality, saving significantly more memory than a state-of-the-art in-training embedding pruning method. On public click-through rate prediction datasets, FIITED is able to prune up to 93.75%-99.75% embeddings without significant accuracy loss.
RobustState: Boosting Fidelity of Quantum State Preparation via Noise-Aware Variational Training
Nov 27, 2023



Quantum state preparation, a crucial subroutine in quantum computing, involves generating a target quantum state from initialized qubits. Arbitrary state preparation algorithms can be broadly categorized into arithmetic decomposition (AD) and variational quantum state preparation (VQSP). AD employs a predefined procedure to decompose the target state into a series of gates, whereas VQSP iteratively tunes ansatz parameters to approximate target state. VQSP is particularly apt for Noisy-Intermediate Scale Quantum (NISQ) machines due to its shorter circuits. However, achieving noise-robust parameter optimization still remains challenging. We present RobustState, a novel VQSP training methodology that combines high robustness with high training efficiency. The core idea involves utilizing measurement outcomes from real machines to perform back-propagation through classical simulators, thus incorporating real quantum noise into gradient calculations. RobustState serves as a versatile, plug-and-play technique applicable for training parameters from scratch or fine-tuning existing parameters to enhance fidelity on target machines. It is adaptable to various ansatzes at both gate and pulse levels and can even benefit other variational algorithms, such as variational unitary synthesis. Comprehensive evaluation of RobustState on state preparation tasks for 4 distinct quantum algorithms using 10 real quantum machines demonstrates a coherent error reduction of up to 7.1 $\times$ and state fidelity improvement of up to 96\% and 81\% for 4-Q and 5-Q states, respectively. On average, RobustState improves fidelity by 50\% and 72\% for 4-Q and 5-Q states compared to baseline approaches.
GNNPipe: Accelerating Distributed Full-Graph GNN Training with Pipelined Model Parallelism
Aug 19, 2023Current distributed full-graph GNN training methods adopt a variant of data parallelism, namely graph parallelism, in which the whole graph is divided into multiple partitions (subgraphs) and each GPU processes one of them. This incurs high communication overhead because of the inter-partition message passing at each layer. To this end, we proposed a new training method named GNNPipe that adopts model parallelism instead, which has a lower worst-case asymptotic communication complexity than graph parallelism. To ensure high GPU utilization, we proposed to combine model parallelism with a chunk-based pipelined training method, in which each GPU processes a different chunk of graph data at different layers concurrently. We further proposed hybrid parallelism that combines model and graph parallelism when the model-level parallelism is insufficient. We also introduced several tricks to ensure convergence speed and model accuracies to accommodate embedding staleness introduced by pipelining. Extensive experiments show that our method reduces the per-epoch training time by up to 2.45x (on average 2.03x) and reduces the communication volume and overhead by up to 22.51x and 27.21x (on average 10.27x and 14.96x), respectively, while achieving a comparable level of model accuracy and convergence speed compared to graph parallelism.
QuEst: Graph Transformer for Quantum Circuit Reliability Estimation
Oct 30, 2022Among different quantum algorithms, PQC for QML show promises on near-term devices. To facilitate the QML and PQC research, a recent python library called TorchQuantum has been released. It can construct, simulate, and train PQC for machine learning tasks with high speed and convenient debugging supports. Besides quantum for ML, we want to raise the community's attention on the reversed direction: ML for quantum. Specifically, the TorchQuantum library also supports using data-driven ML models to solve problems in quantum system research, such as predicting the impact of quantum noise on circuit fidelity and improving the quantum circuit compilation efficiency. This paper presents a case study of the ML for quantum part. Since estimating the noise impact on circuit reliability is an essential step toward understanding and mitigating noise, we propose to leverage classical ML to predict noise impact on circuit fidelity. Inspired by the natural graph representation of quantum circuits, we propose to leverage a graph transformer model to predict the noisy circuit fidelity. We firstly collect a large dataset with a variety of quantum circuits and obtain their fidelity on noisy simulators and real machines. Then we embed each circuit into a graph with gate and noise properties as node features, and adopt a graph transformer to predict the fidelity. Evaluated on 5 thousand random and algorithm circuits, the graph transformer predictor can provide accurate fidelity estimation with RMSE error 0.04 and outperform a simple neural network-based model by 0.02 on average. It can achieve 0.99 and 0.95 R$^2$ scores for random and algorithm circuits, respectively. Compared with circuit simulators, the predictor has over 200X speedup for estimating the fidelity.
