 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-resource Speech Translation and Recognition with LLMs
Dec 24, 2024


Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2\%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
SpeechGuard: Exploring the Adversarial Robustness of Multimodal Large Language Models
May 14, 2024



Integrated Speech and Large Language Models (SLMs) that can follow speech instructions and generate relevant text responses have gained popularity lately. However, the safety and robustness of these models remains largely unclear. In this work, we investigate the potential vulnerabilities of such instruction-following speech-language models to adversarial attacks and jailbreaking. Specifically, we design algorithms that can generate adversarial examples to jailbreak SLMs in both white-box and black-box attack settings without human involvement. Additionally, we propose countermeasures to thwart such jailbreaking attacks. Our models, trained on dialog data with speech instructions, achieve state-of-the-art performance on spoken question-answering task, scoring over 80% on both safety and helpfulness metrics. Despite safety guardrails, experiments on jailbreaking demonstrate the vulnerability of SLMs to adversarial perturbations and transfer attacks, with average attack success rates of 90% and 10% respectively when evaluated on a dataset of carefully designed harmful questions spanning 12 different toxic categories. However, we demonstrate that our proposed countermeasures reduce the attack success significantly.
MILAN: Masked Image Pretraining on Language Assisted Representation
Aug 15, 2022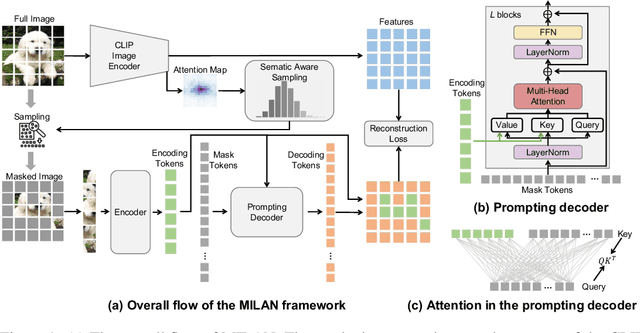
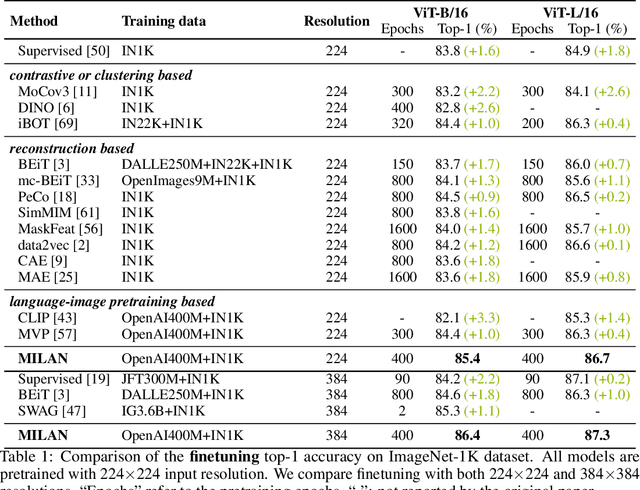

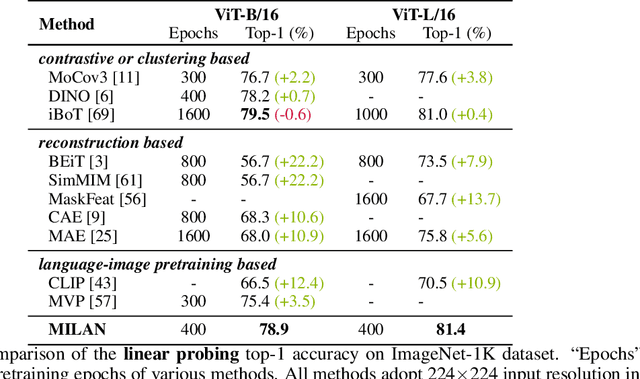
Self-attention based transformer models have been dominating many computer vision tasks in the past few years. Their superb model qualities heavily depend on the excessively large labeled image datasets. In order to reduce the reliance on large labeled datasets, reconstruction based masked autoencoders are gaining popularity, which learn high quality transferable representations from unlabeled images. For the same purpose, recent weakly supervised image pretraining methods explore language supervision from text captions accompanying the images. In this work, we propose masked image pretraining on language assisted representation, dubbed as MILAN. Instead of predicting raw pixels or low level features, our pretraining objective is to reconstruct the image features with substantial semantic signals that are obtained using caption supervision. Moreover, to accommodate our reconstruction target, we propose a more efficient prompting decoder architecture and a semantic aware mask sampling mechanism, which further advance the transfer performance of the pretrained model. Experimental results demonstrate that MILAN delivers higher accuracy than the previous works. When the masked autoencoder is pretrained and finetuned on ImageNet-1K dataset with an input resolution of 224x224, MILAN achieves a top-1 accuracy of 85.4% on ViTB/16, surpassing previous state-of-the-arts by 1%. In the downstream semantic segmentation task, MILAN achieves 52.7 mIoU using ViT-B/16 backbone on ADE20K dataset, outperforming previous masked pretraining results by 4 points.
