 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Tell Apart: Weakly Supervised Video Anomaly Detection via Disentangled Semantic Alignment
Nov 13, 2025Recent advancements in weakly-supervised video anomaly detection have achieved remarkable performance by applying the multiple instance learning paradigm based on multimodal foundation models such as CLIP to highlight anomalous instances and classify categories. However, their objectives may tend to detect the most salient response segments, while neglecting to mine diverse normal patterns separated from anomalies, and are prone to category confusion due to similar appearance, leading to unsatisfactory fine-grained classification results. Therefore, we propose a novel Disentangled Semantic Alignment Network (DSANet) to explicitly separate abnormal and normal features from coarse-grained and fine-grained aspects, enhancing the distinguishability. Specifically, at the coarse-grained level, we introduce a self-guided normality modeling branch that reconstructs input video features under the guidance of learned normal prototypes, encouraging the model to exploit normality cues inherent in the video, thereby improving the temporal separation of normal patterns and anomalous events. At the fine-grained level, we present a decoupled contrastive semantic alignment mechanism, which first temporally decomposes each video into event-centric and background-centric components using frame-level anomaly scores and then applies visual-language contrastive learning to enhance class-discriminative representations. Comprehensive experiments on two standard benchmarks, namely XD-Violence and UCF-Crime, demonstrate that DSANet outperforms existing state-of-the-art methods.
Holmes-VAU: Towards Long-term Video Anomaly Understanding at Any Granularity
Dec 09, 2024How can we enable models to comprehend video anomalies occurring over varying temporal scales and contexts? Traditional Video Anomaly Understanding (VAU) methods focus on frame-level anomaly prediction, often missing the interpretability of complex and diverse real-world anomalies. Recent multimodal approaches leverage visual and textual data but lack hierarchical annotations that capture both short-term and long-term anomalies. To address this challenge, we introduce HIVAU-70k, a large-scale benchmark for hierarchical video anomaly understanding across any granularity. We develop a semi-automated annotation engine that efficiently scales high-quality annotations by combining manual video segmentation with recursive free-text annotation using large language models (LLMs). This results in over 70,000 multi-granular annotations organized at clip-level, event-level, and video-level segments. For efficient anomaly detection in long videos, we propose the Anomaly-focused Temporal Sampler (ATS). ATS integrates an anomaly scorer with a density-aware sampler to adaptively select frames based on anomaly scores, ensuring that the multimodal LLM concentrates on anomaly-rich regions, which significantly enhances both efficiency and accuracy. Extensive experiments demonstrate that our hierarchical instruction data markedly improves anomaly comprehension. The integrated ATS and visual-language model outperform traditional methods in processing long videos. Our benchmark and model are publicly available at https://github.com/pipixin321/HolmesVAU.
Improving Multi-modal Large Language Model through Boosting Vision Capabilities
Oct 17, 2024



We focus on improving the visual understanding capability for boosting the vision-language models. We propose \textbf{Arcana}, a multiModal language model, which introduces two crucial techniques. First, we present Multimodal LoRA (MM-LoRA), a module designed to enhance the decoder. Unlike traditional language-driven decoders, MM-LoRA consists of two parallel LoRAs -- one for vision and one for language -- each with its own parameters. This disentangled parameters design allows for more specialized learning in each modality and better integration of multimodal information. Second, we introduce the Query Ladder adapter (QLadder) to improve the visual encoder. QLadder employs a learnable ``\textit{ladder}'' structure to deeply aggregates the intermediate representations from the frozen pretrained visual encoder (e.g., CLIP image encoder). This enables the model to learn new and informative visual features, as well as remaining the powerful capabilities of the pretrained visual encoder. These techniques collectively enhance Arcana's visual perception power, enabling it to leverage improved visual information for more accurate and contextually relevant outputs across various multimodal scenarios. Extensive experiments and ablation studies demonstrate the effectiveness and generalization capability of our Arcana. The code and re-annotated data are available at \url{https://arcana-project-page.github.io}.
