 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWilliam Wang
Knowledge of Knowledge: Exploring Known-Unknowns Uncertainty with Large Language Models
May 23, 2023
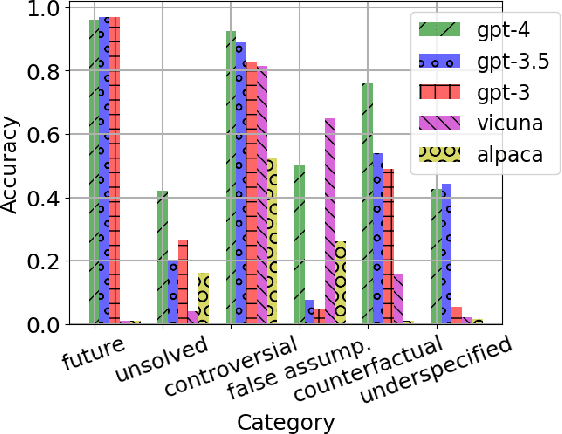

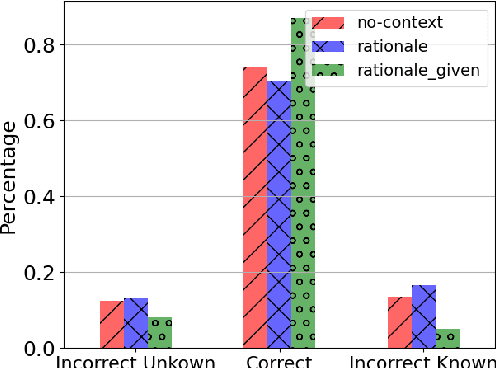
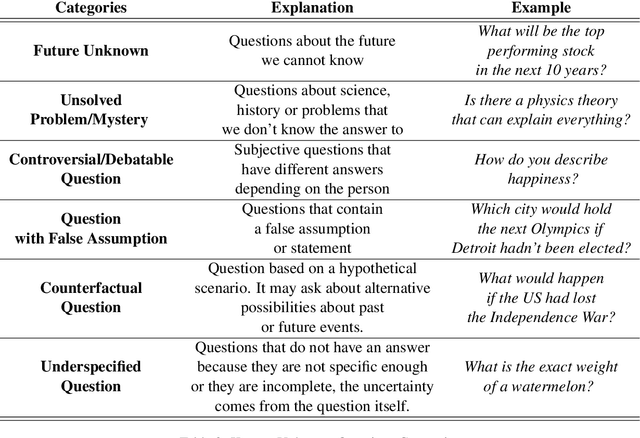
This paper investigates the capabilities of Large Language Models (LLMs) in the context of understanding their own knowledge and measuring their uncertainty. We argue this is an important feature for mitigating hallucinations. Specifically, we focus on addressing \textit{known-unknown} questions, characterized by high uncertainty due to the absence of definitive answers. To facilitate our study, we collect a dataset with new Known-Unknown Questions (KUQ) and propose a novel categorization scheme to elucidate the sources of uncertainty. Subsequently, we assess the LLMs' ability to differentiate between known and unknown questions and classify them accordingly. Moreover, we evaluate the quality of their answers in an Open-Ended QA setting. To quantify the uncertainty expressed in the answers, we create a semantic evaluation method that measures the model's accuracy in expressing uncertainty between known vs unknown questions.
