 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaogang Wang
Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs
Jun 09, 2022
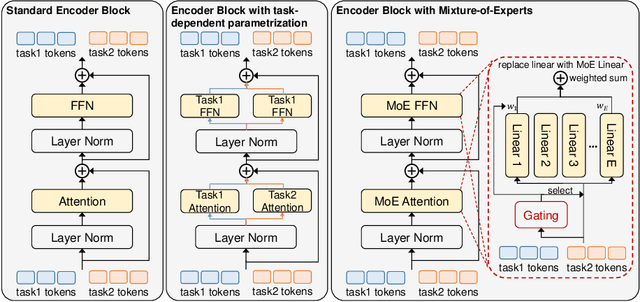
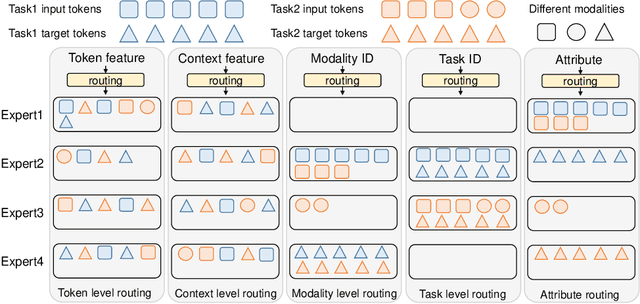

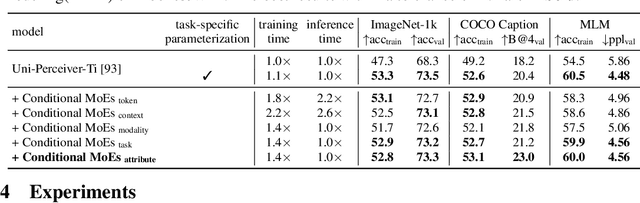
To build an artificial neural network like the biological intelligence system, recent works have unified numerous tasks into a generalist model, which can process various tasks with shared parameters and do not have any task-specific modules. While generalist models achieve promising results on various benchmarks, they have performance degradation on some tasks compared with task-specialized models. In this work, we find that interference among different tasks and modalities is the main factor to this phenomenon. To mitigate such interference, we introduce the Conditional Mixture-of-Experts (Conditional MoEs) to generalist models. Routing strategies under different levels of conditions are proposed to take both the training/inference cost and generalization ability into account. By incorporating the proposed Conditional MoEs, the recently proposed generalist model Uni-Perceiver can effectively mitigate the interference across tasks and modalities, and achieves state-of-the-art results on a series of downstream tasks via prompt tuning on 1% of downstream data. Moreover, the introduction of Conditional MoEs still holds the generalization ability of generalist models to conduct zero-shot inference on new tasks, e.g., video-text retrieval and video caption. Code and pre-trained generalist models shall be released.
Siamese Image Modeling for Self-Supervised Vision Representation Learning
Jun 02, 2022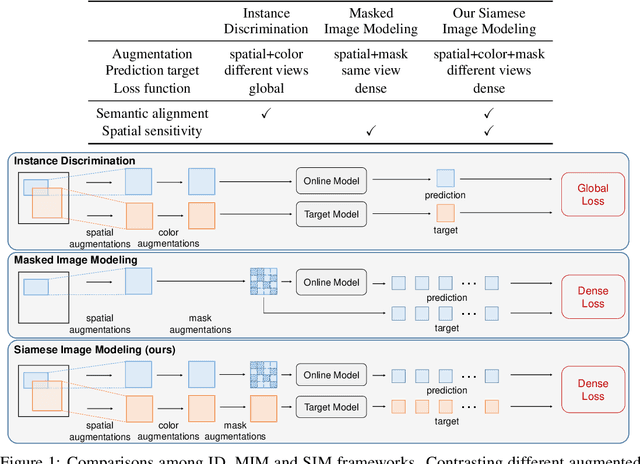
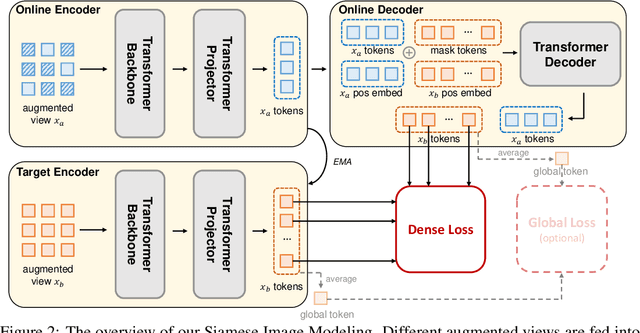
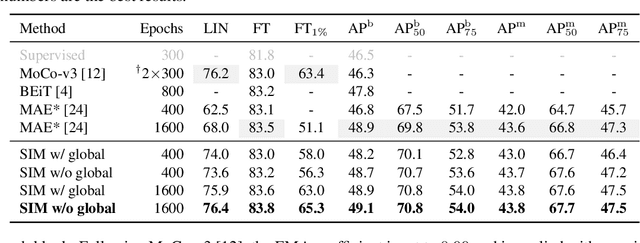
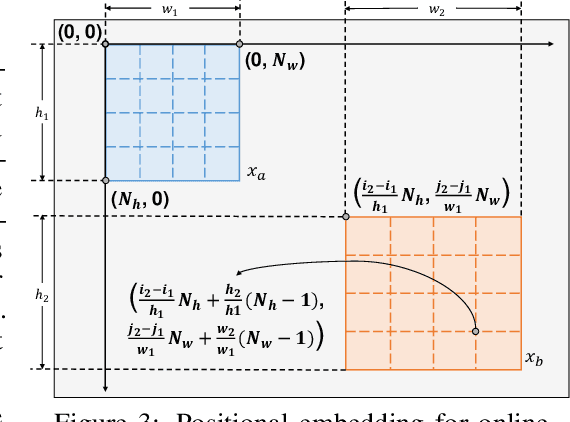
