 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoMem: Context Management with A Decoupled Long-Context Model
May 29, 2026Context management enables agentic models to solve long-horizon tasks through iterative summarization of previous interaction histories. However, this process typically incurs substantial decoding overhead for the extra summarization tokens, which significantly affect the end-to-end response latency at deployment. In this paper, we introduce CoMem, a novel framework that decouples memory management from the primary agent workflow, enabling these processes to execute in parallel. We propose a $k$-step-off asynchronous pipeline that overlaps the memory model's summarization with the agent's inference, effectively masking the latency of context processing. To ensure robustness under this asynchronous setting, we introduce a reward-driven training strategy that aligns the memory model to capture sufficient statistics for the agent's decision-making. Theoretical analysis confirms that CoMem offers a superior efficiency-effectiveness trade-off compared to coupled architectures. Our extensive experimental results on SWE-Bench-Verified show that CoMem provides 1.4x latency improvements upon vanilla long-context solutions while preserving most of the performance. Furthermore, we demonstrate that these latency gains scale favorably with increased system throughput, offering a modular path forward for the independent optimization of agent reasoning and memory compression.
Learning with Rare Success but Rich Feedback via Reflection-Enhanced Self-Distillation
May 12, 2026Enabling Large Language Models (LLMs) to continuously improve from environmental interactions is a central challenge in post-training. While on-policy self-distillation offers a promising paradigm, existing methods predominantly treat environmental feedback as a passive conditioning signal. Consequently, they heavily rely on successful demonstrations and struggle to learn in rare-success regimes. To bridge this gap, we introduce Reflection-Enhanced Self-Distillation (RESD), a framework that transforms raw failure feedback into an active source of corrective supervision. Instead of passively appending feedback, RESD interprets failed trajectories by generating retrospective reflections to diagnose local errors, and curates a persistent global playbook to preserve reusable lessons across training steps. The enriched context enables the self-teacher to provide actionable token-level supervision even in the absence of successful rollouts. Empirical evaluations on multiple continual learning tasks demonstrate that RESD substantially outperforms standard self-distillation baselines. Furthermore, RESD achieves significantly faster early-stage improvement than GRPO with $8\times$ samples using only a single rollout per prompt, highlighting its superior interaction efficiency.
Nemotron-H: A Family of Accurate and Efficient Hybrid Mamba-Transformer Models
Apr 10, 2025



As inference-time scaling becomes critical for enhanced reasoning capabilities, it is increasingly becoming important to build models that are efficient to infer. We introduce Nemotron-H, a family of 8B and 56B/47B hybrid Mamba-Transformer models designed to reduce inference cost for a given accuracy level. To achieve this goal, we replace the majority of self-attention layers in the common Transformer model architecture with Mamba layers that perform constant computation and require constant memory per generated token. We show that Nemotron-H models offer either better or on-par accuracy compared to other similarly-sized state-of-the-art open-sourced Transformer models (e.g., Qwen-2.5-7B/72B and Llama-3.1-8B/70B), while being up to 3$\times$ faster at inference. To further increase inference speed and reduce the memory required at inference time, we created Nemotron-H-47B-Base from the 56B model using a new compression via pruning and distillation technique called MiniPuzzle. Nemotron-H-47B-Base achieves similar accuracy to the 56B model, but is 20% faster to infer. In addition, we introduce an FP8-based training recipe and show that it can achieve on par results with BF16-based training. This recipe is used to train the 56B model. All Nemotron-H models will be released, with support in Hugging Face, NeMo, and Megatron-LM.
Linear Correlation in LM's Compositional Generalization and Hallucination
Feb 06, 2025



