 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMILAN: Masked Image Pretraining on Language Assisted Representation
Aug 15, 2022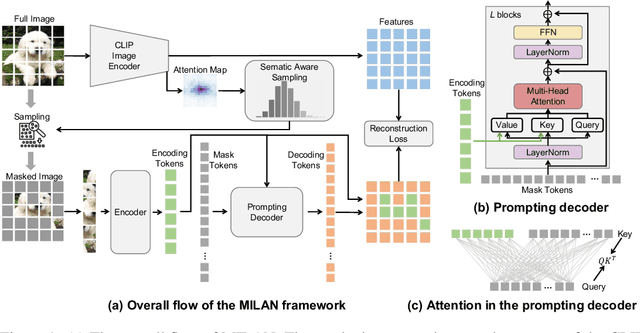
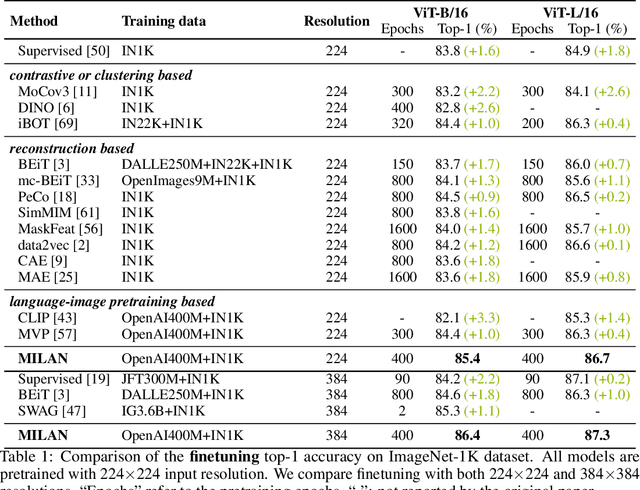

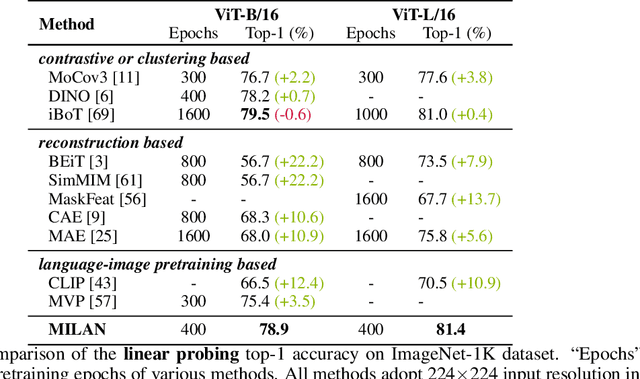
Self-attention based transformer models have been dominating many computer vision tasks in the past few years. Their superb model qualities heavily depend on the excessively large labeled image datasets. In order to reduce the reliance on large labeled datasets, reconstruction based masked autoencoders are gaining popularity, which learn high quality transferable representations from unlabeled images. For the same purpose, recent weakly supervised image pretraining methods explore language supervision from text captions accompanying the images. In this work, we propose masked image pretraining on language assisted representation, dubbed as MILAN. Instead of predicting raw pixels or low level features, our pretraining objective is to reconstruct the image features with substantial semantic signals that are obtained using caption supervision. Moreover, to accommodate our reconstruction target, we propose a more efficient prompting decoder architecture and a semantic aware mask sampling mechanism, which further advance the transfer performance of the pretrained model. Experimental results demonstrate that MILAN delivers higher accuracy than the previous works. When the masked autoencoder is pretrained and finetuned on ImageNet-1K dataset with an input resolution of 224x224, MILAN achieves a top-1 accuracy of 85.4% on ViTB/16, surpassing previous state-of-the-arts by 1%. In the downstream semantic segmentation task, MILAN achieves 52.7 mIoU using ViT-B/16 backbone on ADE20K dataset, outperforming previous masked pretraining results by 4 points.