Self-supervised learning (SSL) has delivered superior performance on a variety of downstream vision tasks. Two main-stream SSL frameworks have been proposed, i.e., Instance Discrimination (ID) and Masked Image Modeling (MIM). ID pulls together the representations of different views from the same image, while avoiding feature collapse. It does well on linear probing but is inferior in detection performance. On the other hand, MIM reconstructs the original content given a masked image. It excels at dense prediction but fails to perform well on linear probing. Their distinctions are caused by neglecting the representation requirements of either semantic alignment or spatial sensitivity. Specifically, we observe that (1) semantic alignment demands semantically similar views to be projected into nearby representation, which can be achieved by contrasting different views with strong augmentations; (2) spatial sensitivity requires to model the local structure within an image. Predicting dense representations with masked image is therefore beneficial because it models the conditional distribution of image content. Driven by these analysis, we propose Siamese Image Modeling (SIM), which predicts the dense representations of an augmented view, based on another masked view from the same image but with different augmentations. Our method uses a Siamese network with two branches. The online branch encodes the first view, and predicts the second view's representation according to the relative positions between these two views. The target branch produces the target by encoding the second view. In this way, we are able to achieve comparable linear probing and dense prediction performances with ID and MIM, respectively. We also demonstrate that decent linear probing result can be obtained without a global loss. Code shall be released.
