 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDancing in Chains: Reconciling Instruction Following and Faithfulness in Language Models
Jul 31, 2024Modern language models (LMs) need to follow human instructions while being faithful; yet, they often fail to achieve both. Here, we provide concrete evidence of a trade-off between instruction following (i.e., follow open-ended instructions) and faithfulness (i.e., ground responses in given context) when training LMs with these objectives. For instance, fine-tuning LLaMA-7B on instruction following datasets renders it less faithful. Conversely, instruction-tuned Vicuna-7B shows degraded performance at following instructions when further optimized on tasks that require contextual grounding. One common remedy is multi-task learning (MTL) with data mixing, yet it remains far from achieving a synergic outcome. We propose a simple yet effective method that relies on Rejection Sampling for Continued Self-instruction Tuning (ReSet), which significantly outperforms vanilla MTL. Surprisingly, we find that less is more, as training ReSet with high-quality, yet substantially smaller data (three-fold less) yields superior results. Our findings offer a better understanding of objective discrepancies in alignment training of LMs.
Personalized Search Via Neural Contextual Semantic Relevance Ranking
Sep 10, 2023



Existing neural relevance models do not give enough consideration for query and item context information which diversifies the search results to adapt for personal preference. To bridge this gap, this paper presents a neural learning framework to personalize document ranking results by leveraging the signals to capture how the document fits into users' context. In particular, it models the relationships between document content and user query context using both lexical representations and semantic embeddings such that the user's intent can be better understood by data enrichment of personalized query context information. Extensive experiments performed on the search dataset, demonstrate the effectiveness of the proposed method.
STREET: A Multi-Task Structured Reasoning and Explanation Benchmark
Feb 13, 2023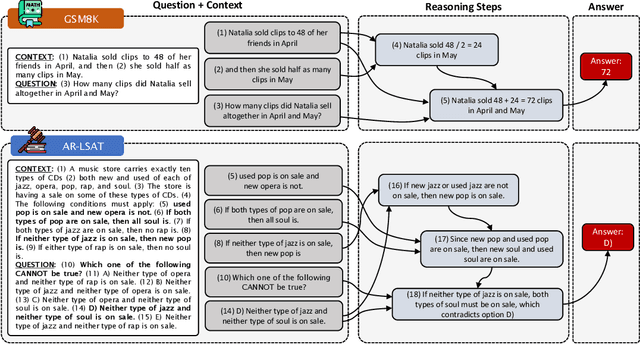
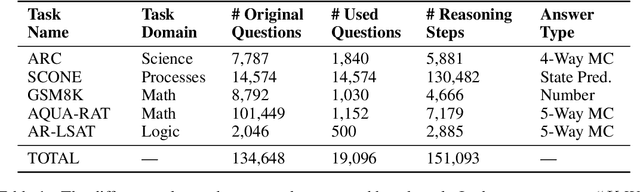
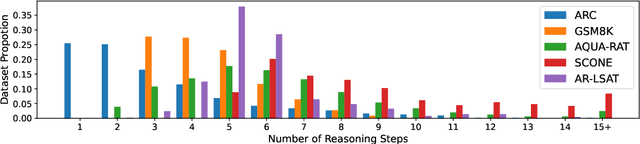
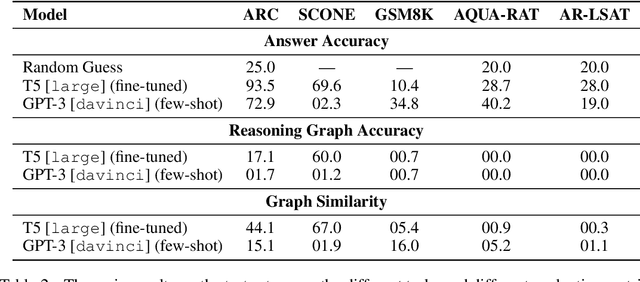
We introduce STREET, a unified multi-task and multi-domain natural language reasoning and explanation benchmark. Unlike most existing question-answering (QA) datasets, we expect models to not only answer questions, but also produce step-by-step structured explanations describing how premises in the question are used to produce intermediate conclusions that can prove the correctness of a certain answer. We perform extensive evaluation with popular language models such as few-shot prompting GPT-3 and fine-tuned T5. We find that these models still lag behind human performance when producing such structured reasoning steps. We believe this work will provide a way for the community to better train and test systems on multi-step reasoning and explanations in natural language.