CHEX: CHannel EXploration for CNN Model Compression
Mar 29, 2022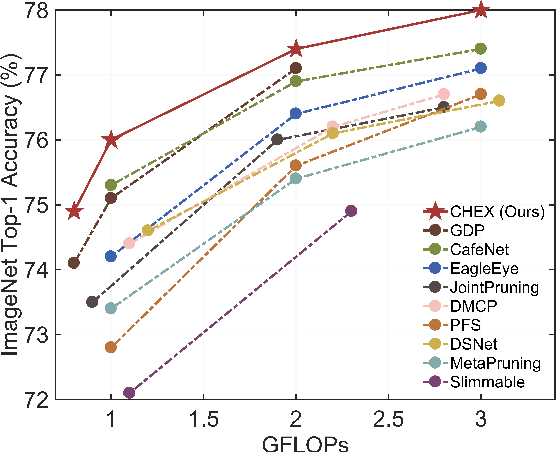
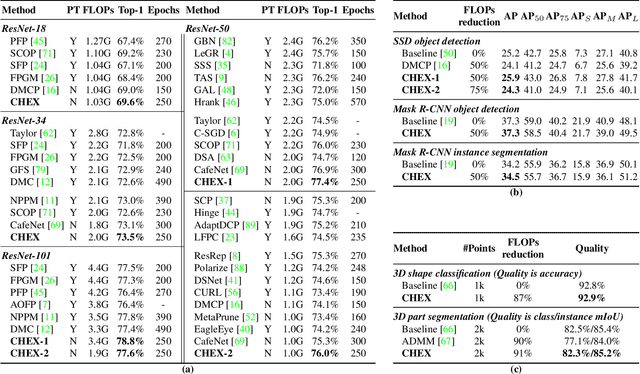
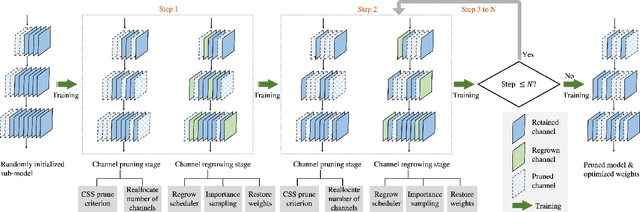

Channel pruning has been broadly recognized as an effective technique to reduce the computation and memory cost of deep convolutional neural networks. However, conventional pruning methods have limitations in that: they are restricted to pruning process only, and they require a fully pre-trained large model. Such limitations may lead to sub-optimal model quality as well as excessive memory and training cost. In this paper, we propose a novel Channel Exploration methodology, dubbed as CHEX, to rectify these problems. As opposed to pruning-only strategy, we propose to repeatedly prune and regrow the channels throughout the training process, which reduces the risk of pruning important channels prematurely. More exactly: From intra-layer's aspect, we tackle the channel pruning problem via a well known column subset selection (CSS) formulation. From inter-layer's aspect, our regrowing stages open a path for dynamically re-allocating the number of channels across all the layers under a global channel sparsity constraint. In addition, all the exploration process is done in a single training from scratch without the need of a pre-trained large model. Experimental results demonstrate that CHEX can effectively reduce the FLOPs of diverse CNN architectures on a variety of computer vision tasks, including image classification, object detection, instance segmentation, and 3D vision. For example, our compressed ResNet-50 model on ImageNet dataset achieves 76% top1 accuracy with only 25% FLOPs of the original ResNet-50 model, outperforming previous state-of-the-art channel pruning methods. The checkpoints and code are available at here .
Multi-Dimensional Model Compression of Vision Transformer
Dec 31, 2021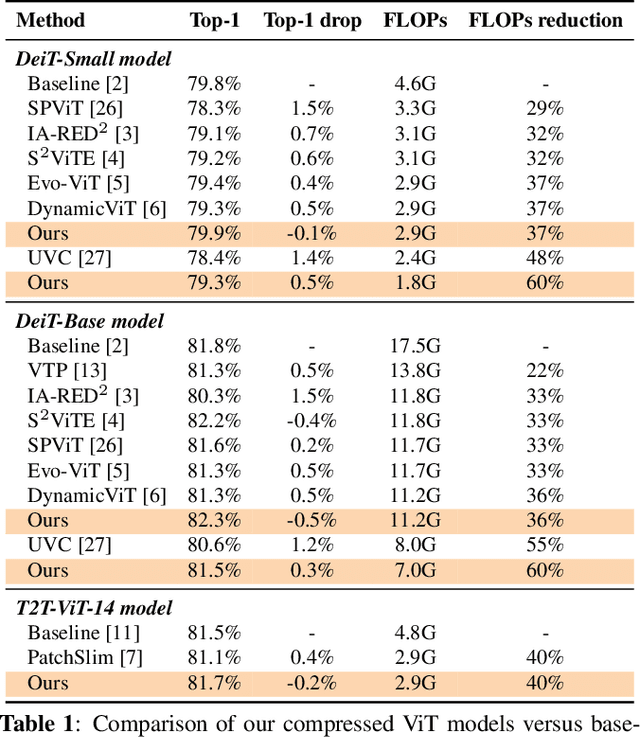
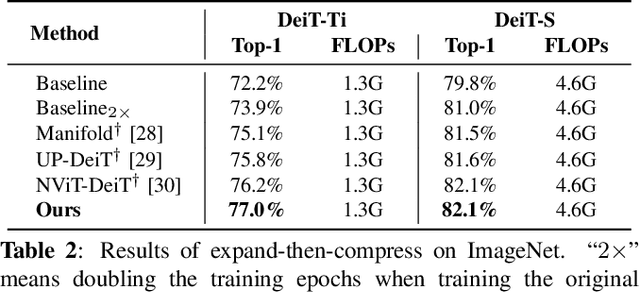


Vision transformers (ViT) have recently attracted considerable attentions, but the huge computational cost remains an issue for practical deployment. Previous ViT pruning methods tend to prune the model along one dimension solely, which may suffer from excessive reduction and lead to sub-optimal model quality. In contrast, we advocate a multi-dimensional ViT compression paradigm, and propose to harness the redundancy reduction from attention head, neuron and sequence dimensions jointly. We firstly propose a statistical dependence based pruning criterion that is generalizable to different dimensions for identifying deleterious components. Moreover, we cast the multi-dimensional compression as an optimization, learning the optimal pruning policy across the three dimensions that maximizes the compressed model's accuracy under a computational budget. The problem is solved by our adapted Gaussian process search with expected improvement. Experimental results show that our method effectively reduces the computational cost of various ViT models. For example, our method reduces 40\% FLOPs without top-1 accuracy loss for DeiT and T2T-ViT models, outperforming previous state-of-the-arts.