Efficient Burst Raw Denoising with Variance Stabilization and Multi-frequency Denoising Network
May 10, 2022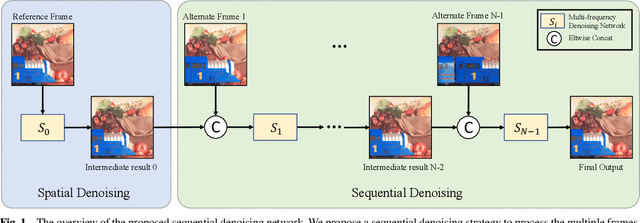
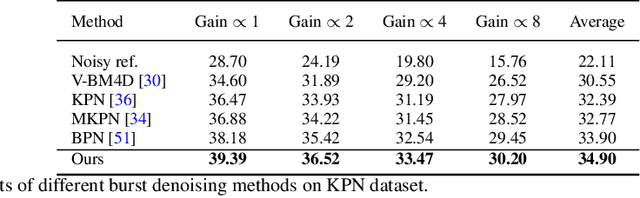
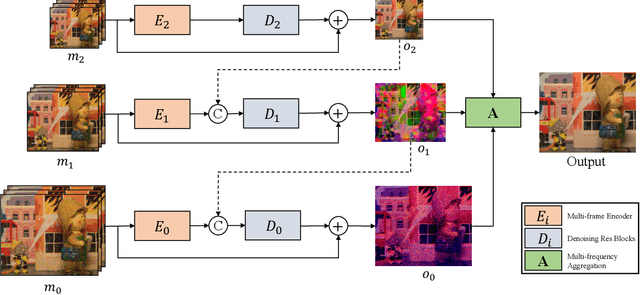

With the growing popularity of smartphones, capturing high-quality images is of vital importance to smartphones. The cameras of smartphones have small apertures and small sensor cells, which lead to the noisy images in low light environment. Denoising based on a burst of multiple frames generally outperforms single frame denoising but with the larger compututional cost. In this paper, we propose an efficient yet effective burst denoising system. We adopt a three-stage design: noise prior integration, multi-frame alignment and multi-frame denoising. First, we integrate noise prior by pre-processing raw signals into a variance-stabilization space, which allows using a small-scale network to achieve competitive performance. Second, we observe that it is essential to adopt an explicit alignment for burst denoising, but it is not necessary to integrate a learning-based method to perform multi-frame alignment. Instead, we resort to a conventional and efficient alignment method and combine it with our multi-frame denoising network. At last, we propose a denoising strategy that processes multiple frames sequentially. Sequential denoising avoids filtering a large number of frames by decomposing multiple frames denoising into several efficient sub-network denoising. As for each sub-network, we propose an efficient multi-frequency denoising network to remove noise of different frequencies. Our three-stage design is efficient and shows strong performance on burst denoising. Experiments on synthetic and real raw datasets demonstrate that our method outperforms state-of-the-art methods, with less computational cost. Furthermore, the low complexity and high-quality performance make deployment on smartphones possible.
Not All Tokens Are Equal: Human-centric Visual Analysis via Token Clustering Transformer
Apr 21, 2022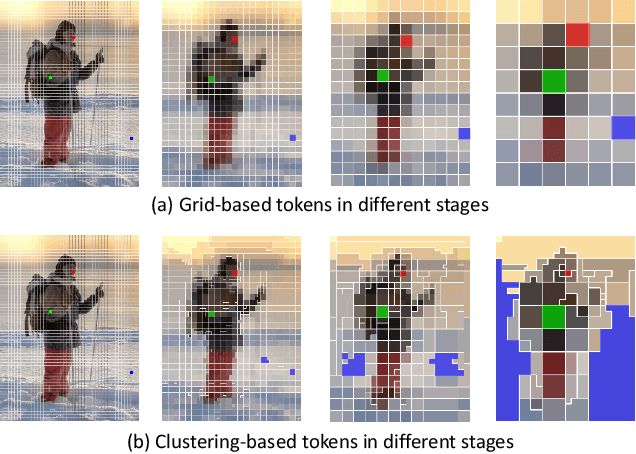
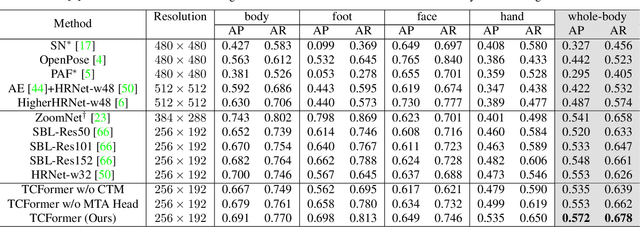
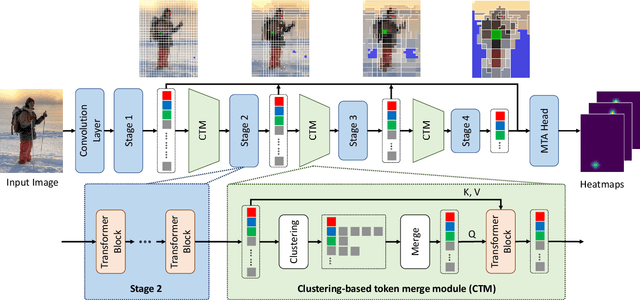
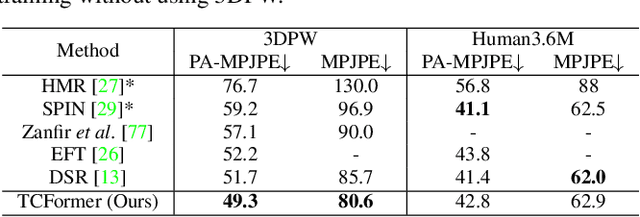