STREET: A Multi-Task Structured Reasoning and Explanation Benchmark
Feb 13, 2023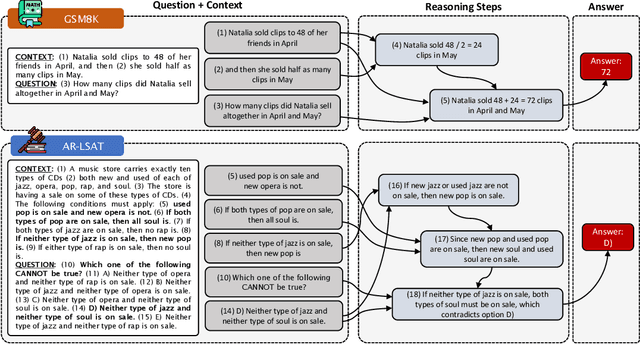
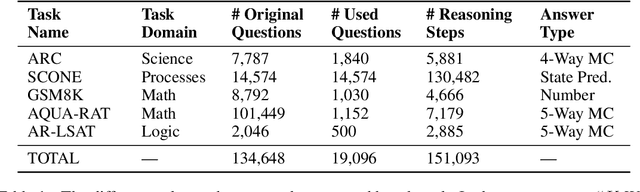
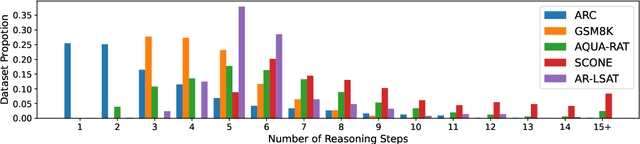
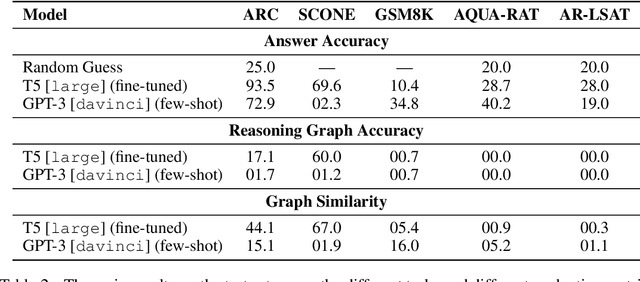
We introduce STREET, a unified multi-task and multi-domain natural language reasoning and explanation benchmark. Unlike most existing question-answering (QA) datasets, we expect models to not only answer questions, but also produce step-by-step structured explanations describing how premises in the question are used to produce intermediate conclusions that can prove the correctness of a certain answer. We perform extensive evaluation with popular language models such as few-shot prompting GPT-3 and fine-tuned T5. We find that these models still lag behind human performance when producing such structured reasoning steps. We believe this work will provide a way for the community to better train and test systems on multi-step reasoning and explanations in natural language.
A Non-Asymptotic Analysis of Oversmoothing in Graph Neural Networks
Dec 21, 2022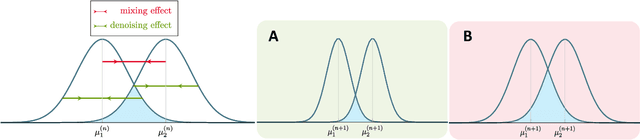

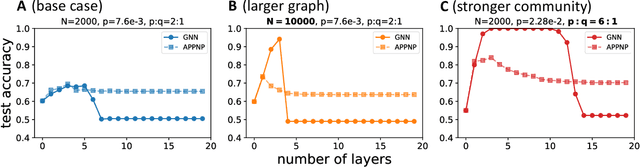
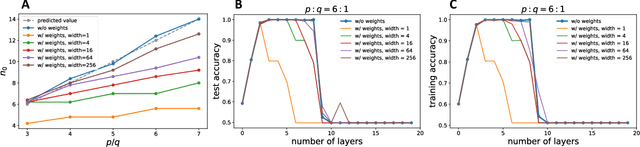
A central challenge of building more powerful Graph Neural Networks (GNNs) is the oversmoothing phenomenon, where increasing the network depth leads to homogeneous node representations and thus worse classification performance. While previous works have only demonstrated that oversmoothing is inevitable when the number of graph convolutions tends to infinity, in this paper, we precisely characterize the mechanism behind the phenomenon via a non-asymptotic analysis. Specifically, we distinguish between two different effects when applying graph convolutions -- an undesirable mixing effect that homogenizes node representations in different classes, and a desirable denoising effect that homogenizes node representations in the same class. By quantifying these two effects on random graphs sampled from the Contextual Stochastic Block Model (CSBM), we show that oversmoothing happens once the mixing effect starts to dominate the denoising effect, and the number of layers required for this transition is $O(\log N/\log (\log N))$ for sufficiently dense graphs with $N$ nodes. We also extend our analysis to study the effects of Personalized PageRank (PPR) on oversmoothing. Our results suggest that while PPR mitigates oversmoothing at deeper layers, PPR-based architectures still achieve their best performance at a shallow depth and are outperformed by the graph convolution approach on certain graphs. Finally, we support our theoretical results with numerical experiments, which further suggest that the oversmoothing phenomenon observed in practice may be exacerbated by the difficulty of optimizing deep GNN models.