Few-shot Learning via Dependency Maximization and Instance Discriminant Analysis
Sep 07, 2021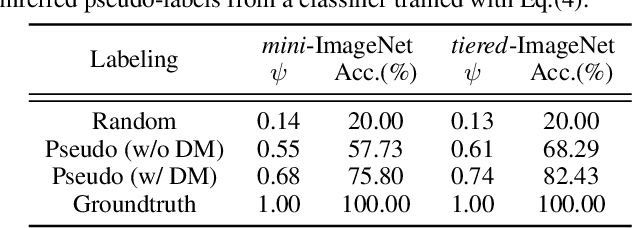
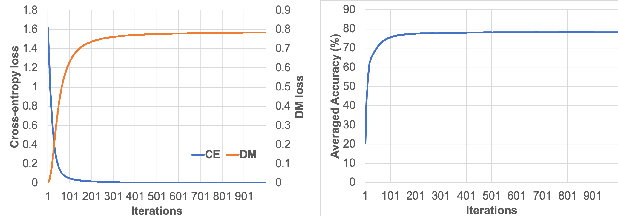
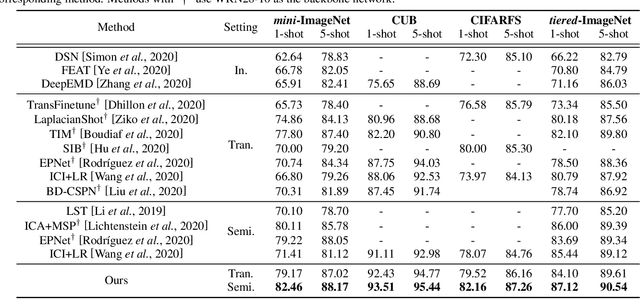
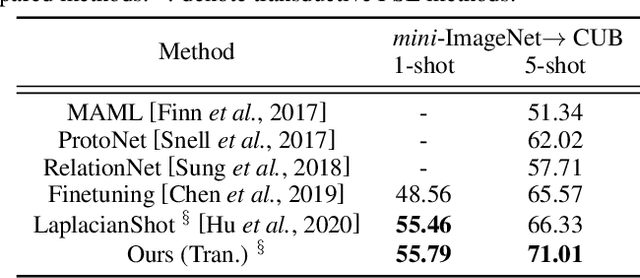
We study the few-shot learning (FSL) problem, where a model learns to recognize new objects with extremely few labeled training data per category. Most of previous FSL approaches resort to the meta-learning paradigm, where the model accumulates inductive bias through learning many training tasks so as to solve a new unseen few-shot task. In contrast, we propose a simple approach to exploit unlabeled data accompanying the few-shot task for improving few-shot performance. Firstly, we propose a Dependency Maximization method based on the Hilbert-Schmidt norm of the cross-covariance operator, which maximizes the statistical dependency between the embedded feature of those unlabeled data and their label predictions, together with the supervised loss over the support set. We then use the obtained model to infer the pseudo-labels for those unlabeled data. Furthermore, we propose anInstance Discriminant Analysis to evaluate the credibility of each pseudo-labeled example and select the most faithful ones into an augmented support set to retrain the model as in the first step. We iterate the above process until the pseudo-labels for the unlabeled data becomes stable. Following the standard transductive and semi-supervised FSL setting, our experiments show that the proposed method out-performs previous state-of-the-art methods on four widely used benchmarks, including mini-ImageNet, tiered-ImageNet, CUB, and CIFARFS.