Vision transformers have achieved great successes in many computer vision tasks. Most methods generate vision tokens by splitting an image into a regular and fixed grid and treating each cell as a token. However, not all regions are equally important in human-centric vision tasks, e.g., the human body needs a fine representation with many tokens, while the image background can be modeled by a few tokens. To address this problem, we propose a novel Vision Transformer, called Token Clustering Transformer (TCFormer), which merges tokens by progressive clustering, where the tokens can be merged from different locations with flexible shapes and sizes. The tokens in TCFormer can not only focus on important areas but also adjust the token shapes to fit the semantic concept and adopt a fine resolution for regions containing critical details, which is beneficial to capturing detailed information. Extensive experiments show that TCFormer consistently outperforms its counterparts on different challenging human-centric tasks and datasets, including whole-body pose estimation on COCO-WholeBody and 3D human mesh reconstruction on 3DPW. Code is available at https://github.com/zengwang430521/TCFormer.git
RNNPose: Recurrent 6-DoF Object Pose Refinement with Robust Correspondence Field Estimation and Pose Optimization
Apr 10, 2022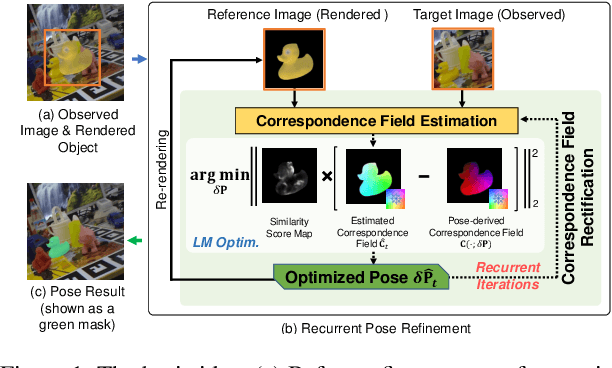
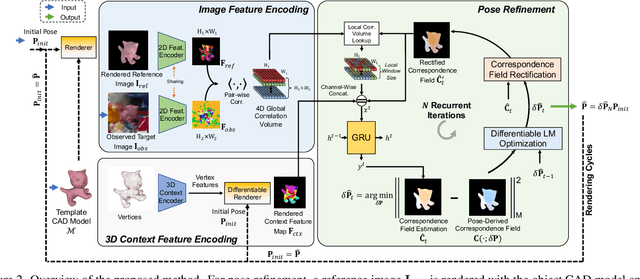
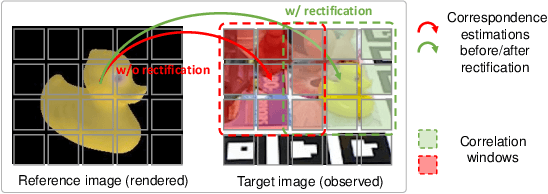
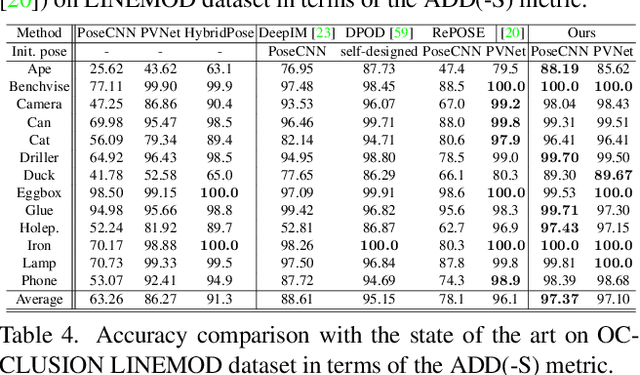
6-DoF object pose estimation from a monocular image is challenging, and a post-refinement procedure is generally needed for high-precision estimation. In this paper, we propose a framework based on a recurrent neural network (RNN) for object pose refinement, which is robust to erroneous initial poses and occlusions. During the recurrent iterations, object pose refinement is formulated as a non-linear least squares problem based on the estimated correspondence field (between a rendered image and the observed image). The problem is then solved by a differentiable Levenberg-Marquardt (LM) algorithm enabling end-to-end training. The correspondence field estimation and pose refinement are conducted alternatively in each iteration to recover the object poses. Furthermore, to improve the robustness to occlusion, we introduce a consistency-check mechanism based on the learned descriptors of the 3D model and observed 2D images, which downweights the unreliable correspondences during pose optimization. Extensive experiments on LINEMOD, Occlusion-LINEMOD, and YCB-Video datasets validate the effectiveness of our method and demonstrate state-of-the-art performance.
