 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemToolAgent overview with a simple restaurant booking scenario where the agent retrieves similar memories, receives feedback on an invalid time format, and generates a reflection to update its memory
Jun 06, 2026Modern large language model (LLM) agents can use external tools to help users solve complex tasks. However, for problems that require learning from long-term historical events or from previous agent-environment interactions, LLM agents are required to use memory mechanisms to store and retrieve experiences. While sophisticated memory systems exist for dialogue agents, few studies have empirically examined how to improve agents' tool-using capabilities through past user-agent conversations. We propose MemToolAgent, a framework that improves tool use through memory management. Our approach contains a memory extraction module that processes past experiences into structured memory entries, and a retrieval module that dynamically selects a subset of the stored memory entries. This enables more personalized and accurate responses aligned with user preferences and feedback without requiring LLM fine-tuning. In summary, this work has three main contributions: (1) a unified memory entry format that improves both general-purpose and personalized tool use without LLM fine-tuning, (2) a reflection-based memory extraction that uses environment and user feedback to distill wrong executions into critiques to store, and (3) a retrieval module that chooses how many past experiences to use based on the memory similarity distribution. MemToolAgent achieves 29%, 80%, and 17% relative improvements compared to strong baselines on the WorkBench, NESTFUL, and PEToolBench benchmarks, respectively.
Toward Effective AI Governance: A Review of Principles
May 29, 2025
Artificial Intelligence (AI) governance is the practice of establishing frameworks, policies, and procedures to ensure the responsible, ethical, and safe development and deployment of AI systems. Although AI governance is a core pillar of Responsible AI, current literature still lacks synthesis across such governance frameworks and practices. Objective: To identify which frameworks, principles, mechanisms, and stakeholder roles are emphasized in secondary literature on AI governance. Method: We conducted a rapid tertiary review of nine peer-reviewed secondary studies from IEEE and ACM (20202024), using structured inclusion criteria and thematic semantic synthesis. Results: The most cited frameworks include the EU AI Act and NIST RMF; transparency and accountability are the most common principles. Few reviews detail actionable governance mechanisms or stakeholder strategies. Conclusion: The review consolidates key directions in AI governance and highlights gaps in empirical validation and inclusivity. Findings inform both academic inquiry and practical adoption in organizations.
Towards Zero-Shot Frame Semantic Parsing with Task Agnostic Ontologies and Simple Labels
May 05, 2023



Frame semantic parsing is an important component of task-oriented dialogue systems. Current models rely on a significant amount training data to successfully identify the intent and slots in the user's input utterance. This creates a significant barrier for adding new domains to virtual assistant capabilities, as creation of this data requires highly specialized NLP expertise. In this work we propose OpenFSP, a framework that allows for easy creation of new domains from a handful of simple labels that can be generated without specific NLP knowledge. Our approach relies on creating a small, but expressive, set of domain agnostic slot types that enables easy annotation of new domains. Given such annotation, a matching algorithm relying on sentence encoders predicts the intent and slots for domains defined by end-users. Extensive experiments on the TopV2 dataset shows that our model outperforms strong baselines in this simple labels setting.
STREET: A Multi-Task Structured Reasoning and Explanation Benchmark
Feb 13, 2023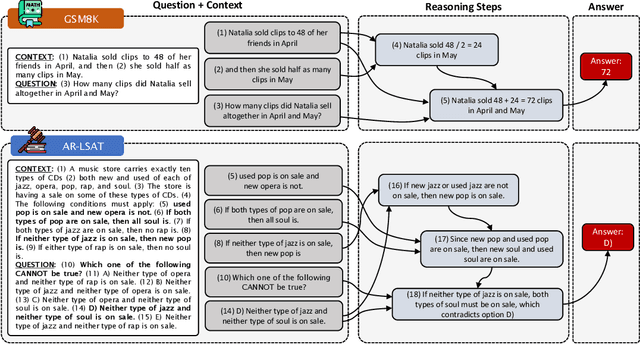
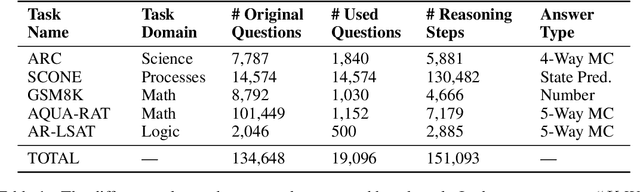
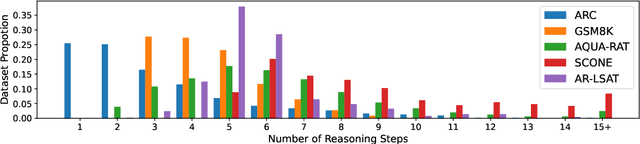
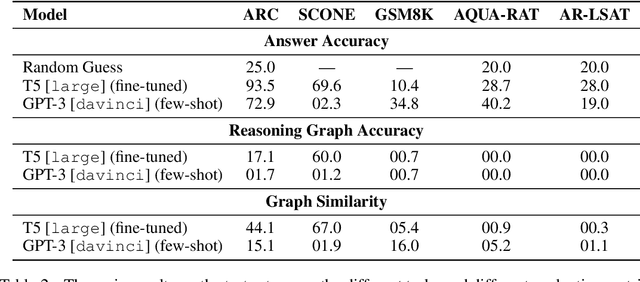
We introduce STREET, a unified multi-task and multi-domain natural language reasoning and explanation benchmark. Unlike most existing question-answering (QA) datasets, we expect models to not only answer questions, but also produce step-by-step structured explanations describing how premises in the question are used to produce intermediate conclusions that can prove the correctness of a certain answer. We perform extensive evaluation with popular language models such as few-shot prompting GPT-3 and fine-tuned T5. We find that these models still lag behind human performance when producing such structured reasoning steps. We believe this work will provide a way for the community to better train and test systems on multi-step reasoning and explanations in natural language.