A Novel Multi-Stage Training Approach for Human Activity Recognition from Multimodal Wearable Sensor Data Using Deep Neural Network
Jan 03, 2021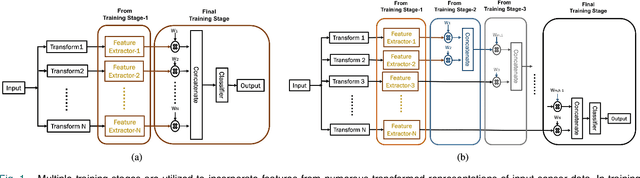
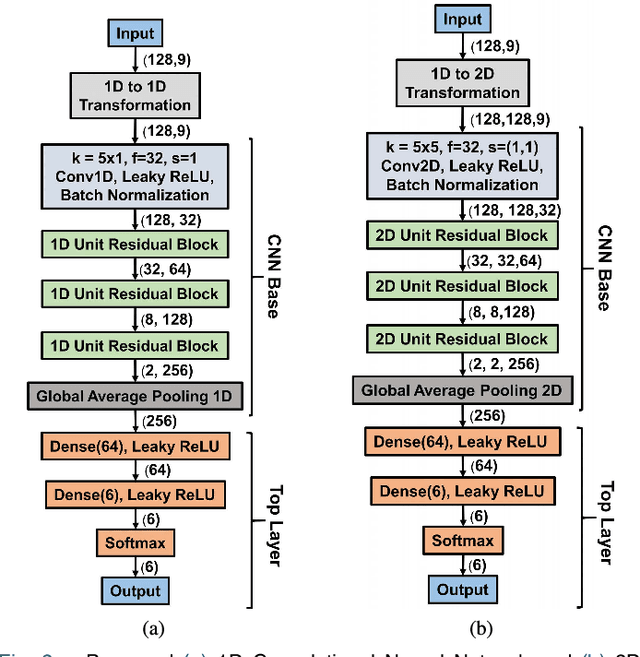
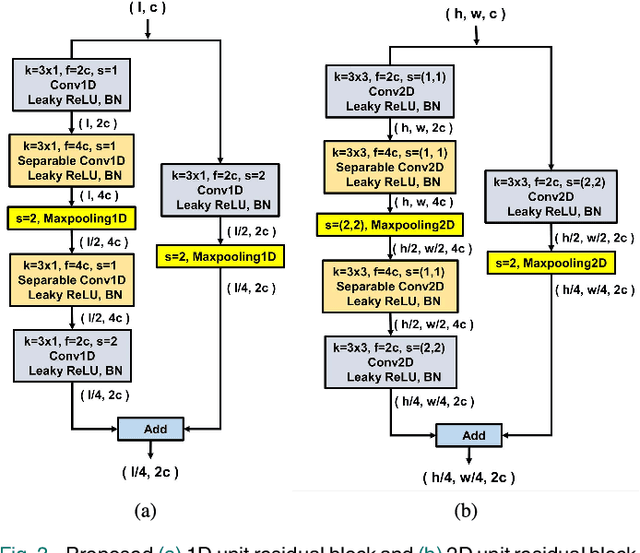
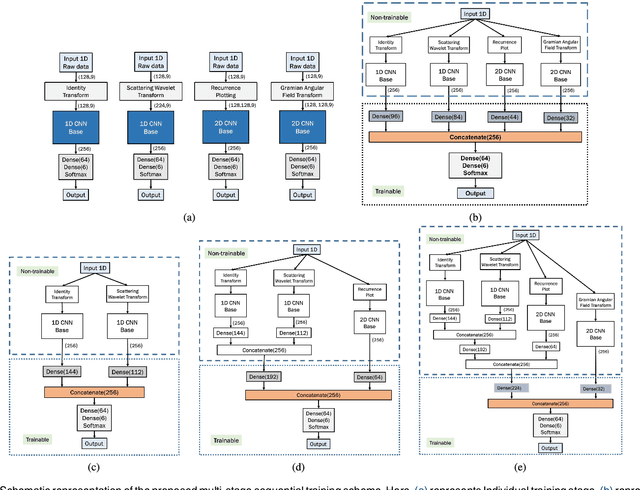
Deep neural network is an effective choice to automatically recognize human actions utilizing data from various wearable sensors. These networks automate the process of feature extraction relying completely on data. However, various noises in time series data with complex inter-modal relationships among sensors make this process more complicated. In this paper, we have proposed a novel multi-stage training approach that increases diversity in this feature extraction process to make accurate recognition of actions by combining varieties of features extracted from diverse perspectives. Initially, instead of using single type of transformation, numerous transformations are employed on time series data to obtain variegated representations of the features encoded in raw data. An efficient deep CNN architecture is proposed that can be individually trained to extract features from different transformed spaces. Later, these CNN feature extractors are merged into an optimal architecture finely tuned for optimizing diversified extracted features through a combined training stage or multiple sequential training stages. This approach offers the opportunity to explore the encoded features in raw sensor data utilizing multifarious observation windows with immense scope for efficient selection of features for final convergence. Extensive experimentations have been carried out in three publicly available datasets that provide outstanding performance consistently with average five-fold cross-validation accuracy of 99.29% on UCI HAR database, 99.02% on USC HAR database, and 97.21% on SKODA database outperforming other state-of-the-art approaches.