Learning a Structured Latent Space for Unsupervised Point Cloud Completion
Mar 29, 2022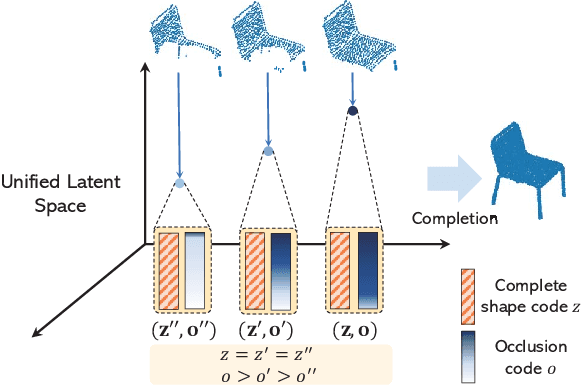
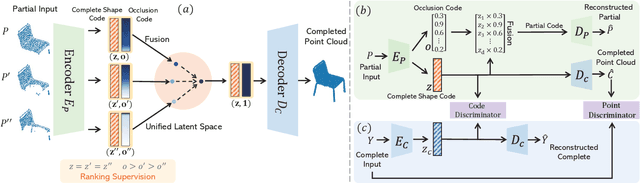
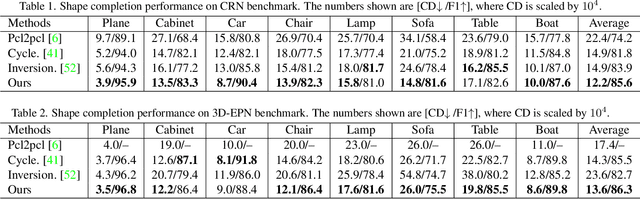
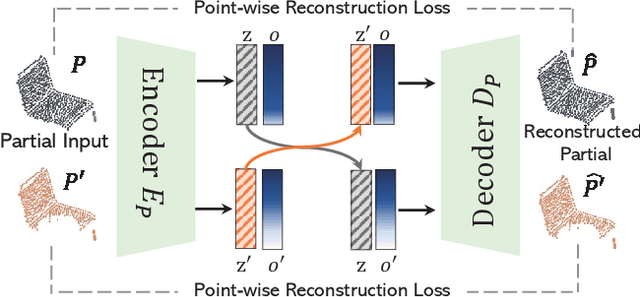
Unsupervised point cloud completion aims at estimating the corresponding complete point cloud of a partial point cloud in an unpaired manner. It is a crucial but challenging problem since there is no paired partial-complete supervision that can be exploited directly. In this work, we propose a novel framework, which learns a unified and structured latent space that encoding both partial and complete point clouds. Specifically, we map a series of related partial point clouds into multiple complete shape and occlusion code pairs and fuse the codes to obtain their representations in the unified latent space. To enforce the learning of such a structured latent space, the proposed method adopts a series of constraints including structured ranking regularization, latent code swapping constraint, and distribution supervision on the related partial point clouds. By establishing such a unified and structured latent space, better partial-complete geometry consistency and shape completion accuracy can be achieved. Extensive experiments show that our proposed method consistently outperforms state-of-the-art unsupervised methods on both synthetic ShapeNet and real-world KITTI, ScanNet, and Matterport3D datasets.