Tokenization Consistency Matters for Generative Models on Extractive NLP Tasks
Dec 19, 2022



Generative models have been widely applied to solve extractive tasks, where parts of the input is extracted to form the desired output, and achieved significant success. For example, in extractive question answering (QA), generative models have constantly yielded state-of-the-art results. In this work, we identify the issue of tokenization inconsistency that is commonly neglected in training these models. This issue damages the extractive nature of these tasks after the input and output are tokenized inconsistently by the tokenizer, and thus leads to performance drop as well as hallucination. We propose a simple yet effective fix to this issue and conduct a case study on extractive QA. We show that, with consistent tokenization, the model performs better in both in-domain and out-of-domain datasets, with a notable average of +1.7 F2 gain when a BART model is trained on SQuAD and evaluated on 8 QA datasets. Further, the model converges faster, and becomes less likely to generate out-of-context answers. With these findings, we would like to call for more attention on how tokenization should be done when solving extractive tasks and recommend applying consistent tokenization during training.
Improving Cross-task Generalization of Unified Table-to-text Models with Compositional Task Configurations
Dec 17, 2022



There has been great progress in unifying various table-to-text tasks using a single encoder-decoder model trained via multi-task learning (Xie et al., 2022). However, existing methods typically encode task information with a simple dataset name as a prefix to the encoder. This not only limits the effectiveness of multi-task learning, but also hinders the model's ability to generalize to new domains or tasks that were not seen during training, which is crucial for real-world applications. In this paper, we propose compositional task configurations, a set of prompts prepended to the encoder to improve cross-task generalization of unified models. We design the task configurations to explicitly specify the task type, as well as its input and output types. We show that this not only allows the model to better learn shared knowledge across different tasks at training, but also allows us to control the model by composing new configurations that apply novel input-output combinations in a zero-shot manner. We demonstrate via experiments over ten table-to-text tasks that our method outperforms the UnifiedSKG baseline by noticeable margins in both in-domain and zero-shot settings, with average improvements of +0.5 and +12.6 from using a T5-large backbone, respectively.