Cross-video Identity Correlating for Person Re-identification Pre-training
Sep 27, 2024



Recent researches have proven that pre-training on large-scale person images extracted from internet videos is an effective way in learning better representations for person re-identification. However, these researches are mostly confined to pre-training at the instance-level or single-video tracklet-level. They ignore the identity-invariance in images of the same person across different videos, which is a key focus in person re-identification. To address this issue, we propose a Cross-video Identity-cOrrelating pre-traiNing (CION) framework. Defining a noise concept that comprehensively considers both intra-identity consistency and inter-identity discrimination, CION seeks the identity correlation from cross-video images by modeling it as a progressive multi-level denoising problem. Furthermore, an identity-guided self-distillation loss is proposed to implement better large-scale pre-training by mining the identity-invariance within person images. We conduct extensive experiments to verify the superiority of our CION in terms of efficiency and performance. CION achieves significantly leading performance with even fewer training samples. For example, compared with the previous state-of-the-art~\cite{ISR}, CION with the same ResNet50-IBN achieves higher mAP of 93.3\% and 74.3\% on Market1501 and MSMT17, while only utilizing 8\% training samples. Finally, with CION demonstrating superior model-agnostic ability, we contribute a model zoo named ReIDZoo to meet diverse research and application needs in this field. It contains a series of CION pre-trained models with spanning structures and parameters, totaling 32 models with 10 different structures, including GhostNet, ConvNext, RepViT, FastViT and so on. The code and models will be made publicly available at https://github.com/Zplusdragon/CION_ReIDZoo.
Holmes-VAD: Towards Unbiased and Explainable Video Anomaly Detection via Multi-modal LLM
Jun 18, 2024



Towards open-ended Video Anomaly Detection (VAD), existing methods often exhibit biased detection when faced with challenging or unseen events and lack interpretability. To address these drawbacks, we propose Holmes-VAD, a novel framework that leverages precise temporal supervision and rich multimodal instructions to enable accurate anomaly localization and comprehensive explanations. Firstly, towards unbiased and explainable VAD system, we construct the first large-scale multimodal VAD instruction-tuning benchmark, i.e., VAD-Instruct50k. This dataset is created using a carefully designed semi-automatic labeling paradigm. Efficient single-frame annotations are applied to the collected untrimmed videos, which are then synthesized into high-quality analyses of both abnormal and normal video clips using a robust off-the-shelf video captioner and a large language model (LLM). Building upon the VAD-Instruct50k dataset, we develop a customized solution for interpretable video anomaly detection. We train a lightweight temporal sampler to select frames with high anomaly response and fine-tune a multimodal large language model (LLM) to generate explanatory content. Extensive experimental results validate the generality and interpretability of the proposed Holmes-VAD, establishing it as a novel interpretable technique for real-world video anomaly analysis. To support the community, our benchmark and model will be publicly available at https://github.com/pipixin321/HolmesVAD.
GlanceVAD: Exploring Glance Supervision for Label-efficient Video Anomaly Detection
Mar 12, 2024



In recent years, video anomaly detection has been extensively investigated in both unsupervised and weakly supervised settings to alleviate costly temporal labeling. Despite significant progress, these methods still suffer from unsatisfactory results such as numerous false alarms, primarily due to the absence of precise temporal anomaly annotation. In this paper, we present a novel labeling paradigm, termed "glance annotation", to achieve a better balance between anomaly detection accuracy and annotation cost. Specifically, glance annotation is a random frame within each abnormal event, which can be easily accessed and is cost-effective. To assess its effectiveness, we manually annotate the glance annotations for two standard video anomaly detection datasets: UCF-Crime and XD-Violence. Additionally, we propose a customized GlanceVAD method, that leverages gaussian kernels as the basic unit to compose the temporal anomaly distribution, enabling the learning of diverse and robust anomaly representations from the glance annotations. Through comprehensive analysis and experiments, we verify that the proposed labeling paradigm can achieve an excellent trade-off between annotation cost and model performance. Extensive experimental results also demonstrate the effectiveness of our GlanceVAD approach, which significantly outperforms existing advanced unsupervised and weakly supervised methods. Code and annotations will be publicly available at https://github.com/pipixin321/GlanceVAD.
HR-Pro: Point-supervised Temporal Action Localization via Hierarchical Reliability Propagation
Aug 24, 2023



Point-supervised Temporal Action Localization (PSTAL) is an emerging research direction for label-efficient learning. However, current methods mainly focus on optimizing the network either at the snippet-level or the instance-level, neglecting the inherent reliability of point annotations at both levels. In this paper, we propose a Hierarchical Reliability Propagation (HR-Pro) framework, which consists of two reliability-aware stages: Snippet-level Discrimination Learning and Instance-level Completeness Learning, both stages explore the efficient propagation of high-confidence cues in point annotations. For snippet-level learning, we introduce an online-updated memory to store reliable snippet prototypes for each class. We then employ a Reliability-aware Attention Block to capture both intra-video and inter-video dependencies of snippets, resulting in more discriminative and robust snippet representation. For instance-level learning, we propose a point-based proposal generation approach as a means of connecting snippets and instances, which produces high-confidence proposals for further optimization at the instance level. Through multi-level reliability-aware learning, we obtain more reliable confidence scores and more accurate temporal boundaries of predicted proposals. Our HR-Pro achieves state-of-the-art performance on multiple challenging benchmarks, including an impressive average mAP of 60.3% on THUMOS14. Notably, our HR-Pro largely surpasses all previous point-supervised methods, and even outperforms several competitive fully supervised methods. Code will be available at https://github.com/pipixin321/HR-Pro.
