 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatchRec: Multi-Grained Patching for Efficient LLM-based Sequential Recommendation
Jan 25, 2025Large Language Models for sequential recommendation (LLM4SR), which transform user-item interactions into language modeling, have shown promising results. However, due to the limitations of context window size and the computational costs associated with Large Language Models (LLMs), current approaches primarily truncate user history by only considering the textual information of items from the most recent interactions in the input prompt. This truncation fails to fully capture the long-term behavioral patterns of users. To address this, we propose a multi-grained patching framework -- PatchRec. It compresses the textual tokens of an item title into a compact item patch, and further compresses multiple item patches into a denser session patch, with earlier interactions being compressed to a greater degree. The framework consists of two stages: (1) Patch Pre-training, which familiarizes LLMs with item-level compression patterns, and (2) Patch Fine-tuning, which teaches LLMs to model sequences at multiple granularities. Through this simple yet effective approach, empirical results demonstrate that PatchRec outperforms existing methods, achieving significant performance gains with fewer tokens fed to the LLM. Specifically, PatchRec shows up to a 32% improvement in HR@20 on the Goodreads dataset over uncompressed baseline, while using only 7% of the tokens. This multi-grained sequence modeling paradigm, with an adjustable compression ratio, enables LLMs to be efficiently deployed in real-world recommendation systems that handle extremely long user behavior sequences.
CookingDiffusion: Cooking Procedural Image Generation with Stable Diffusion
Jan 15, 2025



Recent advancements in text-to-image generation models have excelled in creating diverse and realistic images. This success extends to food imagery, where various conditional inputs like cooking styles, ingredients, and recipes are utilized. However, a yet-unexplored challenge is generating a sequence of procedural images based on cooking steps from a recipe. This could enhance the cooking experience with visual guidance and possibly lead to an intelligent cooking simulation system. To fill this gap, we introduce a novel task called \textbf{cooking procedural image generation}. This task is inherently demanding, as it strives to create photo-realistic images that align with cooking steps while preserving sequential consistency. To collectively tackle these challenges, we present \textbf{CookingDiffusion}, a novel approach that leverages Stable Diffusion and three innovative Memory Nets to model procedural prompts. These prompts encompass text prompts (representing cooking steps), image prompts (corresponding to cooking images), and multi-modal prompts (mixing cooking steps and images), ensuring the consistent generation of cooking procedural images. To validate the effectiveness of our approach, we preprocess the YouCookII dataset, establishing a new benchmark. Our experimental results demonstrate that our model excels at generating high-quality cooking procedural images with remarkable consistency across sequential cooking steps, as measured by both the FID and the proposed Average Procedure Consistency metrics. Furthermore, CookingDiffusion demonstrates the ability to manipulate ingredients and cooking methods in a recipe. We will make our code, models, and dataset publicly accessible.
DVM: Towards Controllable LLM Agents in Social Deduction Games
Jan 12, 2025



Large Language Models (LLMs) have advanced the capability of game agents in social deduction games (SDGs). These games rely heavily on conversation-driven interactions and require agents to infer, make decisions, and express based on such information. While this progress leads to more sophisticated and strategic non-player characters (NPCs) in SDGs, there exists a need to control the proficiency of these agents. This control not only ensures that NPCs can adapt to varying difficulty levels during gameplay, but also provides insights into the safety and fairness of LLM agents. In this paper, we present DVM, a novel framework for developing controllable LLM agents for SDGs, and demonstrate its implementation on one of the most popular SDGs, Werewolf. DVM comprises three main components: Predictor, Decider, and Discussor. By integrating reinforcement learning with a win rate-constrained decision chain reward mechanism, we enable agents to dynamically adjust their gameplay proficiency to achieve specified win rates. Experiments show that DVM not only outperforms existing methods in the Werewolf game, but also successfully modulates its performance levels to meet predefined win rate targets. These results pave the way for LLM agents' adaptive and balanced gameplay in SDGs, opening new avenues for research in controllable game agents.
Position-aware Graph Transformer for Recommendation
Dec 25, 2024Collaborative recommendation fundamentally involves learning high-quality user and item representations from interaction data. Recently, graph convolution networks (GCNs) have advanced the field by utilizing high-order connectivity patterns in interaction graphs, as evidenced by state-of-the-art methods like PinSage and LightGCN. However, one key limitation has not been well addressed in existing solutions: capturing long-range collaborative filtering signals, which are crucial for modeling user preference. In this work, we propose a new graph transformer (GT) framework -- \textit{Position-aware Graph Transformer for Recommendation} (PGTR), which combines the global modeling capability of Transformer blocks with the local neighborhood feature extraction of GCNs. The key insight is to explicitly incorporate node position and structure information from the user-item interaction graph into GT architecture via several purpose-designed positional encodings. The long-range collaborative signals from the Transformer block are then combined linearly with the local neighborhood features from the GCN backbone to enhance node embeddings for final recommendations. Empirical studies demonstrate the effectiveness of the proposed PGTR method when implemented on various GCN-based backbones across four real-world datasets, and the robustness against interaction sparsity as well as noise.
FreeScale: Unleashing the Resolution of Diffusion Models via Tuning-Free Scale Fusion
Dec 12, 2024