Language Agnostic Multilingual Information Retrieval with Contrastive Learning
Oct 12, 2022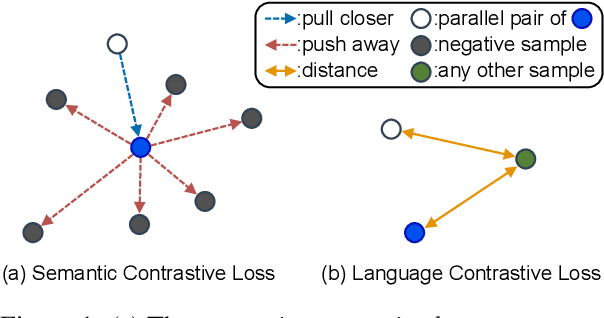
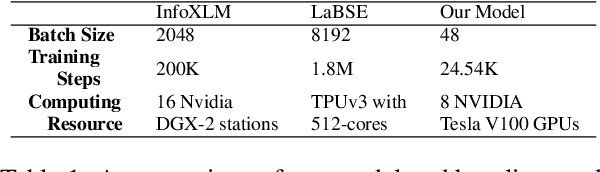
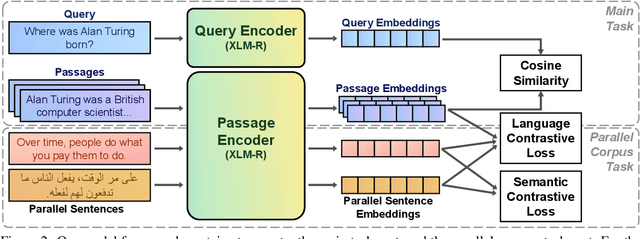
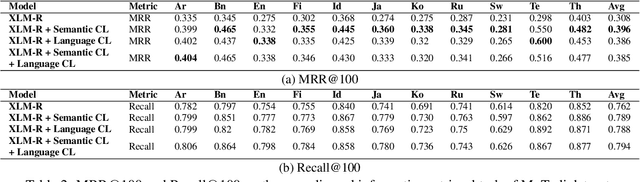
Multilingual information retrieval is challenging due to the lack of training datasets for many low-resource languages. We present an effective method by leveraging parallel and non-parallel corpora to improve the pretrained multilingual language models' cross-lingual transfer ability for information retrieval. We design the semantic contrastive loss as regular contrastive learning to improve the cross-lingual alignment of parallel sentence pairs, and we propose a new contrastive loss, the language contrastive loss, to leverage both parallel corpora and non-parallel corpora to further improve multilingual representation learning. We train our model on an English information retrieval dataset, and test its zero-shot transfer ability to other languages. Our experiment results show that our method brings significant improvement to prior work on retrieval performance, while it requires much less computational effort. Our model can work well even with a small number of parallel corpora. And it can be used as an add-on module to any backbone and other tasks. Our code is available at: https://github.com/xiyanghu/multilingualIR.
Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner
May 18, 2022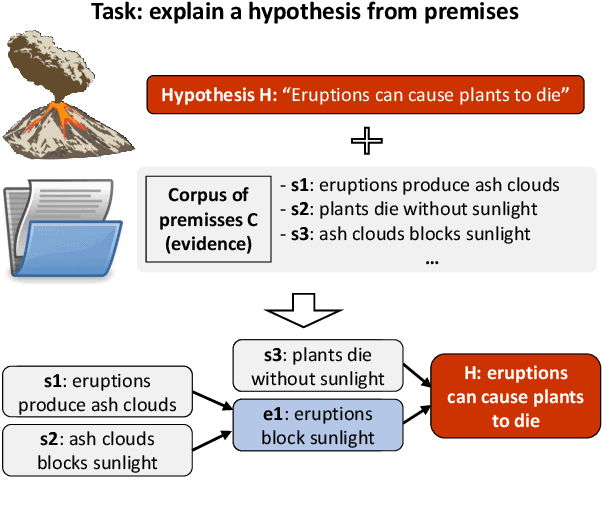
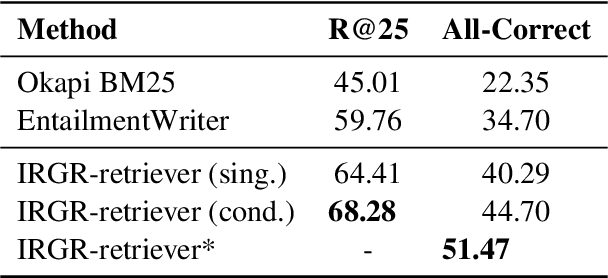
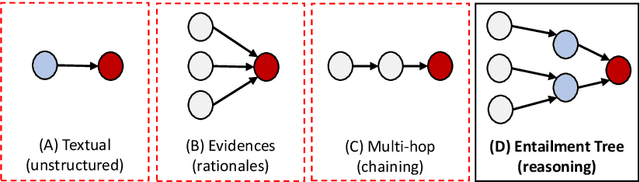
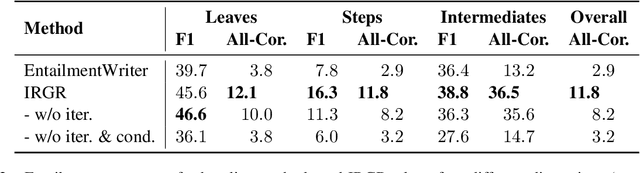
Large language models have achieved high performance on various question answering (QA) benchmarks, but the explainability of their output remains elusive. Structured explanations, called entailment trees, were recently suggested as a way to explain and inspect a QA system's answer. In order to better generate such entailment trees, we propose an architecture called Iterative Retrieval-Generation Reasoner (IRGR). Our model is able to explain a given hypothesis by systematically generating a step-by-step explanation from textual premises. The IRGR model iteratively searches for suitable premises, constructing a single entailment step at a time. Contrary to previous approaches, our method combines generation steps and retrieval of premises, allowing the model to leverage intermediate conclusions, and mitigating the input size limit of baseline encoder-decoder models. We conduct experiments using the EntailmentBank dataset, where we outperform existing benchmarks on premise retrieval and entailment tree generation, with around 300% gain in overall correctness.