Optimization of Forcemyography Sensor Placement for Arm Movement Recognition
Jul 22, 2022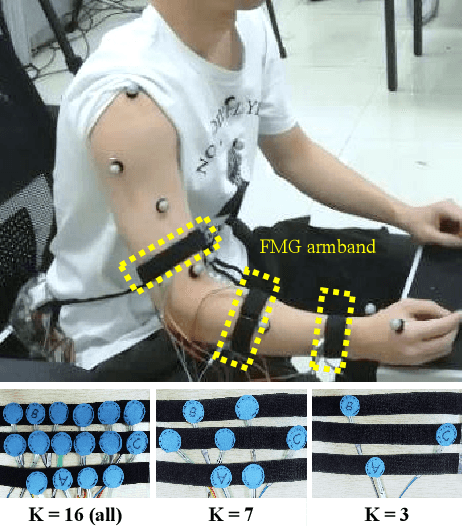
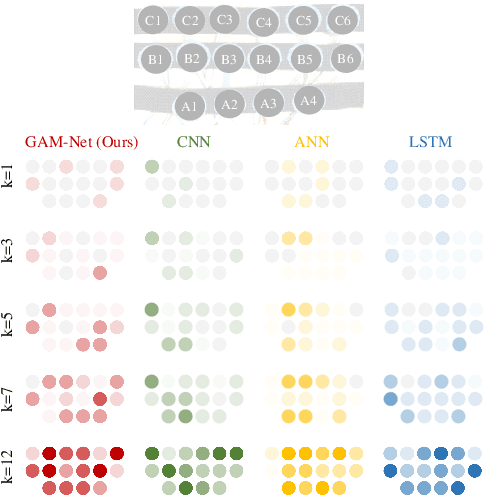
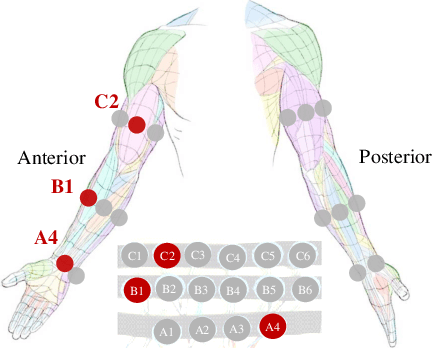
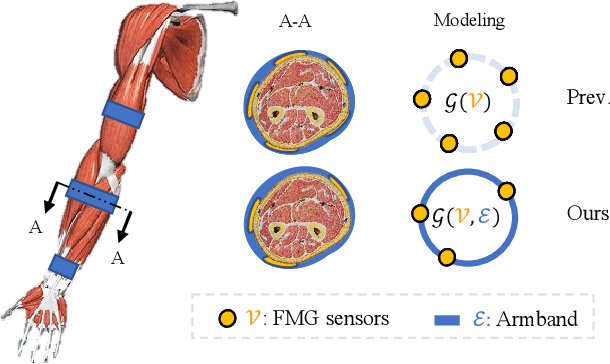
How to design an optimal wearable device for human movement recognition is vital to reliable and accurate human-machine collaboration. Previous works mainly fabricate wearable devices heuristically. Instead, this paper raises an academic question: can we design an optimization algorithm to optimize the fabrication of wearable devices such as figuring out the best sensor arrangement automatically? Specifically, this work focuses on optimizing the placement of Forcemyography (FMG) sensors for FMG armbands in the application of arm movement recognition. Firstly, based on graph theory, the armband is modeled considering sensors' signals and connectivity. Then, a Graph-based Armband Modeling Network (GAM-Net) is introduced for arm movement recognition. Afterward, the sensor placement optimization for FMG armbands is formulated and an optimization algorithm with greedy local search is proposed. To study the effectiveness of our optimization algorithm, a dataset for mechanical maintenance tasks using FMG armbands with 16 sensors is collected. Our experiments show that using only 4 sensors optimized with our algorithm can help maintain a comparable recognition accuracy to using all sensors. Finally, the optimized sensor placement result is verified from a physiological view. This work would like to shed light on the automatic fabrication of wearable devices considering downstream tasks, such as human biological signal collection and movement recognition. Our code and dataset are available at https://github.com/JerryX1110/IROS22-FMG-Sensor-Optimization