Holistic Evaluation of Language Models
Nov 16, 2022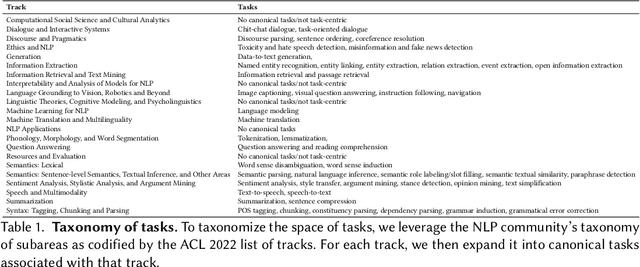



Language models (LMs) are becoming the foundation for almost all major language technologies, but their capabilities, limitations, and risks are not well understood. We present Holistic Evaluation of Language Models (HELM) to improve the transparency of language models. First, we taxonomize the vast space of potential scenarios (i.e. use cases) and metrics (i.e. desiderata) that are of interest for LMs. Then we select a broad subset based on coverage and feasibility, noting what's missing or underrepresented (e.g. question answering for neglected English dialects, metrics for trustworthiness). Second, we adopt a multi-metric approach: We measure 7 metrics (accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency) for each of 16 core scenarios when possible (87.5% of the time). This ensures metrics beyond accuracy don't fall to the wayside, and that trade-offs are clearly exposed. We also perform 7 targeted evaluations, based on 26 targeted scenarios, to analyze specific aspects (e.g. reasoning, disinformation). Third, we conduct a large-scale evaluation of 30 prominent language models (spanning open, limited-access, and closed models) on all 42 scenarios, 21 of which were not previously used in mainstream LM evaluation. Prior to HELM, models on average were evaluated on just 17.9% of the core HELM scenarios, with some prominent models not sharing a single scenario in common. We improve this to 96.0%: now all 30 models have been densely benchmarked on the same core scenarios and metrics under standardized conditions. Our evaluation surfaces 25 top-level findings. For full transparency, we release all raw model prompts and completions publicly for further analysis, as well as a general modular toolkit. We intend for HELM to be a living benchmark for the community, continuously updated with new scenarios, metrics, and models.
LAD: Language Augmented Diffusion for Reinforcement Learning
Oct 27, 2022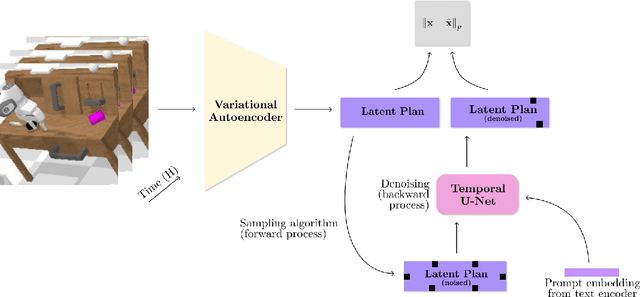
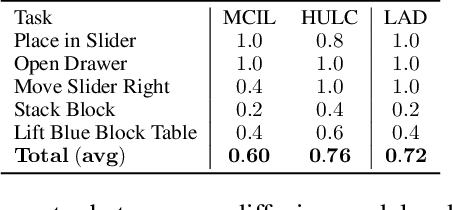
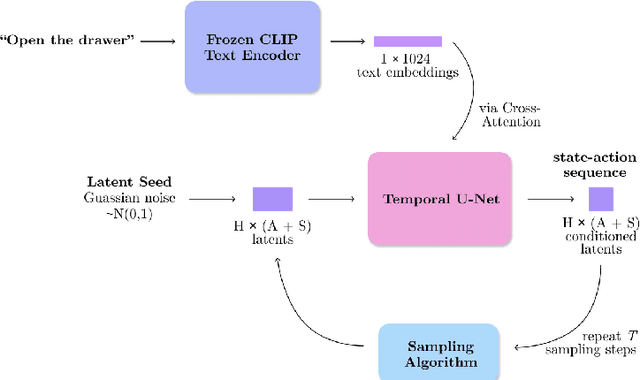

Learning skills from language provides a powerful avenue for generalization in reinforcement learning, although it remains a challenging task as it requires agents to capture the complex interdependencies between language, actions, and states. In this paper, we propose leveraging Language Augmented Diffusion models as a planner conditioned on language (LAD). We demonstrate the comparable performance of LAD with the state-of-the-art on the CALVIN language robotics benchmark with a much simpler architecture that contains no inductive biases specialized to robotics, achieving an average success rate (SR) of 72% compared to the best performance of 76%. We also conduct an analysis on the properties of language conditioned diffusion in reinforcement learning.