* 8 pages, 5 figures, cvpr2022
Point2Seq: Detecting 3D Objects as Sequences
Mar 25, 2022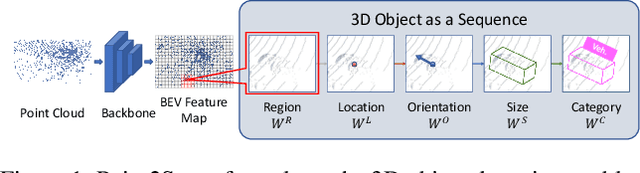
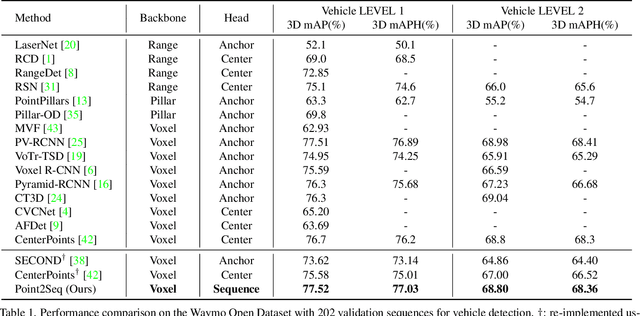
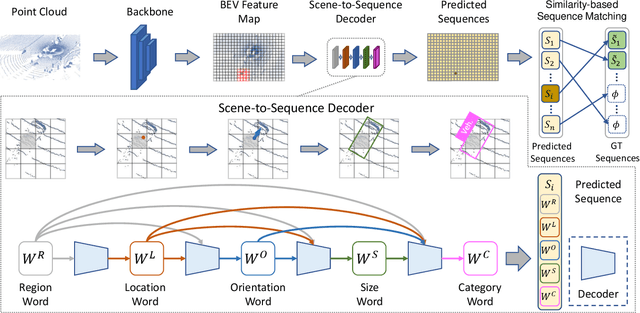
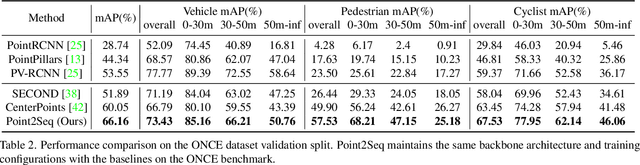
We present a simple and effective framework, named Point2Seq, for 3D object detection from point clouds. In contrast to previous methods that normally {predict attributes of 3D objects all at once}, we expressively model the interdependencies between attributes of 3D objects, which in turn enables a better detection accuracy. Specifically, we view each 3D object as a sequence of words and reformulate the 3D object detection task as decoding words from 3D scenes in an auto-regressive manner. We further propose a lightweight scene-to-sequence decoder that can auto-regressively generate words conditioned on features from a 3D scene as well as cues from the preceding words. The predicted words eventually constitute a set of sequences that completely describe the 3D objects in the scene, and all the predicted sequences are then automatically assigned to the respective ground truths through similarity-based sequence matching. Our approach is conceptually intuitive and can be readily plugged upon most existing 3D-detection backbones without adding too much computational overhead; the sequential decoding paradigm we proposed, on the other hand, can better exploit information from complex 3D scenes with the aid of preceding predicted words. Without bells and whistles, our method significantly outperforms previous anchor- and center-based 3D object detection frameworks, yielding the new state of the art on the challenging ONCE dataset as well as the Waymo Open Dataset. Code is available at \url{https://github.com/ocNflag/point2seq}.