* 12 Pages, 7 Figures. This article has been published in IEEE Sensors Journal
CovSegNet: A Multi Encoder-Decoder Architecture for Improved Lesion Segmentation of COVID-19 Chest CT Scans
Dec 02, 2020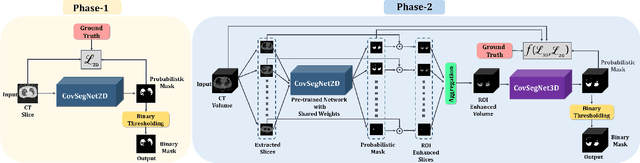
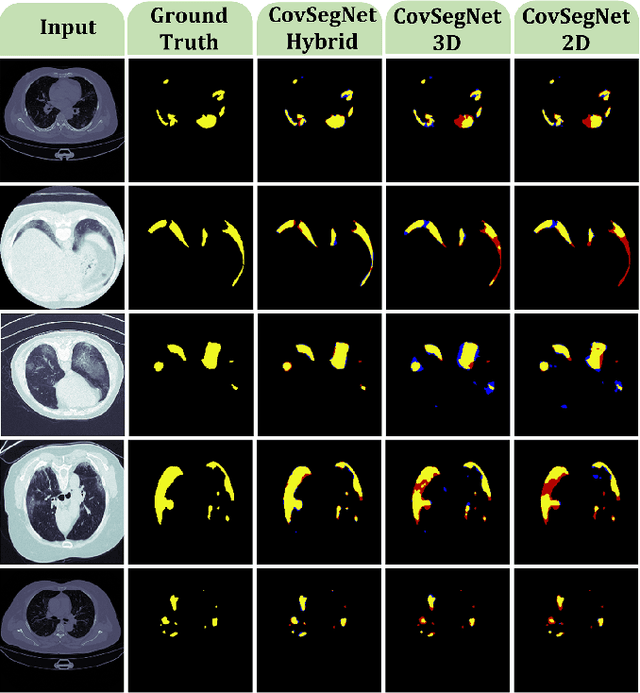
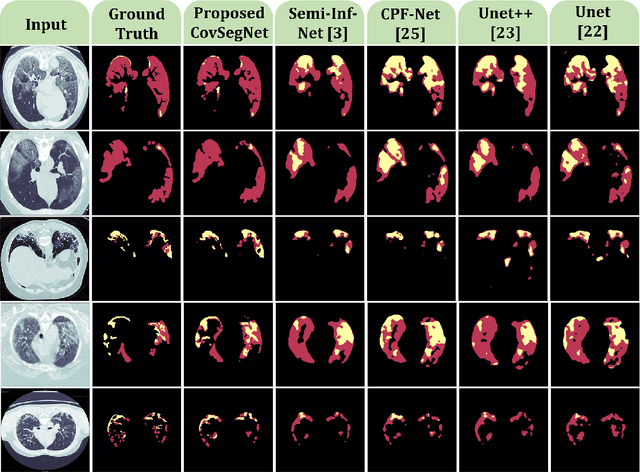
Automatic lung lesions segmentation of chest CT scans is considered a pivotal stage towards accurate diagnosis and severity measurement of COVID-19. Traditional U-shaped encoder-decoder architecture and its variants suffer from diminutions of contextual information in pooling/upsampling operations with increased semantic gaps among encoded and decoded feature maps as well as instigate vanishing gradient problems for its sequential gradient propagation that result in sub-optimal performance. Moreover, operating with 3D CT-volume poses further limitations due to the exponential increase of computational complexity making the optimization difficult. In this paper, an automated COVID-19 lesion segmentation scheme is proposed utilizing a highly efficient neural network architecture, namely CovSegNet, to overcome these limitations. Additionally, a two-phase training scheme is introduced where a deeper 2D-network is employed for generating ROI-enhanced CT-volume followed by a shallower 3D-network for further enhancement with more contextual information without increasing computational burden. Along with the traditional vertical expansion of Unet, we have introduced horizontal expansion with multi-stage encoder-decoder modules for achieving optimum performance. Additionally, multi-scale feature maps are integrated into the scale transition process to overcome the loss of contextual information. Moreover, a multi-scale fusion module is introduced with a pyramid fusion scheme to reduce the semantic gaps between subsequent encoder/decoder modules while facilitating the parallel optimization for efficient gradient propagation. Outstanding performances have been achieved in three publicly available datasets that largely outperform other state-of-the-art approaches. The proposed scheme can be easily extended for achieving optimum segmentation performances in a wide variety of applications.