DecAF: Joint Decoding of Answers and Logical Forms for Question Answering over Knowledge Bases
Sep 30, 2022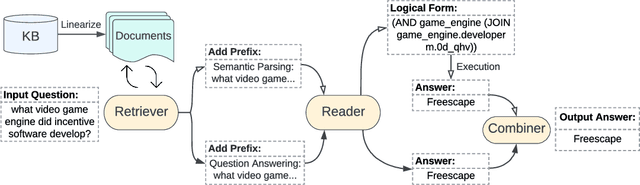
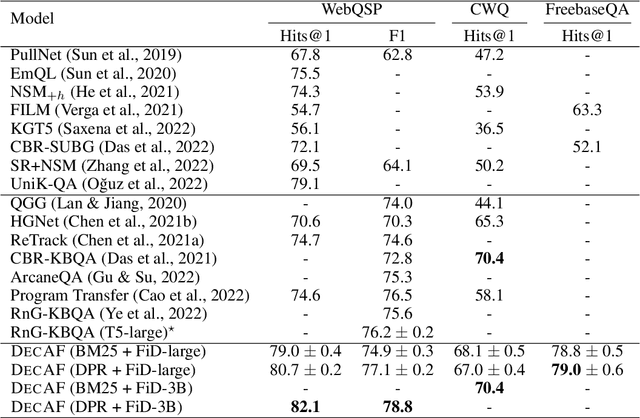
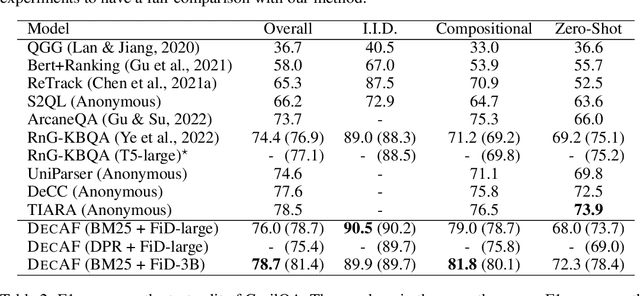
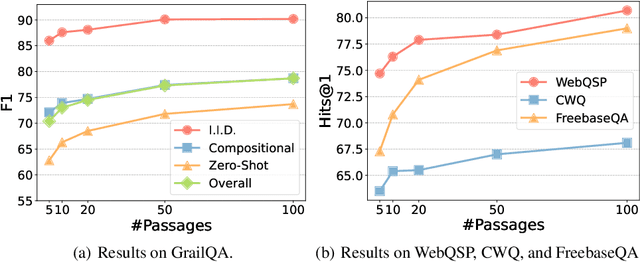
Question answering over knowledge bases (KBs) aims to answer natural language questions with factual information such as entities and relations in KBs. Previous methods either generate logical forms that can be executed over KBs to obtain final answers or predict answers directly. Empirical results show that the former often produces more accurate answers, but it suffers from non-execution issues due to potential syntactic and semantic errors in the generated logical forms. In this work, we propose a novel framework DecAF that jointly generates both logical forms and direct answers, and then combines the merits of them to get the final answers. Moreover, different from most of the previous methods, DecAF is based on simple free-text retrieval without relying on any entity linking tools -- this simplification eases its adaptation to different datasets. DecAF achieves new state-of-the-art accuracy on WebQSP, FreebaseQA, and GrailQA benchmarks, while getting competitive results on the ComplexWebQuestions benchmark.
Emotion Recognition in Conversation using Probabilistic Soft Logic
Jul 14, 2022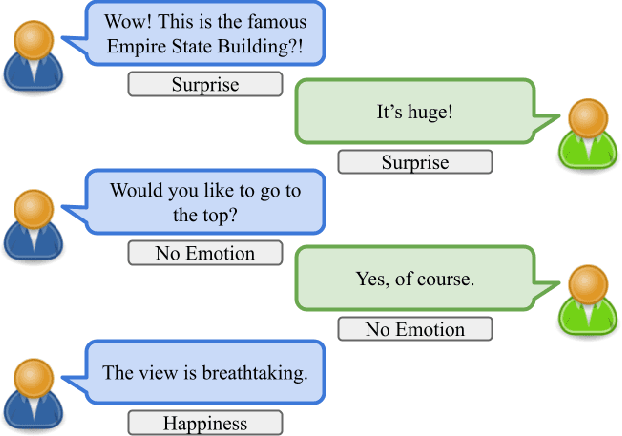

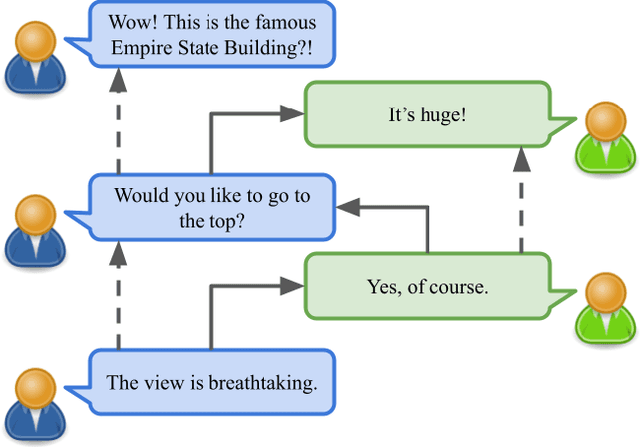
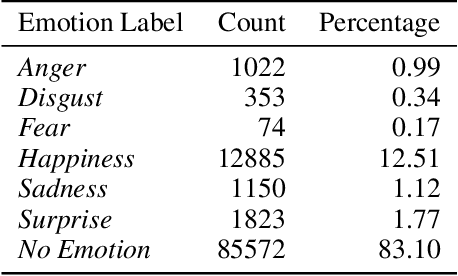
Creating agents that can both appropriately respond to conversations and understand complex human linguistic tendencies and social cues has been a long standing challenge in the NLP community. A recent pillar of research revolves around emotion recognition in conversation (ERC); a sub-field of emotion recognition that focuses on conversations or dialogues that contain two or more utterances. In this work, we explore an approach to ERC that exploits the use of neural embeddings along with complex structures in dialogues. We implement our approach in a framework called Probabilistic Soft Logic (PSL), a declarative templating language that uses first-order like logical rules, that when combined with data, define a particular class of graphical model. Additionally, PSL provides functionality for the incorporation of results from neural models into PSL models. This allows our model to take advantage of advanced neural methods, such as sentence embeddings, and logical reasoning over the structure of a dialogue. We compare our method with state-of-the-art purely neural ERC systems, and see almost a 20% improvement. With these results, we provide an extensive qualitative and quantitative analysis over the DailyDialog conversation dataset.