Relational Self-Supervised Learning
Mar 16, 2022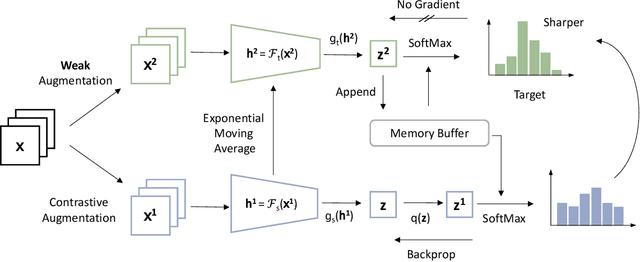
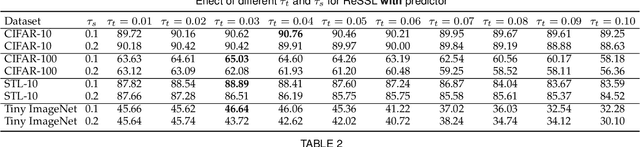
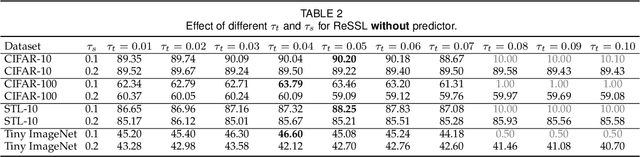

Self-supervised Learning (SSL) including the mainstream contrastive learning has achieved great success in learning visual representations without data annotations. However, most methods mainly focus on the instance level information (\ie, the different augmented images of the same instance should have the same feature or cluster into the same class), but there is a lack of attention on the relationships between different instances. In this paper, we introduce a novel SSL paradigm, which we term as relational self-supervised learning (ReSSL) framework that learns representations by modeling the relationship between different instances. Specifically, our proposed method employs sharpened distribution of pairwise similarities among different instances as \textit{relation} metric, which is thus utilized to match the feature embeddings of different augmentations. To boost the performance, we argue that weak augmentations matter to represent a more reliable relation, and leverage momentum strategy for practical efficiency. The designed asymmetric predictor head and an InfoNCE warm-up strategy enhance the robustness to hyper-parameters and benefit the resulting performance. Experimental results show that our proposed ReSSL substantially outperforms the state-of-the-art methods across different network architectures, including various lightweight networks (\eg, EfficientNet and MobileNet).
Robust Self-Supervised LiDAR Odometry via Representative Structure Discovery and 3D Inherent Error Modeling
Feb 27, 2022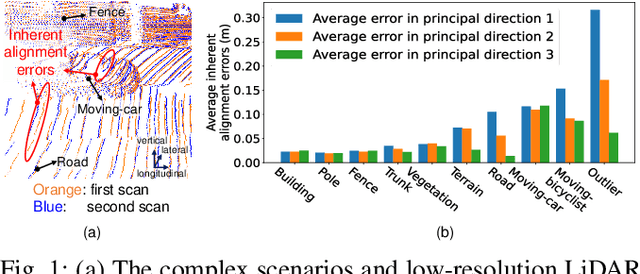
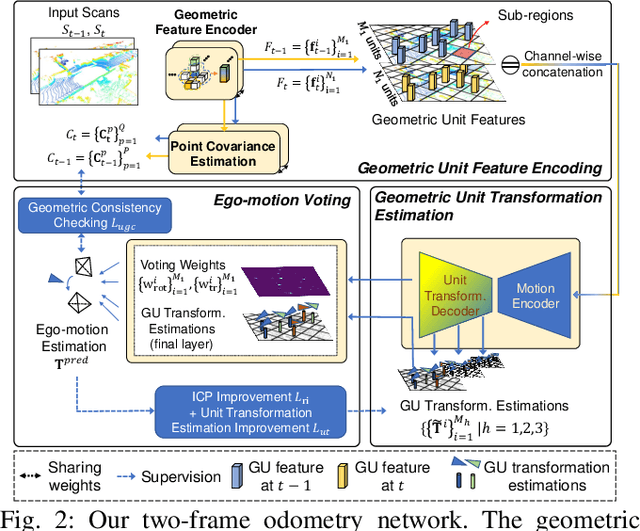

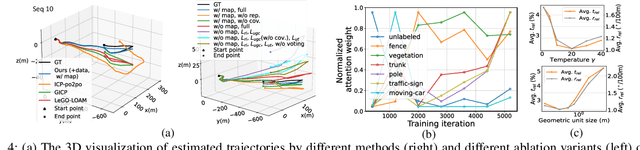
The correct ego-motion estimation basically relies on the understanding of correspondences between adjacent LiDAR scans. However, given the complex scenarios and the low-resolution LiDAR, finding reliable structures for identifying correspondences can be challenging. In this paper, we delve into structure reliability for accurate self-supervised ego-motion estimation and aim to alleviate the influence of unreliable structures in training, inference and mapping phases. We improve the self-supervised LiDAR odometry substantially from three aspects: 1) A two-stage odometry estimation network is developed, where we obtain the ego-motion by estimating a set of sub-region transformations and averaging them with a motion voting mechanism, to encourage the network focusing on representative structures. 2) The inherent alignment errors, which cannot be eliminated via ego-motion optimization, are down-weighted in losses based on the 3D point covariance estimations. 3) The discovered representative structures and learned point covariances are incorporated in the mapping module to improve the robustness of map construction. Our two-frame odometry outperforms the previous state of the arts by 16%/12% in terms of translational/rotational errors on the KITTI dataset and performs consistently well on the Apollo-Southbay datasets. We can even rival the fully supervised counterparts with our mapping module and more unlabeled training data.