PAN: Pulse Ansatz on NISQ Machines
Aug 02, 2022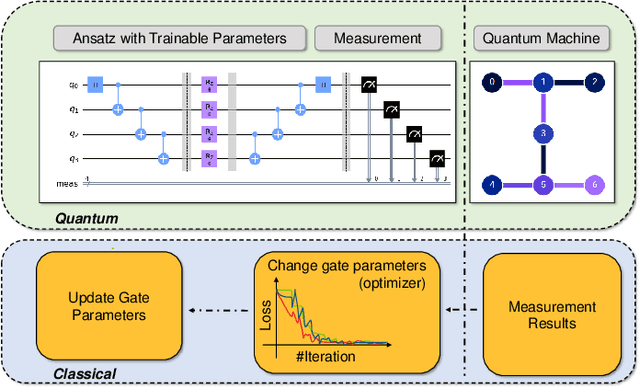
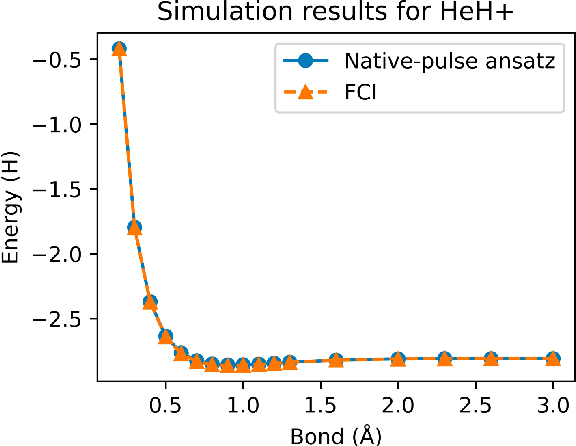

Variational quantum algorithms (VQAs) have demonstrated great potentials in the NISQ era. In the workflow of VQA, the parameters of ansatz are iteratively updated to approximate the desired quantum states. We have seen various efforts to draft better ansatz with less gates. In quantum computers, the gate ansatz will eventually be transformed into control signals such as microwave pulses on transmons. And the control pulses need elaborate calibration to minimize the errors such as over-rotation and under-rotation. In the case of VQAs, this procedure will introduce redundancy, but the variational properties of VQAs can naturally handle problems of over-rotation and under-rotation by updating the amplitude and frequency parameters. Therefore, we propose PAN, a native-pulse ansatz generator framework for VQAs. We generate native-pulse ansatz with trainable parameters for amplitudes and frequencies. In our proposed PAN, we are tuning parametric pulses, which are natively supported on NISQ computers. Considering that parameter-shift rules do not hold for native-pulse ansatz, we need to deploy non-gradient optimizers. To constrain the number of parameters sent to the optimizer, we adopt a progressive way to generate our native-pulse ansatz. Experiments are conducted on both simulators and quantum devices to validate our methods. When adopted on NISQ machines, PAN obtained improved the performance with decreased latency by an average of 86%. PAN is able to achieve 99.336% and 96.482% accuracy for VQE tasks on H2 and HeH+ respectively, even with considerable noises in NISQ machines.