Privacy Enhancing Machine Learning via Removal of Unwanted Dependencies
Aug 04, 2020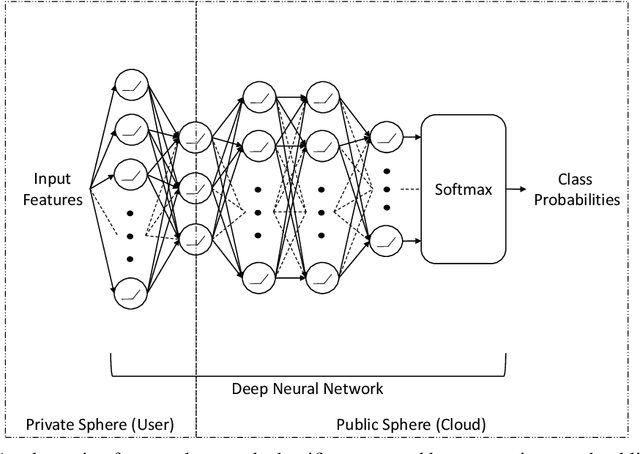

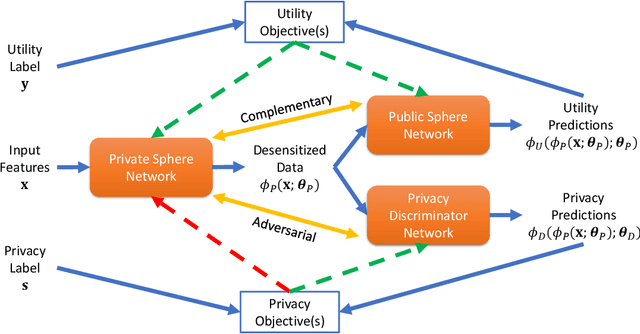
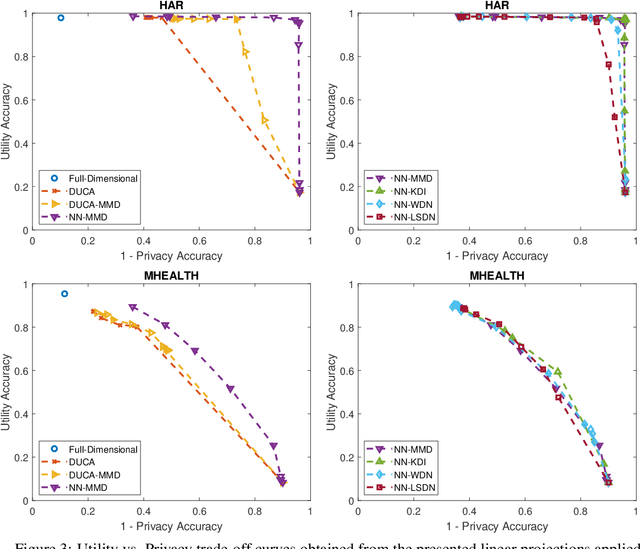
The rapid rise of IoT and Big Data has facilitated copious data driven applications to enhance our quality of life. However, the omnipresent and all-encompassing nature of the data collection can generate privacy concerns. Hence, there is a strong need to develop techniques that ensure the data serve only the intended purposes, giving users control over the information they share. To this end, this paper studies new variants of supervised and adversarial learning methods, which remove the sensitive information in the data before they are sent out for a particular application. The explored methods optimize privacy preserving feature mappings and predictive models simultaneously in an end-to-end fashion. Additionally, the models are built with an emphasis on placing little computational burden on the user side so that the data can be desensitized on device in a cheap manner. Experimental results on mobile sensing and face datasets demonstrate that our models can successfully maintain the utility performances of predictive models while causing sensitive predictions to perform poorly.
A Feature-map Discriminant Perspective for Pruning Deep Neural Networks
May 28, 2020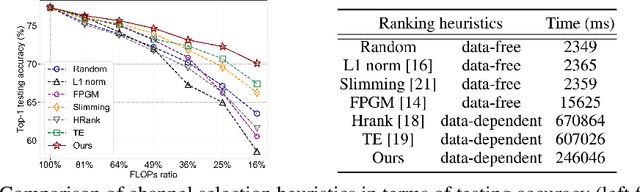
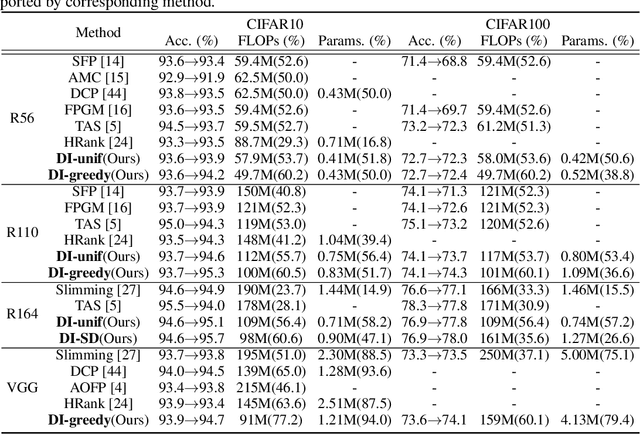
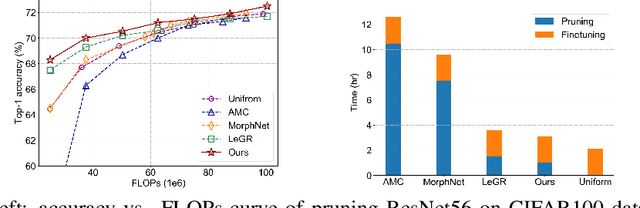
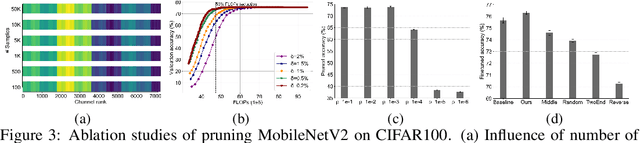
Network pruning has become the de facto tool to accelerate deep neural networks for mobile and edge applications. Recently, feature-map discriminant based channel pruning has shown promising results, as it aligns well with the CNN objective of differentiating multiple classes and offers better interpretability of the pruning decision. However, existing discriminant-based methods are challenged by computation inefficiency, as there is a lack of theoretical guidance on quantifying the feature-map discriminant power. In this paper, we present a new mathematical formulation to accurately and efficiently quantify the feature-map discriminativeness, which gives rise to a novel criterion,Discriminant Information(DI). We analyze the theoretical property of DI, specifically the non-decreasing property, that makes DI a valid selection criterion. DI-based pruning removes