Meta-Learning the Difference: Preparing Large Language Models for Efficient Adaptation
Jul 07, 2022Large pretrained language models (PLMs) are often domain- or task-adapted via fine-tuning or prompting. Finetuning requires modifying all of the parameters and having enough data to avoid overfitting while prompting requires no training and few examples but limits performance. Instead, we prepare PLMs for data- and parameter-efficient adaptation by learning to learn the difference between general and adapted PLMs. This difference is expressed in terms of model weights and sublayer structure through our proposed dynamic low-rank reparameterization and learned architecture controller. Experiments on few-shot dialogue completion, low-resource abstractive summarization, and multi-domain language modeling show improvements in adaptation time and performance over direct finetuning or preparation via domain-adaptive pretraining. Ablations show our task-adaptive reparameterization (TARP) and model search (TAMS) components individually improve on other parameter-efficient transfer like adapters and structure-learning methods like learned sparsification.
CHEX: CHannel EXploration for CNN Model Compression
Mar 29, 2022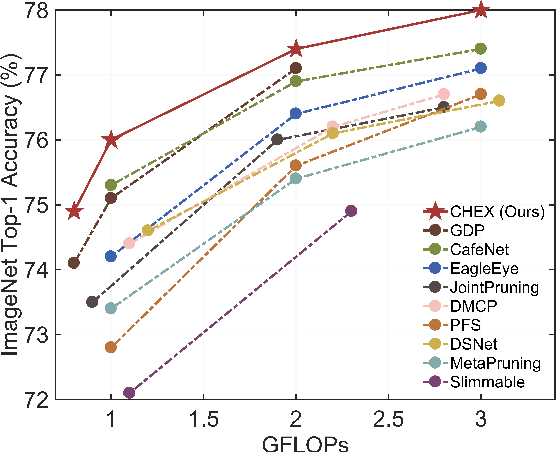
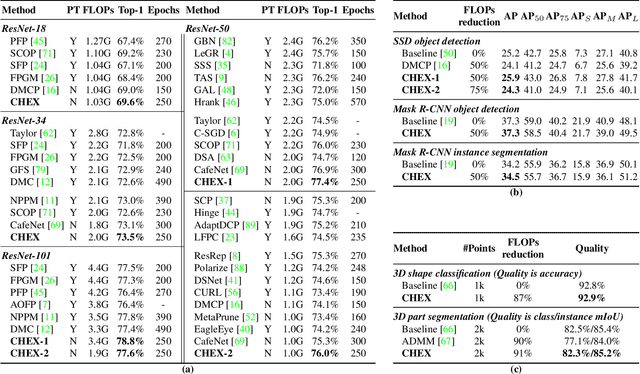
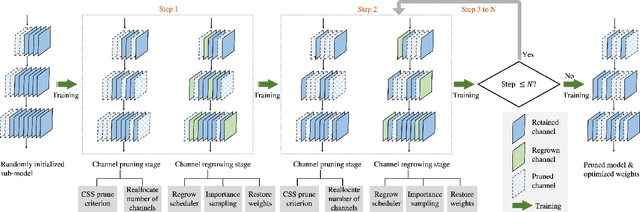

Channel pruning has been broadly recognized as an effective technique to reduce the computation and memory cost of deep convolutional neural networks. However, conventional pruning methods have limitations in that: they are restricted to pruning process only, and they require a fully pre-trained large model. Such limitations may lead to sub-optimal model quality as well as excessive memory and training cost. In this paper, we propose a novel Channel Exploration methodology, dubbed as CHEX, to rectify these problems. As opposed to pruning-only strategy, we propose to repeatedly prune and regrow the channels throughout the training process, which reduces the risk of pruning important channels prematurely. More exactly: From intra-layer's aspect, we tackle the channel pruning problem via a well known column subset selection (CSS) formulation. From inter-layer's aspect, our regrowing stages open a path for dynamically re-allocating the number of channels across all the layers under a global channel sparsity constraint. In addition, all the exploration process is done in a single training from scratch without the need of a pre-trained large model. Experimental results demonstrate that CHEX can effectively reduce the FLOPs of diverse CNN architectures on a variety of computer vision tasks, including image classification, object detection, instance segmentation, and 3D vision. For example, our compressed ResNet-50 model on ImageNet dataset achieves 76% top1 accuracy with only 25% FLOPs of the original ResNet-50 model, outperforming previous state-of-the-art channel pruning methods. The checkpoints and code are available at here .