Learning Semantic Abstraction of Shape via 3D Region of Interest
Jan 13, 2022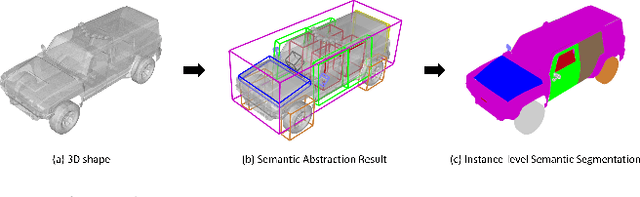
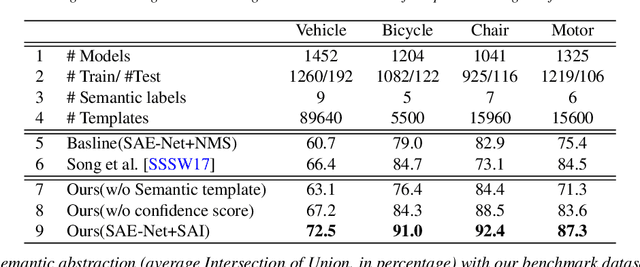
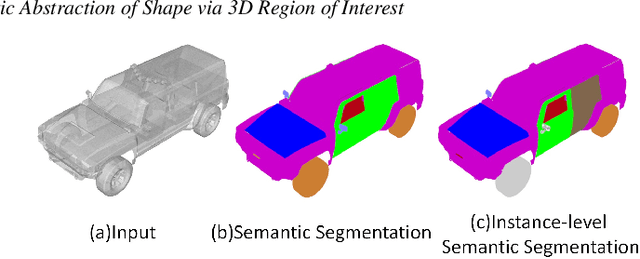
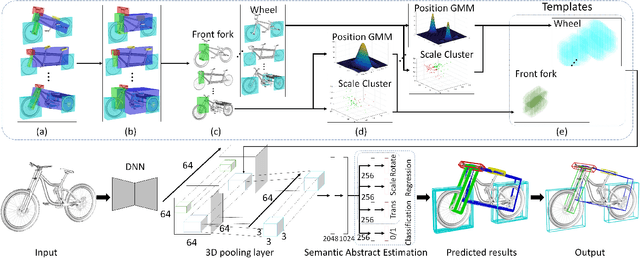
In this paper, we focus on the two tasks of 3D shape abstraction and semantic analysis. This is in contrast to current methods, which focus solely on either 3D shape abstraction or semantic analysis. In addition, previous methods have had difficulty producing instance-level semantic results, which has limited their application. We present a novel method for the joint estimation of a 3D shape abstraction and semantic analysis. Our approach first generates a number of 3D semantic candidate regions for a 3D shape; we then employ these candidates to directly predict the semantic categories and refine the parameters of the candidate regions simultaneously using a deep convolutional neural network. Finally, we design an algorithm to fuse the predicted results and obtain the final semantic abstraction, which is shown to be an improvement over a standard non maximum suppression. Experimental results demonstrate that our approach can produce state-of-the-art results. Moreover, we also find that our results can be easily applied to instance-level semantic part segmentation and shape matching.