channels with minimum influence to DI value, as they contain little information regarding to the discriminant power. The versatility of DI criterion also enables an intra-layer mixed precision quantization to further compress the network. Moreover, we propose a DI-based greedy pruning algorithm and structure distillation technique to automatically decide the pruned structure that satisfies certain resource budget, which is a common requirement in reality. Extensive experiments demonstratethe effectiveness of our method: our pruned ResNet50 on ImageNet achieves 44% FLOPs reduction without any Top-1 accuracy loss compared to unpruned model
Soft-Root-Sign Activation Function
Mar 01, 2020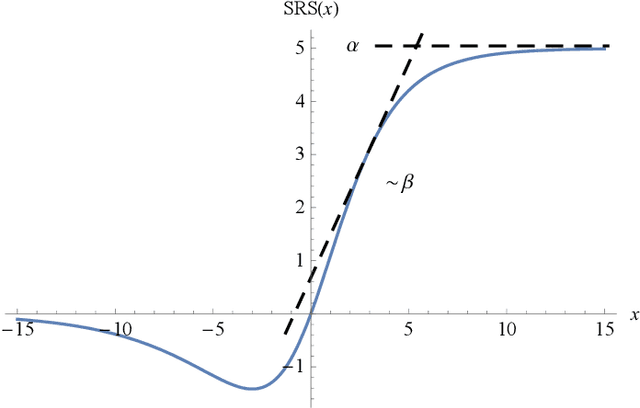
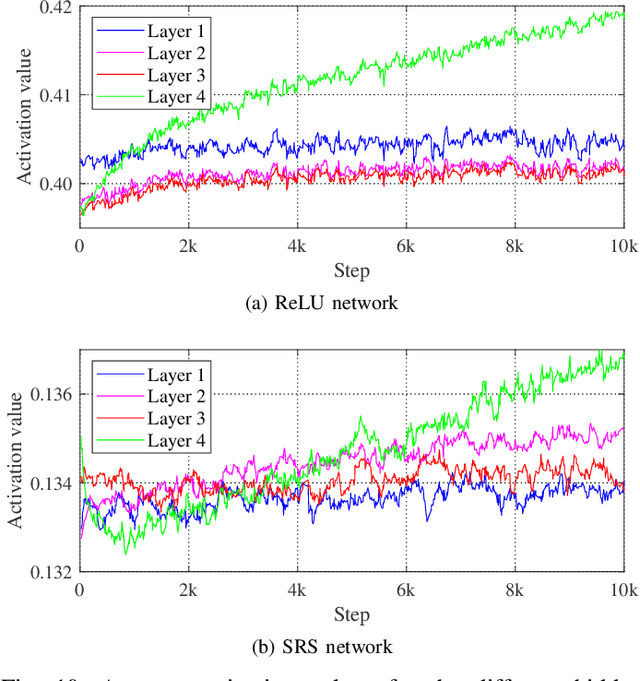
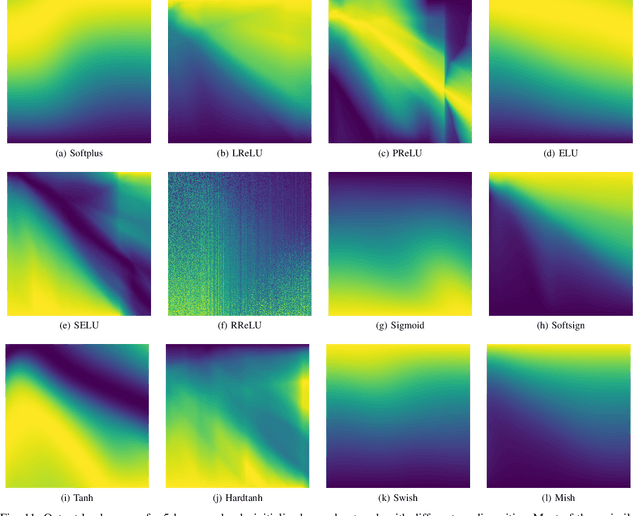
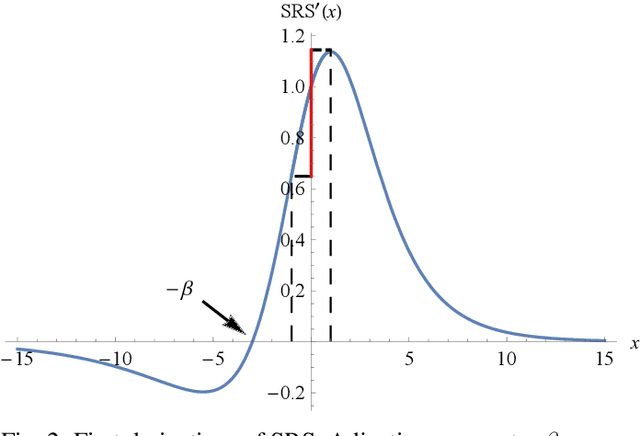
The choice of activation function in deep networks has a significant effect on the training dynamics and task performance. At present, the most effective and widely-used activation function is ReLU. However, because of the non-zero mean, negative missing and unbounded output, ReLU is at a potential disadvantage during optimization. To this end, we introduce a novel activation function to manage to overcome the above three challenges. The proposed nonlinearity, namely "Soft-Root-Sign" (SRS), is smooth, non-monotonic, and bounded. Notably, the bounded property of SRS distinguishes itself from most state-of-the-art activation functions. In contrast to ReLU, SRS can adaptively adjust the output by a pair of independent trainable parameters to capture negative information and provide zero-mean property, which leading not only to better generalization performance, but also to faster learning speed. It also avoids and rectifies the output distribution to be scattered in the non-negative real number space, making it more compatible with batch normalization (BN) and less sensitive to initialization. In experiments, we evaluated SRS on deep networks applied to a variety of tasks, including image classification, machine translation and generative modelling. Our SRS matches or exceeds models with ReLU and other state-of-the-art nonlinearities, showing that the proposed activation function is generalized and can achieve high performance across tasks. Ablation study further verified the compatibility with BN and self-adaptability for different initialization.