Multi-Dimensional Model Compression of Vision Transformer
Dec 31, 2021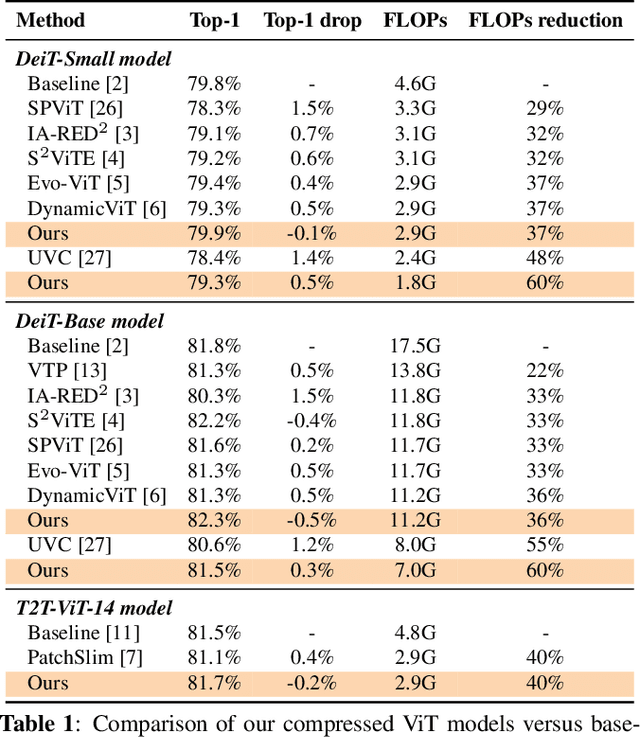
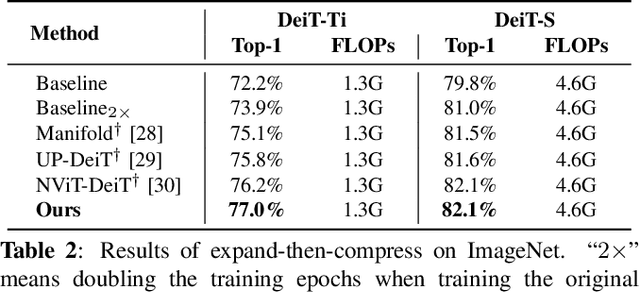


Vision transformers (ViT) have recently attracted considerable attentions, but the huge computational cost remains an issue for practical deployment. Previous ViT pruning methods tend to prune the model along one dimension solely, which may suffer from excessive reduction and lead to sub-optimal model quality. In contrast, we advocate a multi-dimensional ViT compression paradigm, and propose to harness the redundancy reduction from attention head, neuron and sequence dimensions jointly. We firstly propose a statistical dependence based pruning criterion that is generalizable to different dimensions for identifying deleterious components. Moreover, we cast the multi-dimensional compression as an optimization, learning the optimal pruning policy across the three dimensions that maximizes the compressed model's accuracy under a computational budget. The problem is solved by our adapted Gaussian process search with expected improvement. Experimental results show that our method effectively reduces the computational cost of various ViT models. For example, our method reduces 40\% FLOPs without top-1 accuracy loss for DeiT and T2T-ViT models, outperforming previous state-of-the-arts.