Contrastive Document Representation Learning with Graph Attention Networks
Oct 20, 2021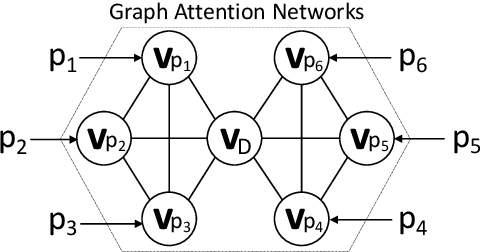
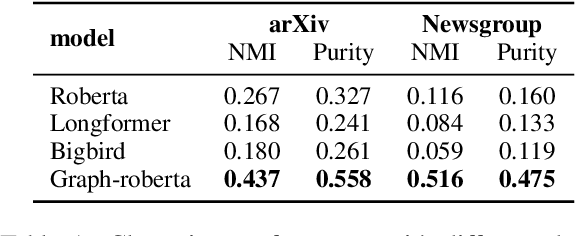
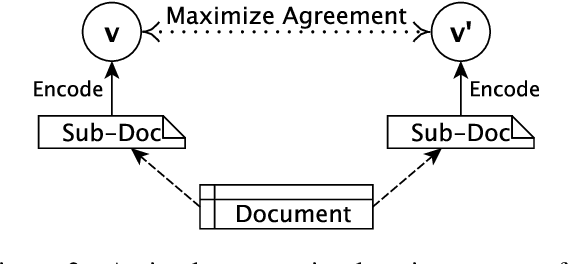
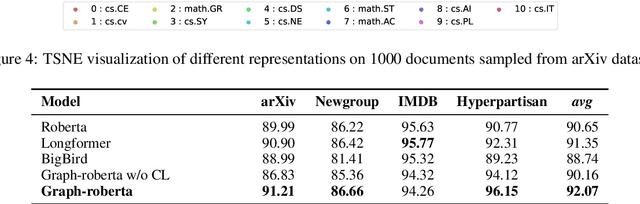
Recent progress in pretrained Transformer-based language models has shown great success in learning contextual representation of text. However, due to the quadratic self-attention complexity, most of the pretrained Transformers models can only handle relatively short text. It is still a challenge when it comes to modeling very long documents. In this work, we propose to use a graph attention network on top of the available pretrained Transformers model to learn document embeddings. This graph attention network allows us to leverage the high-level semantic structure of the document. In addition, based on our graph document model, we design a simple contrastive learning strategy to pretrain our models on a large amount of unlabeled corpus. Empirically, we demonstrate the effectiveness of our approaches in document classification and document retrieval tasks.