Visual diffusion models achieve remarkable progress, yet they are typically trained at limited resolutions due to the lack of high-resolution data and constrained computation resources, hampering their ability to generate high-fidelity images or videos at higher resolutions. Recent efforts have explored tuning-free strategies to exhibit the untapped potential higher-resolution visual generation of pre-trained models. However, these methods are still prone to producing low-quality visual content with repetitive patterns. The key obstacle lies in the inevitable increase in high-frequency information when the model generates visual content exceeding its training resolution, leading to undesirable repetitive patterns deriving from the accumulated errors. To tackle this challenge, we propose FreeScale, a tuning-free inference paradigm to enable higher-resolution visual generation via scale fusion. Specifically, FreeScale processes information from different receptive scales and then fuses it by extracting desired frequency components. Extensive experiments validate the superiority of our paradigm in extending the capabilities of higher-resolution visual generation for both image and video models. Notably, compared with the previous best-performing method, FreeScale unlocks the generation of 8k-resolution images for the first time.
Intelligent System for Automated Molecular Patent Infringement Assessment
Dec 10, 2024



Automated drug discovery offers significant potential for accelerating the development of novel therapeutics by substituting labor-intensive human workflows with machine-driven processes. However, a critical bottleneck persists in the inability of current automated frameworks to assess whether newly designed molecules infringe upon existing patents, posing significant legal and financial risks. We introduce PatentFinder, a novel tool-enhanced and multi-agent framework that accurately and comprehensively evaluates small molecules for patent infringement. It incorporates both heuristic and model-based tools tailored for decomposed subtasks, featuring: MarkushParser, which is capable of optical chemical structure recognition of molecular and Markush structures, and MarkushMatcher, which enhances large language models' ability to extract substituent groups from molecules accurately. On our benchmark dataset MolPatent-240, PatentFinder outperforms baseline approaches that rely solely on large language models, demonstrating a 13.8\% increase in F1-score and a 12\% rise in accuracy. Experimental results demonstrate that PatentFinder mitigates label bias to produce balanced predictions and autonomously generates detailed, interpretable patent infringement reports. This work not only addresses a pivotal challenge in automated drug discovery but also demonstrates the potential of decomposing complex scientific tasks into manageable subtasks for specialized, tool-augmented agents.
Precise, Fast, and Low-cost Concept Erasure in Value Space: Orthogonal Complement Matters
Dec 09, 2024



The success of text-to-image generation enabled by diffuion models has imposed an urgent need to erase unwanted concepts, e.g., copyrighted, offensive, and unsafe ones, from the pre-trained models in a precise, timely, and low-cost manner. The twofold demand of concept erasure requires a precise removal of the target concept during generation (i.e., erasure efficacy), while a minimal impact on non-target content generation (i.e., prior preservation). Existing methods are either computationally costly or face challenges in maintaining an effective balance between erasure efficacy and prior preservation. To improve, we propose a precise, fast, and low-cost concept erasure method, called Adaptive Vaule Decomposer (AdaVD), which is training-free. This method is grounded in a classical linear algebraic orthogonal complement operation, implemented in the value space of each cross-attention layer within the UNet of diffusion models. An effective shift factor is designed to adaptively navigate the erasure strength, enhancing prior preservation without sacrificing erasure efficacy. Extensive experimental results show that the proposed AdaVD is effective at both single and multiple concept erasure, showing a 2- to 10-fold improvement in prior preservation as compared to the second best, meanwhile achieving the best or near best erasure efficacy, when comparing with both training-based and training-free state of the arts. AdaVD supports a series of diffusion models and downstream image generation tasks, the code is available on the project page: https://github.com/WYuan1001/AdaVD
Holmes-VAU: Towards Long-term Video Anomaly Understanding at Any Granularity
Dec 09, 2024How can we enable models to comprehend video anomalies occurring over varying temporal scales and contexts? Traditional Video Anomaly Understanding (VAU) methods focus on frame-level anomaly prediction, often missing the interpretability of complex and diverse real-world anomalies. Recent multimodal approaches leverage visual and textual data but lack hierarchical annotations that capture both short-term and long-term anomalies. To address this challenge, we introduce HIVAU-70k, a large-scale benchmark for hierarchical video anomaly understanding across any granularity. We develop a semi-automated annotation engine that efficiently scales high-quality annotations by combining manual video segmentation with recursive free-text annotation using large language models (LLMs). This results in over 70,000 multi-granular annotations organized at clip-level, event-level, and video-level segments. For efficient anomaly detection in long videos, we propose the Anomaly-focused Temporal Sampler (ATS). ATS integrates an anomaly scorer with a density-aware sampler to adaptively select frames based on anomaly scores, ensuring that the multimodal LLM concentrates on anomaly-rich regions, which significantly enhances both efficiency and accuracy. Extensive experiments demonstrate that our hierarchical instruction data markedly improves anomaly comprehension. The integrated ATS and visual-language model outperform traditional methods in processing long videos. Our benchmark and model are publicly available at https://github.com/pipixin321/HolmesVAU.
Unified Parameter-Efficient Unlearning for LLMs
Nov 30, 2024