Exploiting Operation Importance for Differentiable Neural Architecture Search
Nov 24, 2019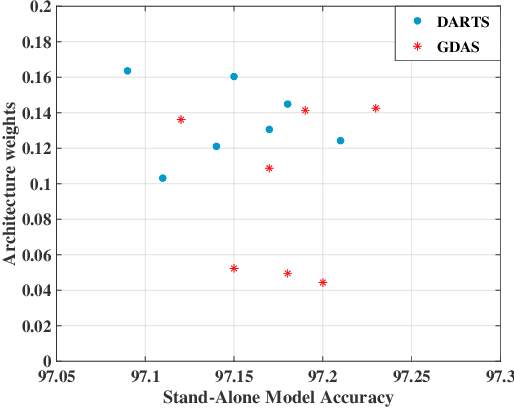
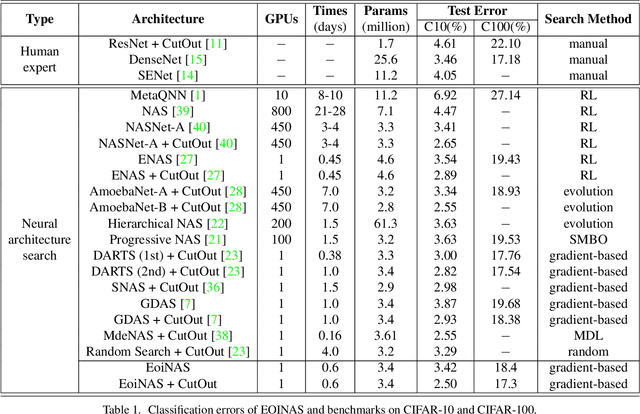
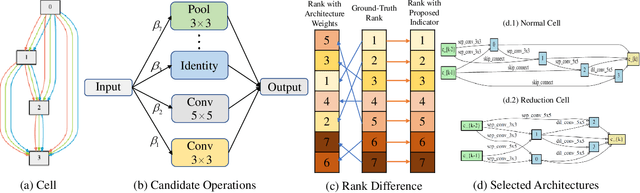
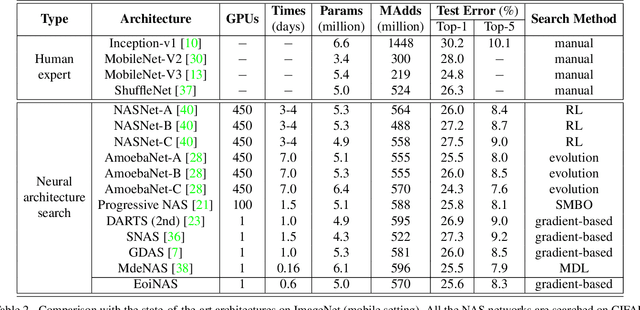
Recently, differentiable neural architecture search methods significantly reduce the search cost by constructing a super network and relax the architecture representation by assigning architecture weights to the candidate operations. All the existing methods determine the importance of each operation directly by architecture weights. However, architecture weights cannot accurately reflect the importance of each operation; that is, the operation with the highest weight might not related to the best performance. To alleviate this deficiency, we propose a simple yet effective solution to neural architecture search, termed as exploiting operation importance for effective neural architecture search (EoiNAS), in which a new indicator is proposed to fully exploit the operation importance and guide the model search. Based on this new indicator, we propose a gradual operation pruning strategy to further improve the search efficiency and accuracy. Experimental results have demonstrated the effectiveness of the proposed method. Specifically, we achieve an error rate of 2.50\% on CIFAR-10, which significantly outperforms state-of-the-art methods. When transferred to ImageNet, it achieves the top-1 error of 25.6\%, comparable to the state-of-the-art performance under the mobile setting.