GRIM: A General, Real-Time Deep Learning Inference Framework for Mobile Devices based on Fine-Grained Structured Weight Sparsity
Aug 25, 2021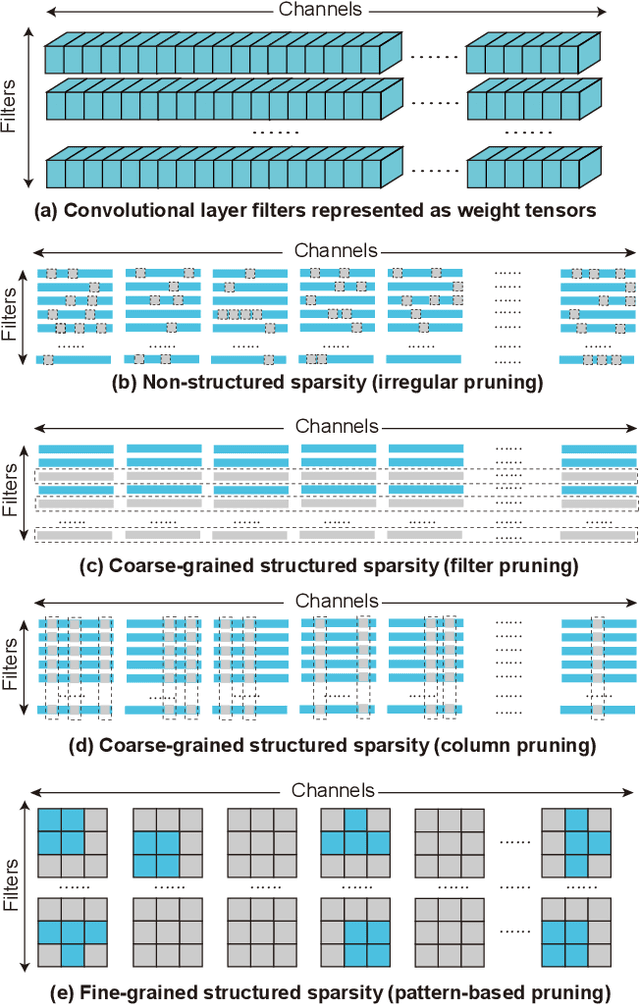
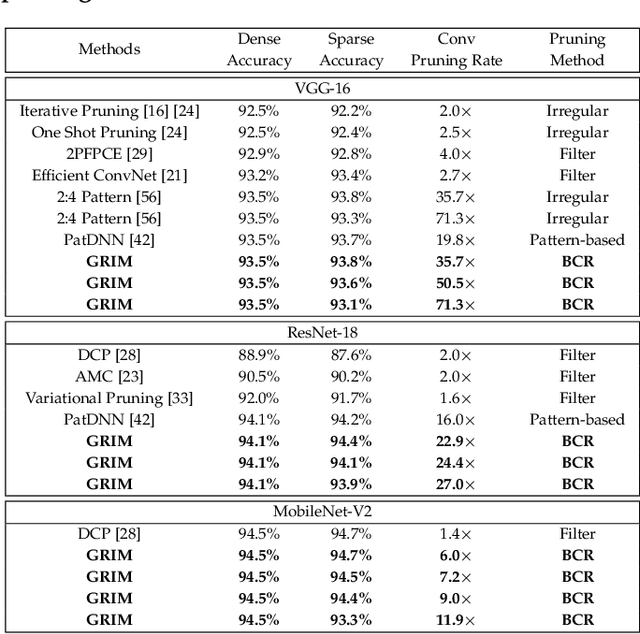
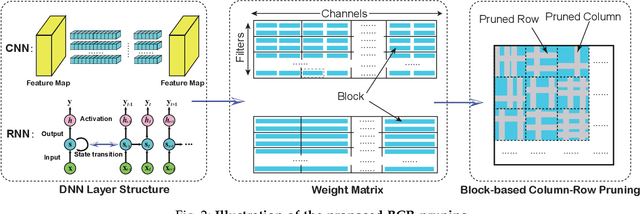
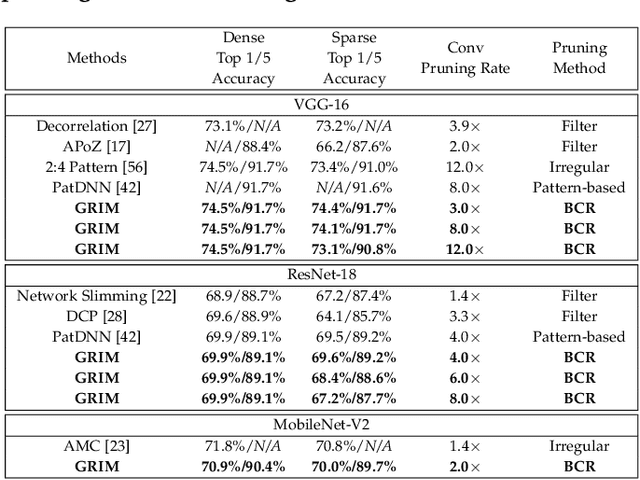
It is appealing but challenging to achieve real-time deep neural network (DNN) inference on mobile devices because even the powerful modern mobile devices are considered as ``resource-constrained'' when executing large-scale DNNs. It necessitates the sparse model inference via weight pruning, i.e., DNN weight sparsity, and it is desirable to design a new DNN weight sparsity scheme that can facilitate real-time inference on mobile devices while preserving a high sparse model accuracy. This paper designs a novel mobile inference acceleration framework GRIM that is General to both convolutional neural networks (CNNs) and recurrent neural networks (RNNs) and that achieves Real-time execution and high accuracy, leveraging fine-grained structured sparse model Inference and compiler optimizations for Mobiles. We start by proposing a new fine-grained structured sparsity scheme through the Block-based Column-Row (BCR) pruning. Based on this new fine-grained structured sparsity, our GRIM framework consists of two parts: (a) the compiler optimization and code generation for real-time mobile inference; and (b) the BCR pruning optimizations for determining pruning hyperparameters and performing weight pruning. We compare GRIM with Alibaba MNN, TVM, TensorFlow-Lite, a sparse implementation based on CSR, PatDNN, and ESE (a representative FPGA inference acceleration framework for RNNs), and achieve up to 14.08x speedup.