The generalization of language models (LMs) is undergoing active debates, contrasting their potential for general intelligence with their struggles with basic knowledge composition (e.g., reverse/transition curse). This paper uncovers the phenomenon of linear correlations in LMs during knowledge composition. For explanation, there exists a linear transformation between certain related knowledge that maps the next token prediction logits from one prompt to another, e.g., "X lives in the city of" $\rightarrow$ "X lives in the country of" for every given X. This mirrors the linearity in human knowledge composition, such as Paris $\rightarrow$ France. Our findings indicate that the linear transformation is resilient to large-scale fine-tuning, generalizing updated knowledge when aligned with real-world relationships, but causing hallucinations when it deviates. Empirical results suggest that linear correlation can serve as a potential identifier of LM's generalization. Finally, we show such linear correlations can be learned with a single feedforward network and pre-trained vocabulary representations, indicating LM generalization heavily relies on the latter.
Next-Token Prediction Task Assumes Optimal Data Ordering for LLM Training in Proof Generation
Oct 30, 2024



In the field of large language model (LLM)-based proof generation, despite being trained on extensive corpora such as OpenWebMath and Arxiv, these models still exhibit only modest performance on proving tasks of moderate difficulty. We believe that this is partly due to the suboptimal order of each proof data used in training. Published proofs often follow a purely logical order, where each step logically proceeds from the previous steps based on the deductive rules. However, this order aims to facilitate the verification of the proof's soundness, rather than to help people and models learn the discovery process of the proof. In proof generation, we argue that the optimal order for one training data sample occurs when the relevant intermediate supervision for a particular proof step in the proof is always positioned to the left of that proof step. We call such order the intuitively sequential order. We validate our claims using two tasks: intuitionistic propositional logic theorem-proving and digit multiplication. Our experiments verify the order effect and provide support for our explanations. We demonstrate that training is most effective when the proof is in the intuitively sequential order. Moreover, the order effect and the performance gap between models trained on different data orders are substantial -- with an 11 percent improvement in proof success rate observed in the propositional logic theorem-proving task, between models trained on the optimal order compared to the worst order.
When is the consistent prediction likely to be a correct prediction?
Jul 08, 2024



Self-consistency (Wang et al., 2023) suggests that the most consistent answer obtained through large language models (LLMs) is more likely to be correct. In this paper, we challenge this argument and propose a nuanced correction. Our observations indicate that consistent answers derived through more computation i.e. longer reasoning texts, rather than simply the most consistent answer across all outputs, are more likely to be correct. This is predominantly because we demonstrate that LLMs can autonomously produce chain-of-thought (CoT) style reasoning with no custom prompts merely while generating longer responses, which lead to consistent predictions that are more accurate. In the zero-shot setting, by sampling Mixtral-8x7B model multiple times and considering longer responses, we achieve 86% of its self-consistency performance obtained through zero-shot CoT prompting on the GSM8K and MultiArith datasets. Finally, we demonstrate that the probability of LLMs generating a longer response is quite low, highlighting the need for decoding strategies conditioned on output length.
Text Grafting: Near-Distribution Weak Supervision for Minority Classes in Text Classification
Jun 17, 2024



For extremely weak-supervised text classification, pioneer research generates pseudo labels by mining texts similar to the class names from the raw corpus, which may end up with very limited or even no samples for the minority classes. Recent works have started to generate the relevant texts by prompting LLMs using the class names or definitions; however, there is a high risk that LLMs cannot generate in-distribution (i.e., similar to the corpus where the text classifier will be applied) data, leading to ungeneralizable classifiers. In this paper, we combine the advantages of these two approaches and propose to bridge the gap via a novel framework, \emph{text grafting}, which aims to obtain clean and near-distribution weak supervision for minority classes. Specifically, we first use LLM-based logits to mine masked templates from the raw corpus, which have a high potential for data synthesis into the target minority class. Then, the templates are filled by state-of-the-art LLMs to synthesize near-distribution texts falling into minority classes. Text grafting shows significant improvement over direct mining or synthesis on minority classes. We also use analysis and case studies to comprehend the property of text grafting.
Evaluating the Smooth Control of Attribute Intensity in Text Generation with LLMs
Jun 06, 2024