NeuPSL: Neural Probabilistic Soft Logic
May 27, 2022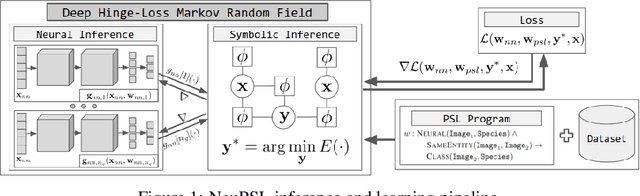

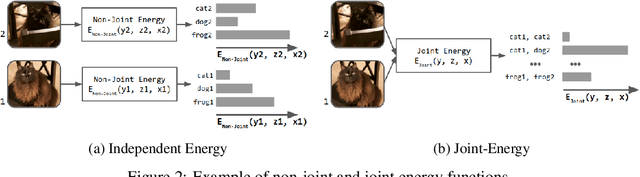
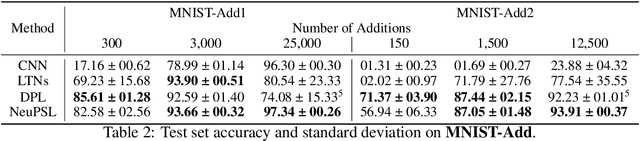
We present Neural Probabilistic Soft Logic (NeuPSL), a novel neuro-symbolic (NeSy) framework that unites state-of-the-art symbolic reasoning with the low-level perception of deep neural networks. To explicitly model the boundary between neural and symbolic representations, we introduce NeSy Energy-Based Models, a general family of energy-based models that combine neural and symbolic reasoning. Using this framework, we show how to seamlessly integrate neural and symbolic parameter learning and inference. We perform an extensive empirical evaluation and show that NeuPSL outperforms existing methods on joint inference and has significantly lower variance in almost all settings.
On the Opportunities and Risks of Foundation Models
Aug 18, 2021



AI is undergoing a paradigm shift with the rise of models (e.g., BERT, DALL-E, GPT-3) that are trained on broad data at scale and are adaptable to a wide range of downstream tasks. We call these models foundation models to underscore their critically central yet incomplete character. This report provides a thorough account of the opportunities and risks of foundation models, ranging from their capabilities (e.g., language, vision, robotics, reasoning, human interaction) and technical principles(e.g., model architectures, training procedures, data, systems, security, evaluation, theory) to their applications (e.g., law, healthcare, education) and societal impact (e.g., inequity, misuse, economic and environmental impact, legal and ethical considerations). Though foundation models are based on standard deep learning and transfer learning, their scale results in new emergent capabilities,and their effectiveness across so many tasks incentivizes homogenization. Homogenization provides powerful leverage but demands caution, as the defects of the foundation model are inherited by all the adapted models downstream. Despite the impending widespread deployment of foundation models, we currently lack a clear understanding of how they work, when they fail, and what they are even capable of due to their emergent properties. To tackle these questions, we believe much of the critical research on foundation models will require deep interdisciplinary collaboration commensurate with their fundamentally sociotechnical nature.