Few-shot Learning via Dependency Maximization and Instance Discriminant Analysis
Sep 07, 2021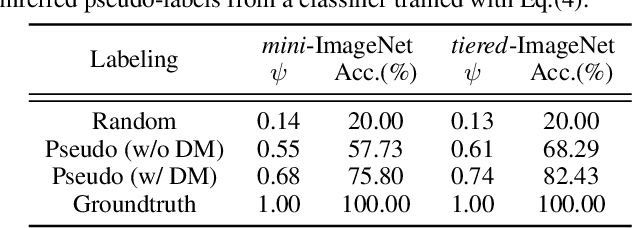
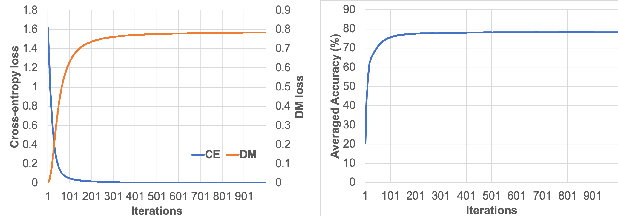
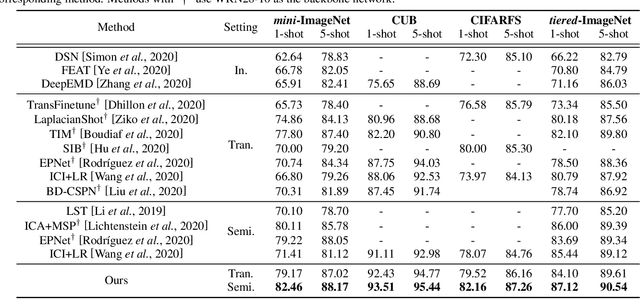
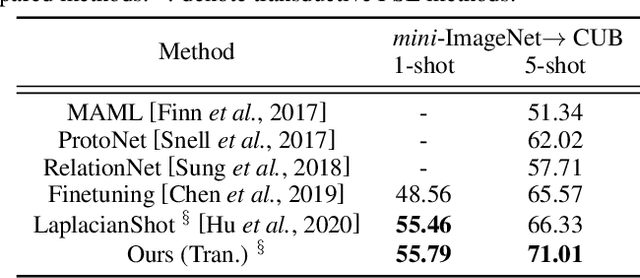
We study the few-shot learning (FSL) problem, where a model learns to recognize new objects with extremely few labeled training data per category. Most of previous FSL approaches resort to the meta-learning paradigm, where the model accumulates inductive bias through learning many training tasks so as to solve a new unseen few-shot task. In contrast, we propose a simple approach to exploit unlabeled data accompanying the few-shot task for improving few-shot performance. Firstly, we propose a Dependency Maximization method based on the Hilbert-Schmidt norm of the cross-covariance operator, which maximizes the statistical dependency between the embedded feature of those unlabeled data and their label predictions, together with the supervised loss over the support set. We then use the obtained model to infer the pseudo-labels for those unlabeled data. Furthermore, we propose anInstance Discriminant Analysis to evaluate the credibility of each pseudo-labeled example and select the most faithful ones into an augmented support set to retrain the model as in the first step. We iterate the above process until the pseudo-labels for the unlabeled data becomes stable. Following the standard transductive and semi-supervised FSL setting, our experiments show that the proposed method out-performs previous state-of-the-art methods on four widely used benchmarks, including mini-ImageNet, tiered-ImageNet, CUB, and CIFARFS.