Controlling the attribute intensity of text generation is crucial across scenarios (e.g., writing conciseness, chatting emotion, and explanation clarity). The remarkable capabilities of large language models (LLMs) have revolutionized text generation, prompting us to explore such \emph{smooth control} of LLM generation. Specifically, we propose metrics to assess the range, calibration, and consistency of the generated text's attribute intensity in response to varying control values, as well as its relevance to the intended context. To quantify the attribute intensity and context relevance, we propose an effective evaluation framework leveraging the Elo rating system and GPT4, both renowned for their robust alignment with human judgment. We look into two viable training-free methods for achieving smooth control of LLMs: (1) Prompting with semantic shifters, and (2) Modifying internal model representations. The evaluations of these two methods are conducted on $5$ different attributes with various models. Our code and dataset can be obtained from \url{https://github.com/ShangDataLab/Smooth-Control}.
Physics-Informed Data Denoising for Real-Life Sensing Systems
Nov 12, 2023
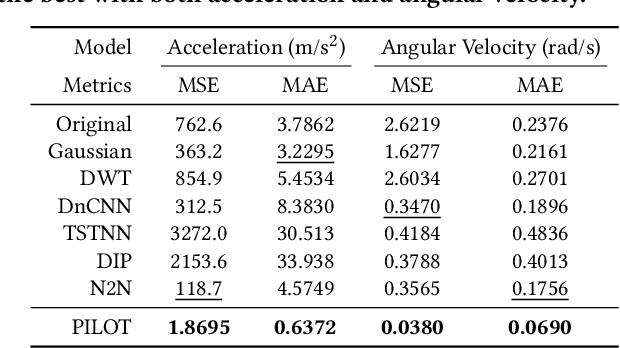


Sensors measuring real-life physical processes are ubiquitous in today's interconnected world. These sensors inherently bear noise that often adversely affects performance and reliability of the systems they support. Classic filtering-based approaches introduce strong assumptions on the time or frequency characteristics of sensory measurements, while learning-based denoising approaches typically rely on using ground truth clean data to train a denoising model, which is often challenging or prohibitive to obtain for many real-world applications. We observe that in many scenarios, the relationships between different sensor measurements (e.g., location and acceleration) are analytically described by laws of physics (e.g., second-order differential equation). By incorporating such physics constraints, we can guide the denoising process to improve even in the absence of ground truth data. In light of this, we design a physics-informed denoising model that leverages the inherent algebraic relationships between different measurements governed by the underlying physics. By obviating the need for ground truth clean data, our method offers a practical denoising solution for real-world applications. We conducted experiments in various domains, including inertial navigation, CO2 monitoring, and HVAC control, and achieved state-of-the-art performance compared with existing denoising methods. Our method can denoise data in real time (4ms for a sequence of 1s) for low-cost noisy sensors and produces results that closely align with those from high-precision, high-cost alternatives, leading to an efficient, cost-effective approach for more accurate sensor-based systems.
Fast-ELECTRA for Efficient Pre-training
Oct 11, 2023



ELECTRA pre-trains language models by detecting tokens in a sequence that have been replaced by an auxiliary model. Although ELECTRA offers a significant boost in efficiency, its potential is constrained by the training cost brought by the auxiliary model. Notably, this model, which is jointly trained with the main model, only serves to assist the training of the main model and is discarded post-training. This results in a substantial amount of training cost being expended in vain. To mitigate this issue, we propose Fast-ELECTRA, which leverages an existing language model as the auxiliary model. To construct a learning curriculum for the main model, we smooth its output distribution via temperature scaling following a descending schedule. Our approach rivals the performance of state-of-the-art ELECTRA-style pre-training methods, while significantly eliminating the computation and memory cost brought by the joint training of the auxiliary model. Our method also reduces the sensitivity to hyper-parameters and enhances the pre-training stability.