Attention-guided Generative Models for Extractive Question Answering
Oct 12, 2021
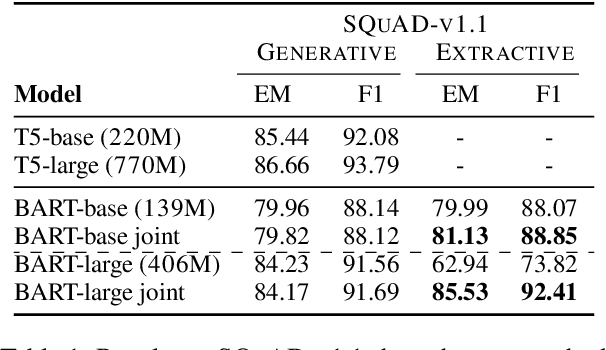
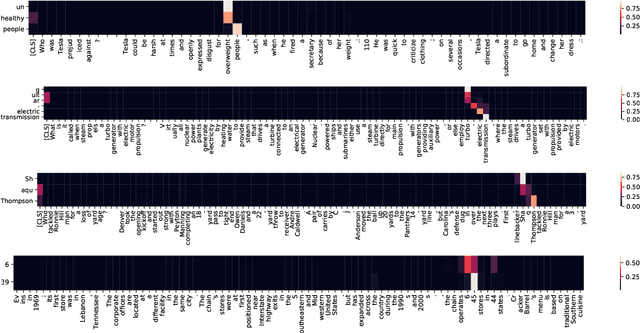
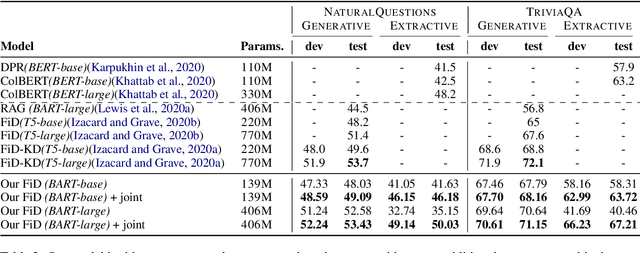
We propose a novel method for applying Transformer models to extractive question answering (QA) tasks. Recently, pretrained generative sequence-to-sequence (seq2seq) models have achieved great success in question answering. Contributing to the success of these models are internal attention mechanisms such as cross-attention. We propose a simple strategy to obtain an extractive answer span from the generative model by leveraging the decoder cross-attention patterns. Viewing cross-attention as an architectural prior, we apply joint training to further improve QA performance. Empirical results show that on open-domain question answering datasets like NaturalQuestions and TriviaQA, our method approaches state-of-the-art performance on both generative and extractive inference, all while using much fewer parameters. Furthermore, this strategy allows us to perform hallucination-free inference while conferring significant improvements to the model's ability to rerank relevant passages.
Multiplicative Position-aware Transformer Models for Language Understanding
Sep 27, 2021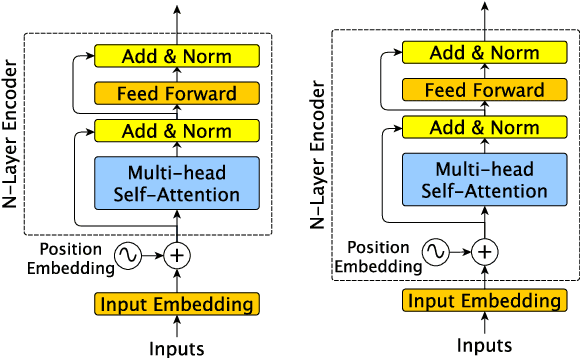

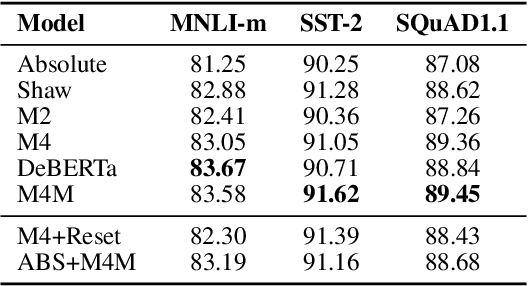
Transformer models, which leverage architectural improvements like self-attention, perform remarkably well on Natural Language Processing (NLP) tasks. The self-attention mechanism is position agnostic. In order to capture positional ordering information, various flavors of absolute and relative position embeddings have been proposed. However, there is no systematic analysis on their contributions and a comprehensive comparison of these methods is missing in the literature. In this paper, we review major existing position embedding methods and compare their accuracy on downstream NLP tasks, using our own implementations. We also propose a novel multiplicative embedding method which leads to superior accuracy when compared to existing methods. Finally, we show that our proposed embedding method, served as a drop-in replacement of the default absolute position embedding, can improve the RoBERTa-base and RoBERTa-large models on SQuAD1.1 and SQuAD2.0 datasets.