Entailment Tree Explanations via Iterative Retrieval-Generation Reasoner
May 18, 2022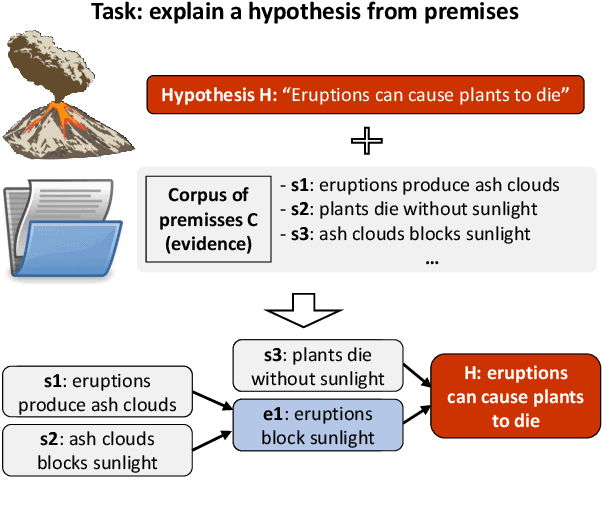
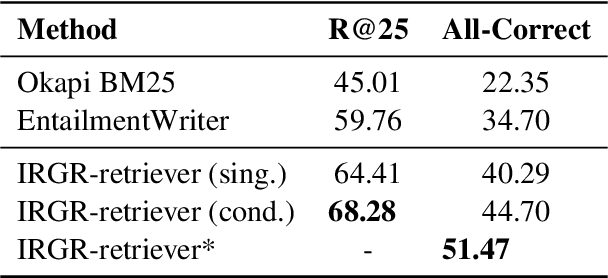
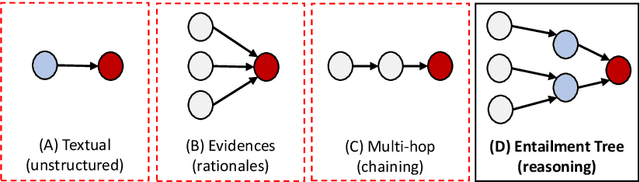
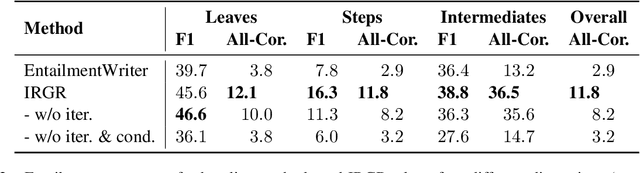
Large language models have achieved high performance on various question answering (QA) benchmarks, but the explainability of their output remains elusive. Structured explanations, called entailment trees, were recently suggested as a way to explain and inspect a QA system's answer. In order to better generate such entailment trees, we propose an architecture called Iterative Retrieval-Generation Reasoner (IRGR). Our model is able to explain a given hypothesis by systematically generating a step-by-step explanation from textual premises. The IRGR model iteratively searches for suitable premises, constructing a single entailment step at a time. Contrary to previous approaches, our method combines generation steps and retrieval of premises, allowing the model to leverage intermediate conclusions, and mitigating the input size limit of baseline encoder-decoder models. We conduct experiments using the EntailmentBank dataset, where we outperform existing benchmarks on premise retrieval and entailment tree generation, with around 300% gain in overall correctness.