Effective Model Sparsification by Scheduled Grow-and-Prune Methods
Jun 18, 2021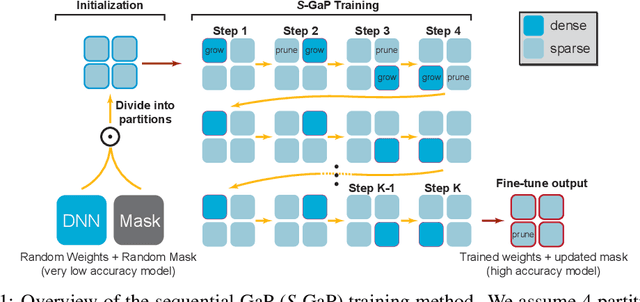

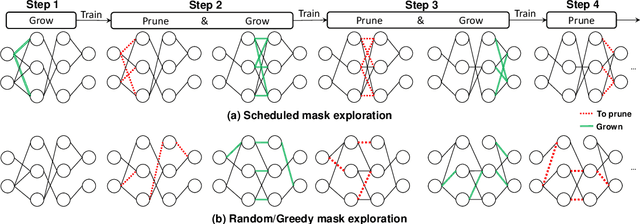
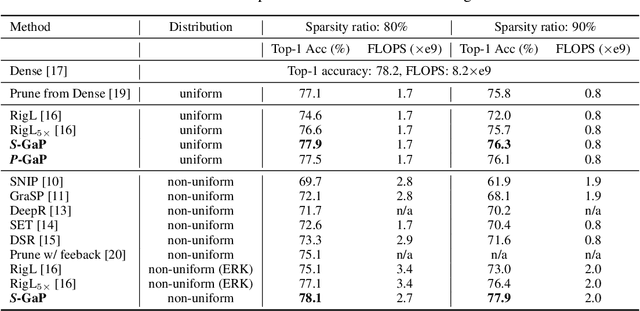
Deep neural networks (DNNs) are effective in solving many real-world problems. Larger DNN models usually exhibit better quality (e.g., accuracy) but their excessive computation results in long training and inference time. Model sparsification can reduce the computation and memory cost while maintaining model quality. Most existing sparsification algorithms unidirectionally remove weights, while others randomly or greedily explore a small subset of weights in each layer. The inefficiency of the algorithms reduces the achievable sparsity level. In addition, many algorithms still require pre-trained dense models and thus suffer from large memory footprint and long training time. In this paper, we propose a novel scheduled grow-and-prune (GaP) methodology without pre-training the dense models. It addresses the shortcomings of the previous works by repeatedly growing a subset of layers to dense and then pruning back to sparse after some training. Experiments have shown that such models can match or beat the quality of highly optimized dense models at 80% sparsity on a variety of tasks, such as image classification, objective detection, 3D object part segmentation, and translation. They also outperform other state-of-the-art (SOTA) pruning methods, including pruning from pre-trained dense models. As an example, a 90% sparse ResNet-50 obtained via GaP achieves 77.9% top-1 accuracy on ImageNet, improving the SOTA results by 1.5%.
A Feature-map Discriminant Perspective for Pruning Deep Neural Networks
May 28, 2020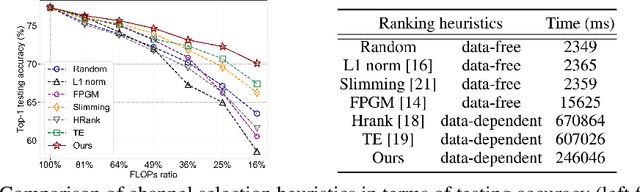
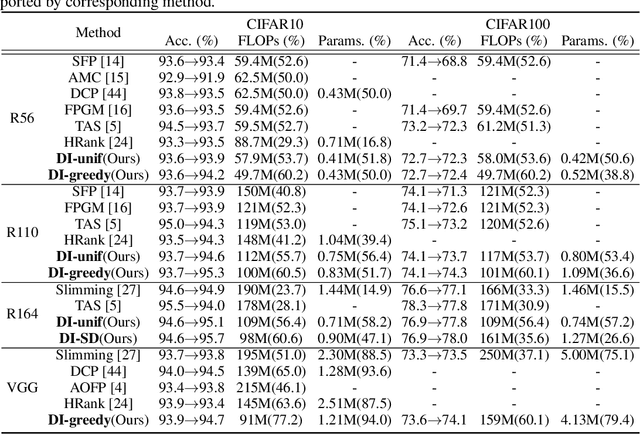
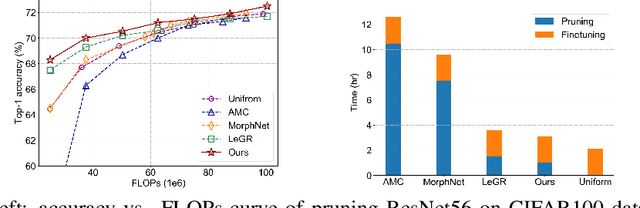
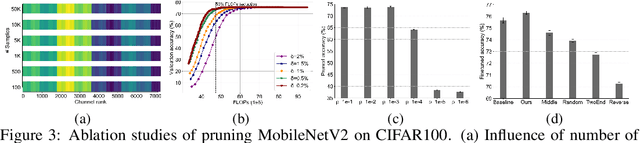
Network pruning has become the de facto tool to accelerate deep neural networks for mobile and edge applications. Recently, feature-map discriminant based channel pruning has shown promising results, as it aligns well with the CNN objective of differentiating multiple classes and offers better interpretability of the pruning decision. However, existing