Context-aware Proposal Network for Temporal Action Detection
Jun 18, 2022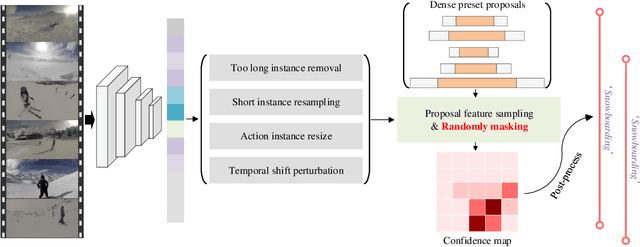
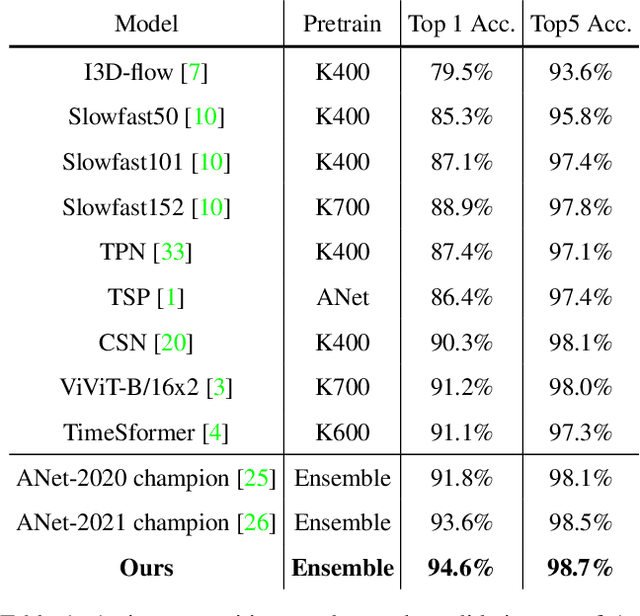

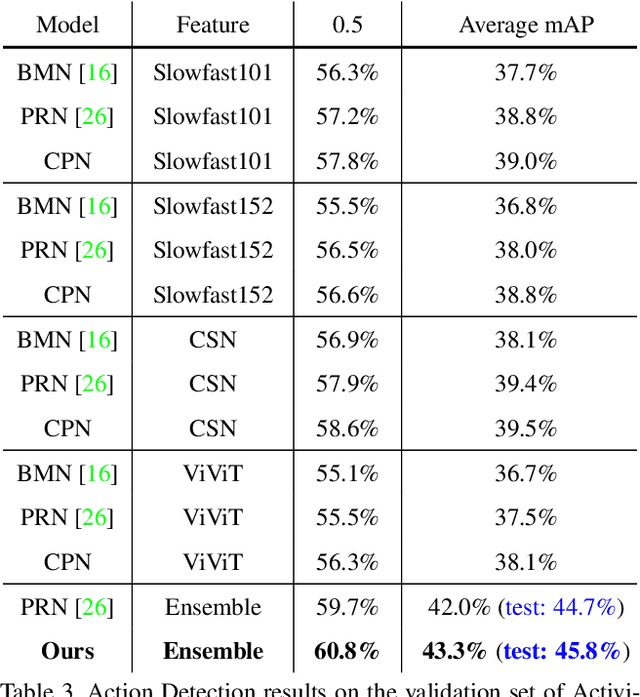
This technical report presents our first place winning solution for temporal action detection task in CVPR-2022 AcitivityNet Challenge. The task aims to localize temporal boundaries of action instances with specific classes in long untrimmed videos. Recent mainstream attempts are based on dense boundary matchings and enumerate all possible combinations to produce proposals. We argue that the generated proposals contain rich contextual information, which may benefits detection confidence prediction. To this end, our method mainly consists of the following three steps: 1) action classification and feature extraction by Slowfast, CSN, TimeSformer, TSP, I3D-flow, VGGish-audio, TPN and ViViT; 2) proposal generation. Our proposed Context-aware Proposal Network (CPN) builds on top of BMN, GTAD and PRN to aggregate contextual information by randomly masking some proposal features. 3) action detection. The final detection prediction is calculated by assigning the proposals with corresponding video-level classifcation results. Finally, we ensemble the results under different feature combination settings and achieve 45.8% performance on the test set, which improves the champion result in CVPR-2021 ActivityNet Challenge by 1.1% in terms of average mAP.