The advent of Large Language Models (LLMs) has revolutionized natural language processing, enabling advanced understanding and reasoning capabilities across a variety of tasks. Fine-tuning these models for specific domains, particularly through Parameter-Efficient Fine-Tuning (PEFT) strategies like LoRA, has become a prevalent practice due to its efficiency. However, this raises significant privacy and security concerns, as models may inadvertently retain and disseminate sensitive or undesirable information. To address these issues, we introduce a novel instance-wise unlearning framework, LLMEraser, which systematically categorizes unlearning tasks and applies precise parameter adjustments using influence functions. Unlike traditional unlearning techniques that are often limited in scope and require extensive retraining, LLMEraser is designed to handle a broad spectrum of unlearning tasks without compromising model performance. Extensive experiments on benchmark datasets demonstrate that LLMEraser excels in efficiently managing various unlearning scenarios while maintaining the overall integrity and efficacy of the models.
PersonalVideo: High ID-Fidelity Video Customization without Dynamic and Semantic Degradation
Nov 26, 2024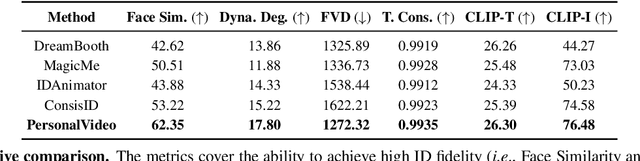
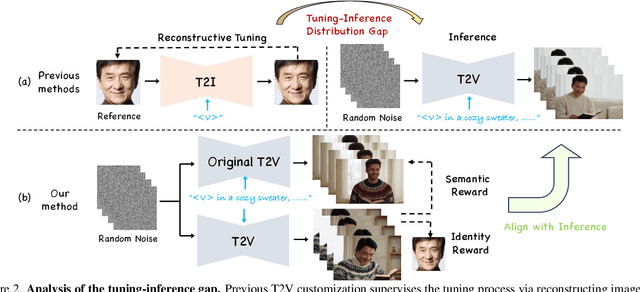
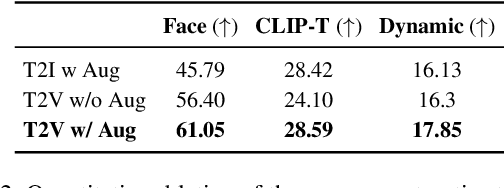
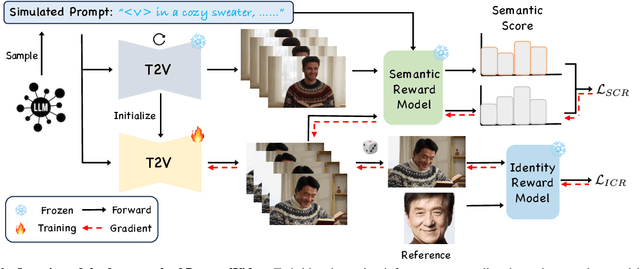
The current text-to-video (T2V) generation has made significant progress in synthesizing realistic general videos, but it is still under-explored in identity-specific human video generation with customized ID images. The key challenge lies in maintaining high ID fidelity consistently while preserving the original motion dynamic and semantic following after the identity injection. Current video identity customization methods mainly rely on reconstructing given identity images on text-to-image models, which have a divergent distribution with the T2V model. This process introduces a tuning-inference gap, leading to dynamic and semantic degradation. To tackle this problem, we propose a novel framework, dubbed \textbf{PersonalVideo}, that applies direct supervision on videos synthesized by the T2V model to bridge the gap. Specifically, we introduce a learnable Isolated Identity Adapter to customize the specific identity non-intrusively, which does not comprise the original T2V model's abilities (e.g., motion dynamic and semantic following). With the non-reconstructive identity loss, we further employ simulated prompt augmentation to reduce overfitting by supervising generated results in more semantic scenarios, gaining good robustness even with only a single reference image available. Extensive experiments demonstrate our method's superiority in delivering high identity faithfulness while preserving the inherent video generation qualities of the original T2V model, outshining prior approaches. Notably, our PersonalVideo seamlessly integrates with pre-trained SD components, such as ControlNet and style LoRA, requiring no extra tuning overhead.