discriminant-based methods are challenged by computation inefficiency, as there is a lack of theoretical guidance on quantifying the feature-map discriminant power. In this paper, we present a new mathematical formulation to accurately and efficiently quantify the feature-map discriminativeness, which gives rise to a novel criterion,Discriminant Information(DI). We analyze the theoretical property of DI, specifically the non-decreasing property, that makes DI a valid selection criterion. DI-based pruning removes channels with minimum influence to DI value, as they contain little information regarding to the discriminant power. The versatility of DI criterion also enables an intra-layer mixed precision quantization to further compress the network. Moreover, we propose a DI-based greedy pruning algorithm and structure distillation technique to automatically decide the pruned structure that satisfies certain resource budget, which is a common requirement in reality. Extensive experiments demonstratethe effectiveness of our method: our pruned ResNet50 on ImageNet achieves 44% FLOPs reduction without any Top-1 accuracy loss compared to unpruned model
Scalable Kernel Learning via the Discriminant Information
Sep 23, 2019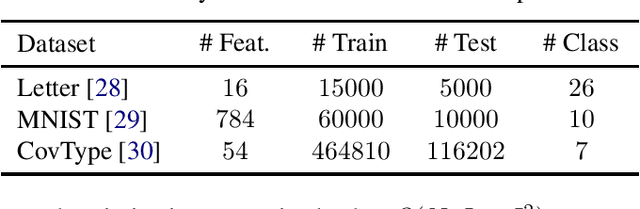
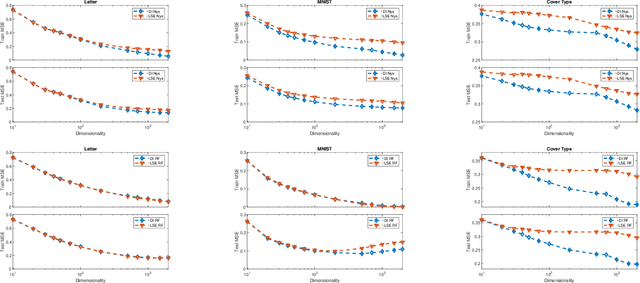
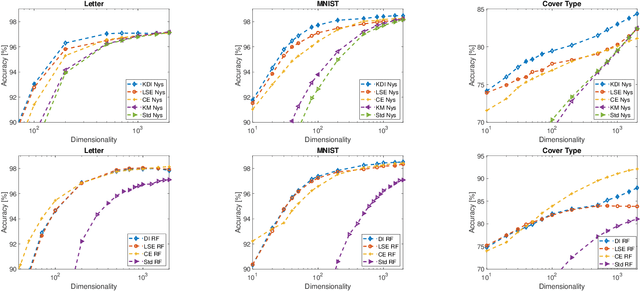
Kernel approximation methods have been popular techniques for scalable kernel based learning. They create explicit, low-dimensional kernel feature maps to deal with the high computational and memory complexity of standard techniques. This work studies a supervised kernel learning methodology to optimize such mappings. We utilize the Discriminant Information criterion, a measure of class separability, which is extended to cover a wider range of kernels. By exploiting the connection of this criterion to the minimum Kernel Ridge Regression loss, we propose a novel training strategy that is especially suitable for stochastic gradient methods, allowing kernel optimization to scale to large datasets. Experimental results on 3 datasets showcase that our techniques can improve optimization and generalization performances over state of the art kernel learning methods.