FORMS: Fine-grained Polarized ReRAM-based In-situ Computation for Mixed-signal DNN Accelerator
Jun 16, 2021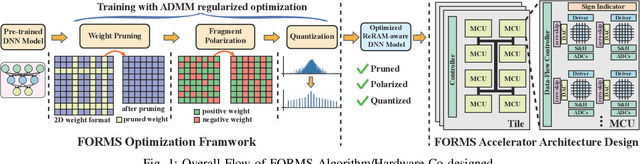
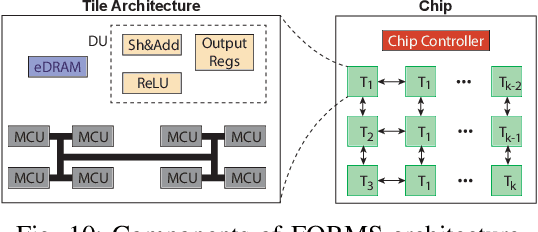
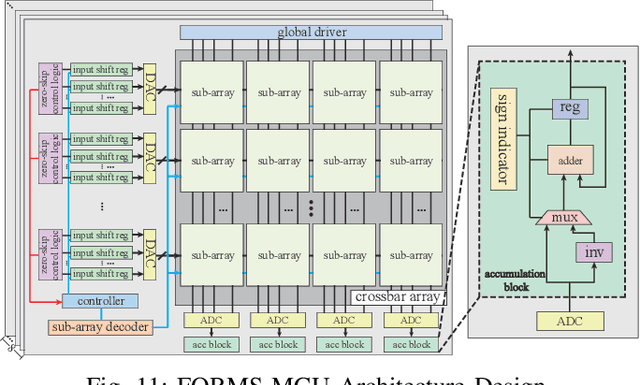

Recent works demonstrated the promise of using resistive random access memory (ReRAM) as an emerging technology to perform inherently parallel analog domain in-situ matrix-vector multiplication -- the intensive and key computation in DNNs. With weights stored in the ReRAM crossbar cells as conductance, when the input vector is applied to word lines, the matrix-vector multiplication results can be generated as the current in bit lines. A key problem is that the weight can be either positive or negative, but the in-situ computation assumes all cells on each crossbar column with the same sign. The current architectures either use two ReRAM crossbars for positive and negative weights, or add an offset to weights so that all values become positive. Neither solution is ideal: they either double the cost of crossbars, or incur extra offset circuity. To better solve this problem, this paper proposes FORMS, a fine-grained ReRAM-based DNN accelerator with polarized weights. Instead of trying to represent the positive/negative weights, our key design principle is to enforce exactly what is assumed in the in-situ computation -- ensuring that all weights in the same column of a crossbar have the same sign. It naturally avoids the cost of an additional crossbar. Such weights can be nicely generated using alternating direction method of multipliers (ADMM) regularized optimization, which can exactly enforce certain patterns in DNN weights. To achieve high accuracy, we propose to use fine-grained sub-array columns, which provide a unique opportunity for input zero-skipping, significantly avoiding unnecessary computations. It also makes the hardware much easier to implement. Putting all together, with the same optimized models, FORMS achieves significant throughput improvement and speed up in frame per second over ISAAC with similar area cost.