 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroformer: Multimodal and Multitask Generative Pretraining for Brain Data
Nov 08, 2023



State-of-the-art systems neuroscience experiments yield large-scale multimodal data, and these data sets require new tools for analysis. Inspired by the success of large pretrained models in vision and language domains, we reframe the analysis of large-scale, cellular-resolution neuronal spiking data into an autoregressive spatiotemporal generation problem. Neuroformer is a multimodal, multitask generative pretrained transformer (GPT) model that is specifically designed to handle the intricacies of data in systems neuroscience. It scales linearly with feature size, can process an arbitrary number of modalities, and is adaptable to downstream tasks, such as predicting behavior. We first trained Neuroformer on simulated datasets, and found that it both accurately predicted simulated neuronal circuit activity, and also intrinsically inferred the underlying neural circuit connectivity, including direction. When pretrained to decode neural responses, the model predicted the behavior of a mouse with only few-shot fine-tuning, suggesting that the model begins learning how to do so directly from the neural representations themselves, without any explicit supervision. We used an ablation study to show that joint training on neuronal responses and behavior boosted performance, highlighting the model's ability to associate behavioral and neural representations in an unsupervised manner. These findings show that Neuroformer can analyze neural datasets and their emergent properties, informing the development of models and hypotheses associated with the brain.
Deep Adversarial Belief Networks
Sep 25, 2019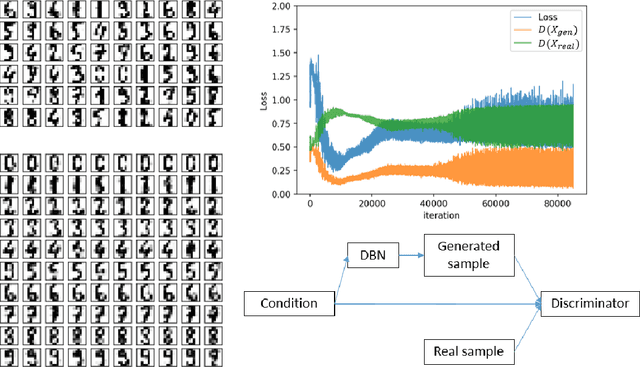

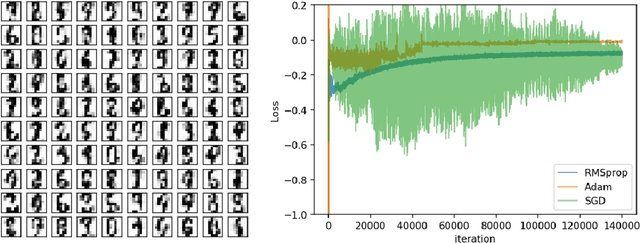
We present a novel adversarial framework for training deep belief networks (DBNs), which includes replacing the generator network in the methodology of generative adversarial networks (GANs) with a DBN and developing a highly parallelizable numerical algorithm for training the resulting architecture in a stochastic manner. Unlike the existing techniques, this framework can be applied to the most general form of DBNs with no requirement for back propagation. As such, it lays a new foundation for developing DBNs on a par with GANs with various regularization units, such as pooling and normalization. Foregoing back-propagation, our framework also exhibits superior scalability as compared to other DBN and GAN learning techniques. We present a number of numerical experiments in computer vision as well as neurosciences to illustrate the main advantages of our approach.
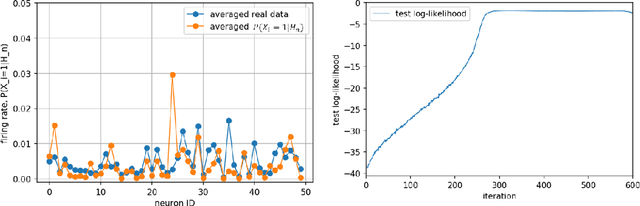
Efficient non-conjugate Gaussian process factor models for spike count data using polynomial approximations
Jun 07, 2019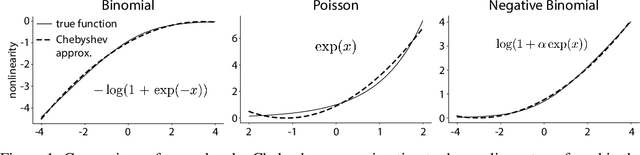

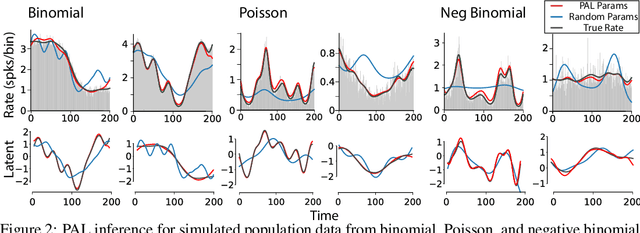
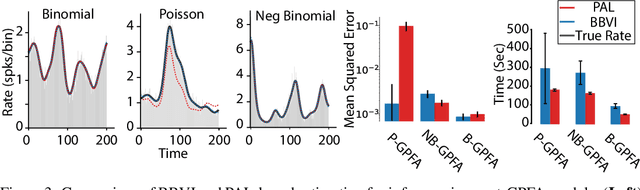
Gaussian Process Factor Analysis (GPFA) has been broadly applied to the problem of identifying smooth, low-dimensional temporal structure underlying large-scale neural recordings. However, spike trains are non-Gaussian, which motivates combining GPFA with discrete observation models for binned spike count data. The drawback to this approach is that GPFA priors are not conjugate to count model likelihoods, which makes inference challenging. Here we address this obstacle by introducing a fast, approximate inference method for non-conjugate GPFA models. Our approach uses orthogonal second-order polynomials to approximate the nonlinear terms in the non-conjugate log-likelihood, resulting in a method we refer to as polynomial approximate log-likelihood (PAL) estimators. This approximation allows for accurate closed-form evaluation of marginal likelihood and fast numerical optimization for parameters and hyperparameters. We derive PAL estimators for GPFA models with binomial, Poisson, and negative binomial observations, and additionally show that the parameters obtained can be used to initialize black-box variational inference, which significantly speeds up and stabilizes the inference procedure for these factor analytic models. We apply these methods to data from mouse visual cortex and monkey higher-order visual and parietal cortices, and compare GPFA under three different spike count observation models to traditional GPFA. We demonstrate that PAL estimators achieve fast and accurate extraction of latent structure from multi-neuron spike train data.